RePro: Leveraging Large Language Models for Semi-Automated Reproduction of Networking Research Results
Abstract: Reproducing networking research is a critical but challenging task due to the scarcity of open-source code. While LLMs can automate code generation, current approaches lack the generalizability required for the diverse networking field. To address this, we propose RePro, a semi-automated reproduction framework that leverages advanced prompt engineering to reproduce network systems from their research papers. RePro combines few-shot in-context learning with Structured and Semantic Chain of Thought (SCoT/SeCoT) techniques to systematically translate a paper's description into an optimized, executable implementation. The framework operates through a three-stage pipeline: system description extraction, structural code generation, and code optimization. Our evaluation with five state-of-the-art LLMs across diverse network sub-domains demonstrates that RePro significantly reduces reproduction time compared to manual efforts while achieving comparable system performance, validating its effectiveness and efficiency.








Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces RePro, a smart tool that uses LLMs to help recreate the results of computer networking research papers when the original code isn’t available. Think of it like rebuilding a complex machine using only a detailed magazine article. RePro reads the paper, plans how the system should work, writes the code in pieces, and then fixes mistakes—much faster than a person doing it all by hand.
What questions does the paper try to answer?
The paper focuses on simple, practical questions:
- Can we use LLMs to turn networking research papers into working code, even when authors don’t share their programs?
- Can this be done across many different kinds of networking systems (like traffic control, verification, or congestion control)?
- Can this approach save time while keeping the reproduced system accurate and reliable?
How did the researchers do it?
The team built a step-by-step framework called RePro that guides an LLM from understanding a paper to producing working code. Here’s how it works, explained with everyday ideas:
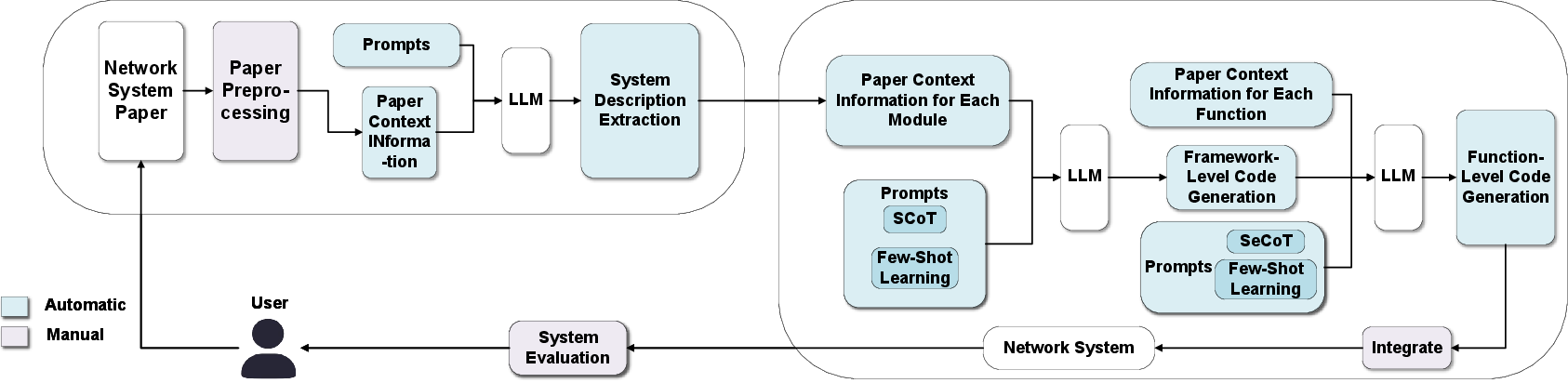
Step 1: Understand the paper (System Description Extraction)
RePro first “reads” the paper in a structured way. It splits the paper into parts like Introduction, Design, and Evaluation, and also looks at figures, tables, and formulas. It then extracts the basics:
- What problem the system solves
- What the system takes in (inputs) and produces (outputs)
- What major parts (modules) make up the system
Analogy: It’s like reading a recipe and listing out the ingredients, cooking steps, and tools before you start cooking.
Step 2: Build the skeleton of the code (Framework-Level Code Generation)
RePro maps the paper into a high-level code structure using Structured Chain of Thought (SCoT). SCoT is a way to plan the program like a flowchart using just three core ideas:
- Sequential steps (do A, then B, then C)
- Conditional checks (if X happens, do Y)
- Loops (repeat something until it’s done)
It then creates a code “skeleton”: function names, inputs, outputs, and placeholder content. It also links each function to the exact lines or sections from the paper so the code stays true to the original design.
Analogy: This is like sketching the rooms in a house (kitchen, bedroom, bathroom) and labeling doors and windows before adding furniture.
Step 3: Fill in the details (Function-Level Code Generation)
Next, RePro uses Semantic Chain of Thought (SeCoT) to write the actual code inside each function. SeCoT makes the model think carefully about:
- Data flow: how information moves from one step to another
- Control flow: the order of operations and decisions
RePro shows the LLM a few examples (few-shot learning) of “requirement → plan → code” so it learns the pattern. Then the LLM writes each function’s code with proper inputs/outputs and edge-case handling.
Analogy: Now you actually cook the dish, following the step-by-step plan, while keeping track of ingredients and timing.
Step 4: Test and fix problems (Code Optimization)
Finally, RePro runs tests and fixes errors:
- Syntax errors: simple mistakes that stop the code from running (like missing a semicolon)
- Semantic errors: the code runs but doesn’t do the right thing (like mixing up units)
RePro uses a feedback loop: it feeds the error messages back to the LLM and asks it to correct the code. If needed, a human can guide the LLM with precise hints.
Analogy: You taste the dish and adjust the salt or cooking time until it matches the recipe’s description.
Helpful terms explained simply
- LLM: A very smart AI that can read and write text, including code. It’s like a super-helpful assistant who can follow instructions.
- Prompt engineering: Writing clear, structured instructions for the LLM so it knows exactly what to do—like giving it a checklist.
- Few-shot learning: Showing the LLM a few examples so it understands the pattern without retraining.
- SCoT and SeCoT: Ways to make the LLM think step-by-step, first at a high level (SCoT) and then with code-level details (SeCoT).
What did they find?
The researchers tested RePro using several different LLMs and across multiple kinds of networking systems (like traffic engineering, verification, and congestion control). Key results:
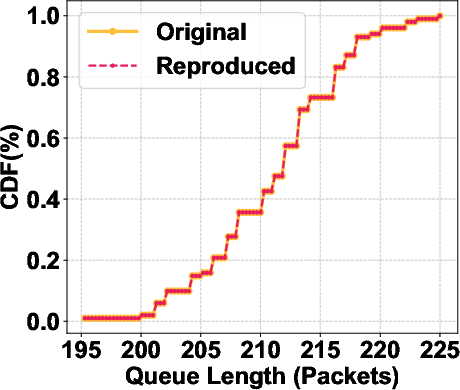
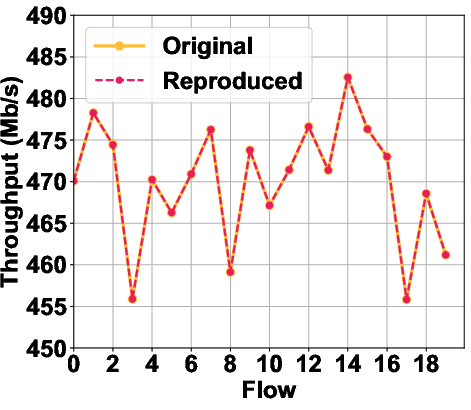
- RePro produced working systems that performed similarly to the original open-source versions.
- It reduced the time needed to reproduce a system compared to doing it all manually.
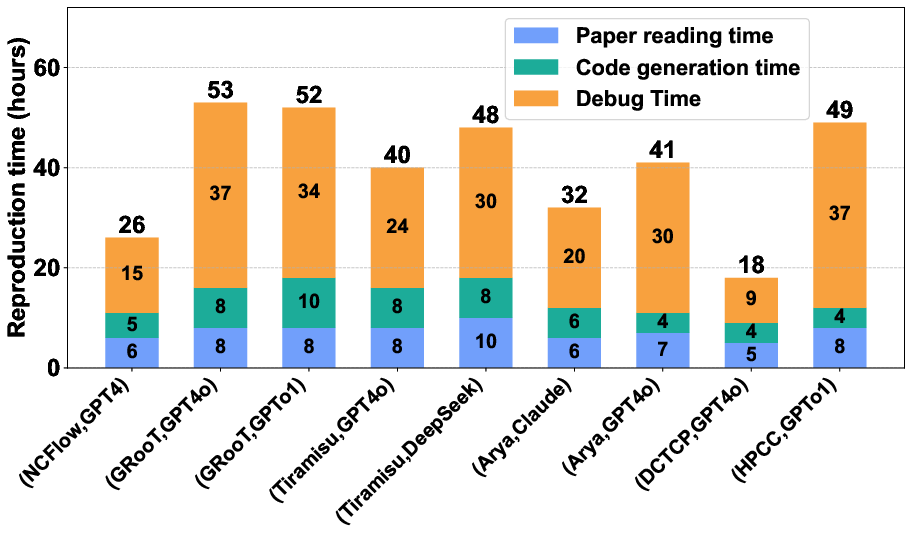
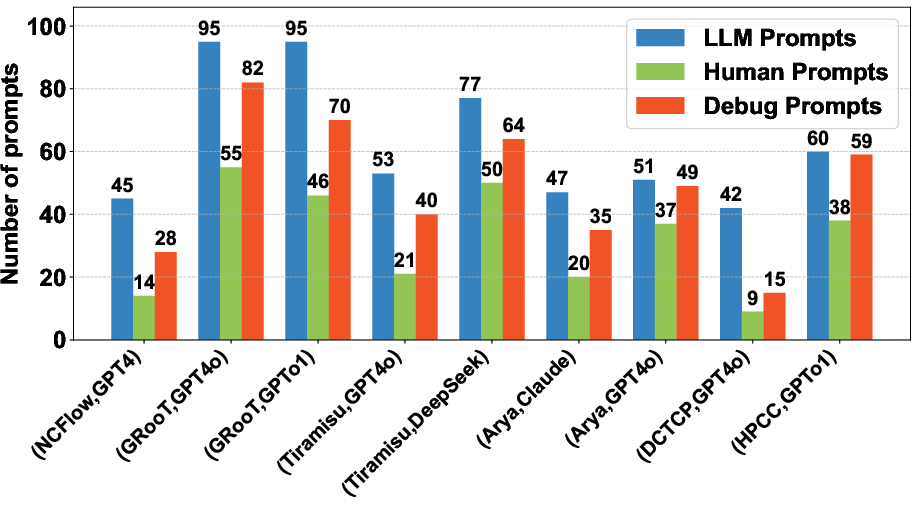
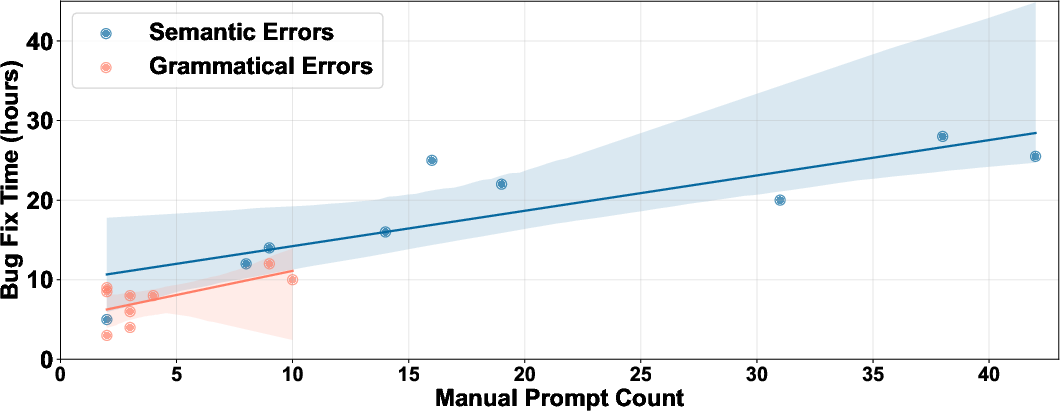
- On average, reproductions took about 38.6 hours and only needed around 32.2 manual prompts, showing it’s both faster and easier to use than unstructured LLM chats.
- It worked across diverse programming languages and system types, showing good generality.
Why this matters: Networking systems are complex, and many papers don’t share code. RePro makes it much easier and faster to rebuild these systems accurately.
What’s the impact and why does it matter?
- For researchers: Faster, more reliable reproduction builds trust in published results and helps teams compare their new ideas against older ones without spending weeks coding.
- For students and engineers: It lowers the barrier to learning from advanced papers—more people can understand and try out cutting-edge ideas.
- For industry: Companies can test academic ideas quickly before investing in them, leading to better products and networks.
Overall, RePro shows that LLMs, when guided carefully with well-designed prompts and step-by-step planning, can turn complex research papers into working systems. This could speed up innovation in computer networking and make research more transparent and repeatable.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, intended to guide future research.
- Benchmark breadth and representativeness: Evaluate RePro on a substantially larger and more diverse set of networking systems (e.g., SDN controllers, P4/NIC offload, kernel modules, wireless/IoT protocols, NFV, measurement/telemetry) beyond the six open-source projects used, to assess generalizability across heterogeneous architectures and toolchains.
- Closed-source target validation: Since evaluation relies on systems with available open-source baselines, test RePro on papers without released code (the stated motivation) and define rigorous external validation criteria (functional specs, performance envelopes, reproducibility of experiments) when ground-truth implementations are unavailable.
- Environment reproducibility: Systematically address environment provisioning (OS, compilers, build systems such as CMake/Bazel, dependencies, NS-3/Mininet versioning, hardware-specific settings) and quantify its impact on fidelity and time-to-reproduction; integrate containerized or declarative environment capture (e.g., Docker/Conda) into RePro.
- Multimodal paper parsing robustness: Provide a concrete, tested pipeline for parsing figures/tables/pseudocode/LaTeX (OCR, layout-aware PDF parsing, diagram-to-structure extraction) and quantify accuracy gains vs text-only inputs; measure failure modes when critical details are encoded in diagrams.
- Mapping fidelity from paper to code: Validate the “ORIGINAL TEXT” ↔ [REQUIREMENT] mapping with human annotation (e.g., inter-annotator agreement), measure misalignment rates, and develop automatic checks (consistency constraints, semantic similarity thresholds) to prevent hallucinations or incorrect transcriptions.
- Effectiveness of SCoT/SeCoT: Conduct controlled ablations comparing SCoT/SeCoT against strong baseline prompts (direct CoT, program-of-thought, tool-augmented approaches) and report improvements in correctness, error rate, human prompts, and runtime.
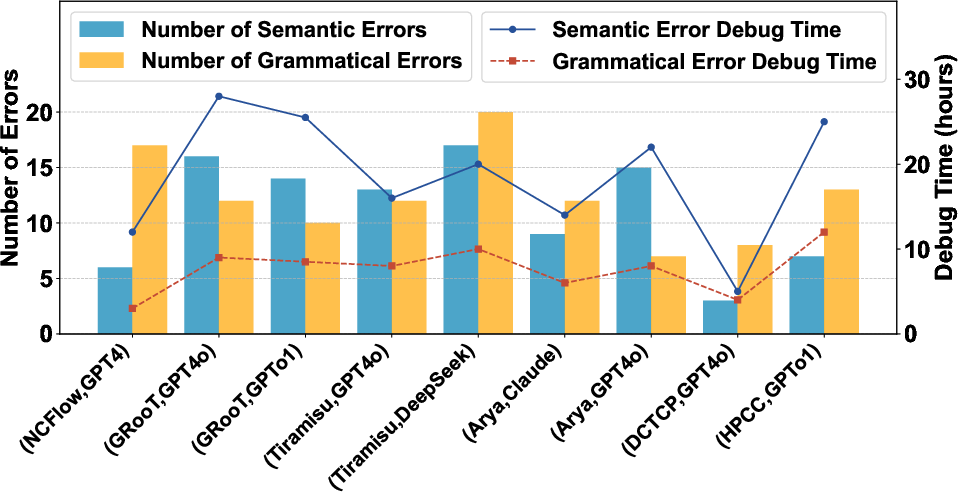
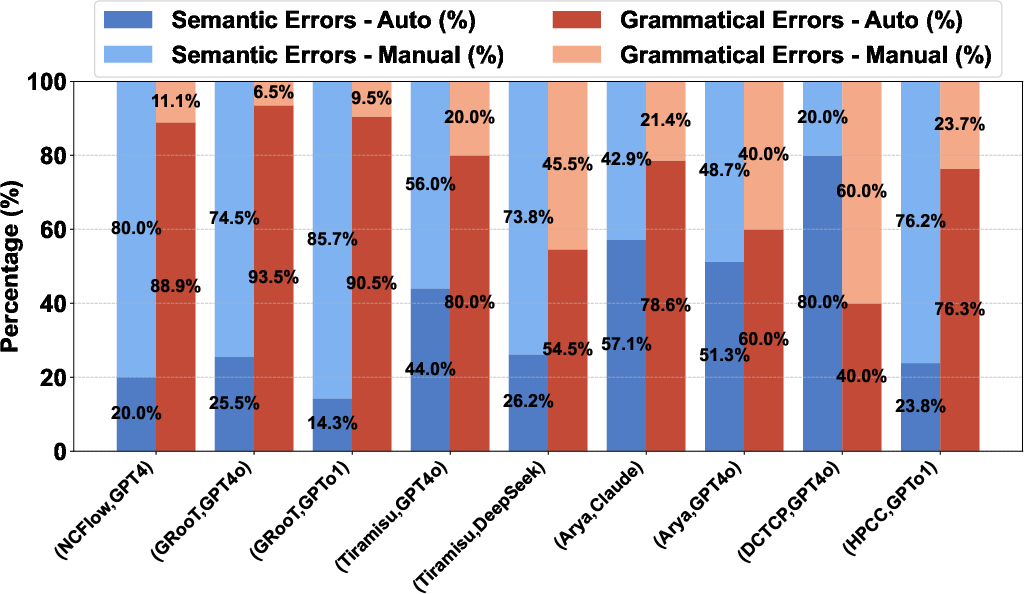
- Error taxonomy and repair metrics: Quantify syntax vs semantic error distributions, time-to-fix, and success rates across modules; analyze common failure patterns and root causes to inform prompt/template improvements and automated detectors.
- Test generation quality: Evaluate generated tests for coverage (statement/branch/path), fault-detection power (e.g., mutation testing), and alignment with paper-defined metrics; address how RePro handles papers with sparse or ambiguous evaluation descriptions.
- Performance fidelity and micro-optimizations: Beyond functional parity, measure deviations in throughput/latency/jitter/CPU/memory; assess sensitivity to environment/config changes and document how RePro handles micro-optimizations and system tuning detailed in papers.
- Human effort characterization: Precisely quantify required expertise, cognitive load, and time per stage (reading, generation, debugging); compare to manual reproduction and alternative LLM-assisted baselines to establish fair cost-benefit analyses.
- Cost and resource reporting: Report token usage, API costs, compute/latency, and energy consumption per reproduction; study cost-quality trade-offs across LLMs and prompt strategies.
- LLM selection impact: Provide systematic comparisons across models (context window, output-token limits, multimodality, open-source vs closed) with statistically robust metrics; clarify how vision capabilities are used and when text-only models suffice.
- Tooling confounds: The use of external tools (e.g., Cursor for DCTCP/HPCC) introduces confounding variables; isolate and measure their contribution vs RePro alone, or formally integrate tooling as a reproducible component of the framework.
- Scalability to large systems: Assess RePro’s performance on multi-repo, microservice-based, distributed systems with concurrency, asynchronous communication, and complex integration tests; develop strategies for module graph management and incremental integration.
- Formal correctness and verification: Explore integrating static analysis, model checking, property-based testing, and domain verifiers (e.g., for control-plane correctness, protocol invariants) to move beyond test-only validation.
- Handling missing/ambiguous paper details: Define systematic strategies (cross-referencing sections, auxiliary literature retrieval, author correspondence, standards/RFC mining) and quantify success when papers lack explicit algorithmic or setup details.
- Security and safety of generated code: Assess vulnerability risks (injection, unsafe resource handling, memory errors), propose secure-by-default templates, licensing compliance checks, and IP/patent considerations for reproducing proprietary systems.
- Prompt/template reproducibility: Release the full prompt library, templates, and workflows as artifacts; define versioning and evaluation harnesses to ensure third-party reproducibility and reduce variability due to ad-hoc prompt adjustments.
- Retrieval augmentation design: Specify and evaluate retrieval strategies (section-level indexing, semantic chunking, citation graph traversal) and their impact on correctness and prompt length management; compare against long-context-only approaches.
- Autonomy vs human-in-the-loop: Investigate how to reduce the average 32.2 manual prompts (agents, planning, automatic error triage) and measure trade-offs in correctness and time; characterize tasks that still critically require expert intervention.
- Cross-language and build-system diversity: Evaluate language-specific challenges (C/C++ memory management, Java ecosystems, Python packaging), compiler warnings, linkers, and runtime differences; provide language- and toolchain-specific templates and best practices.
- Non-English and domain-specific writing: Test RePro on non-English papers and documents heavy in domain-specific jargon/abbreviations; measure parsing accuracy and propose multilingual preprocessing.
- Fair comparison to prior work: Establish standardized benchmarks to compare against LASER and direct prompt-heavy methods under matched tasks; report statistical significance and effect sizes for time savings and accuracy.
- Completeness of evaluation reporting: The current evaluation details are incomplete (e.g., truncated tables); publish full results, configurations, datasets, and scripts to enable independent verification.
- Governance and data policy: Clarify legal/ethical handling of paywalled or proprietary papers ingested by LLMs, data retention policies, and compliance with publisher terms and institutional review requirements.
Practical Applications
Overview
The paper proposes RePro, a semi-automated framework that uses advanced prompt engineering with LLMs—specifically Structured Chain of Thought (SCoT), Semantic Chain of Thought (SeCoT), and few-shot in-context learning—to reproduce networking systems from research papers. It operates in a pipeline that parses heterogeneous, multimodal papers; generates modular, framework-level code; fills in function-level implementations guided by data/control flow semantics; and iteratively corrects and optimizes code via compiler/runtime feedback. Evaluations across diverse networking sub-domains (TE, protocols, verification, graph mining) show substantial time savings with comparable performance to original open-source systems.
The applications below translate RePro’s findings and methods into actionable use cases across industry, academia, policy, and daily life. Each item highlights relevant sectors, potential tools/products/workflows, and feasibility considerations.
Immediate Applications
The following applications are deployable now with current LLMs and existing engineering practices.
- Rapid reproduction and benchmarking of networking algorithms for R&D
- Sectors: telecom, cloud providers, networking vendors, software
- What: Use RePro to rebuild and compare congestion control (DCTCP/HPCC), traffic engineering (NCFlow), DNS/control-plane verification (GRooT/Tiramisu), and graph mining (Arya) prototypes for internal evaluations, A/B tests, and algorithm selection.
- Tools/workflows: RePro prompt templates; multimodal paper ingestion; NS-3 simulations; Gurobi-backed solvers; automated test harness generation; CI jobs to run reproduced experiments.
- Assumptions/dependencies: Access to detailed papers; LLMs with large context windows; licenses for proprietary tools (e.g., Gurobi); domain data; human-in-the-loop for semantic fidelity.
- Procurement and vendor claim verification
- Sectors: enterprise IT, telecom operators, public sector
- What: Reproduce vendor whitepapers and claims into executable prototypes to validate promised performance/features before purchase.
- Tools/workflows: Paper-to-code pipelines; standardized benchmarking suites; reproducibility reports integrated into procurement processes.
- Assumptions/dependencies: Sufficient paper detail; non-proprietary implementation feasibility; testbed availability; legal clarity on reproducing proprietary designs.
- Teaching and course labs for networking and systems
- Sectors: academia, education
- What: Students use RePro to replicate top-tier papers as assignments, lowering the barrier to hands-on learning and enabling reproducibility-focused curricula.
- Tools/workflows: LMS/IDE plugins; curated paper sets; auto-generated scaffolds and tests; grading rubrics tied to performance metrics.
- Assumptions/dependencies: Stable LLM access; institutional policies on AI use; computing resources for simulations; instructor oversight.
- Peer review and artifact evaluation support
- Sectors: academic publishing, conference committees
- What: Program committees and reproducibility chairs employ RePro to quickly detect missing details, assess implementation clarity, and request targeted clarifications.
- Tools/workflows: Reviewer dashboards; auto-generated code skeletons annotated with [ORIGINAL TEXT] mappings; artifact badge workflows.
- Assumptions/dependencies: Reviewer training; permissive scrutiny of paper content; time constraints; model reliability.
- Documentation, traceability, and compliance
- Sectors: software engineering, regulated industries
- What: Map paper excerpts directly into code comments ([REQUIREMENT]/[ORIGINAL TEXT]) to enhance traceability, onboarding, and compliance audits.
- Tools/workflows: Code-comment generators; repository templates; internal compliance checklists.
- Assumptions/dependencies: Clear paper-to-code mapping; maintenance of annotations; adherence to documentation standards.
- Automated test harness generation for protocols and systems
- Sectors: networking, QA/Testing
- What: Use SeCoT-guided reasoning to generate unit/integration tests and NS-3 scenarios from paper requirements, improving QA coverage and regression detection.
- Tools/workflows: Test generators integrated with CI; scenario libraries; coverage dashboards.
- Assumptions/dependencies: Accurate requirement extraction; deterministic test setups; CI resources.
- LLM-driven bug triage and iterative optimization
- Sectors: DevOps, software tooling
- What: Feed compiler/runtime errors back to LLMs to automatically correct syntax/semantic issues, shortening debugging cycles.
- Tools/workflows: CI hooks; ChatOps pipelines; error-report parsers; guardrail prompts.
- Assumptions/dependencies: High-quality error messages; safety filters; human review of logic changes.
- IDE and agent plugins for “paper-to-code”
- Sectors: software tools, developer productivity
- What: Build VSCode/Cursor plugins that ingest PDFs and output structured, modular code frameworks with tests and annotations.
- Tools/workflows: PDF parsers; multimodal LLM APIs; prompt libraries; repository initializers.
- Assumptions/dependencies: Reliable PDF parsing; model multimodality; licensing and rate limits.
- Structured metadata extraction for research knowledge bases
- Sectors: information services, academic libraries
- What: Extract domain, problem statements, I/O, architecture, and module dependencies to index papers for search and discovery.
- Tools/workflows: Metadata pipelines; JSON schema validators; retrieval-augmented search.
- Assumptions/dependencies: Consistent sectioning and content quality; scalable ingestion.
- Faster open-source contributions and hackathons
- Sectors: open-source, developer communities
- What: Developers quickly generate runnable demos of networking ideas, accelerating experimentation and contributions.
- Tools/workflows: Starter repositories; community templates; reproducibility tags.
- Assumptions/dependencies: Community guidelines on AI-generated code; maintainers’ acceptance; quality assurance.
Long-Term Applications
The following applications require further research, scaling, standardization, or integration to become robust and broadly deployable.
- Digital twin verification for production networks
- Sectors: telecom, cloud networking
- What: Continuously reproduce, simulate, and validate control/transport algorithms before deployment using digital twins fed by RePro-generated prototypes.
- Tools/workflows: Live-in-the-loop simulations; telemetry-driven model calibration; automated rollout gates.
- Assumptions/dependencies: High-fidelity twin models; robust paper-to-simulation mapping; organizational buy-in and governance.
- Regulatory and policy auditing of network management algorithms
- Sectors: public policy, regulatory agencies
- What: Regulators reproduce algorithmic claims (e.g., fairness, neutrality, resilience) to audit compliance in ISPs and critical infrastructure.
- Tools/workflows: Policy-aligned test suites; reproducibility dossiers; third-party audit standards.
- Assumptions/dependencies: Legal frameworks; access to detailed specifications; neutrality of audit tools; standardized metrics.
- Cross-domain expansion to cybersecurity, distributed systems, IoT, robotics
- Sectors: multi-domain engineering
- What: Generalize RePro’s SCoT/SeCoT methodology to reproduce complex systems beyond networking, including threat detection pipelines, consensus protocols, and robot control stacks.
- Tools/workflows: Domain-specific prompt libraries; multimodal parsing of diagrams/specs; simulation integrations (e.g., ROS).
- Assumptions/dependencies: Domain benchmarks; varied toolchains; broader model training with domain code and semantics.
- Standardized authoring to enable auto-reproduction
- Sectors: academia, publishing
- What: Conferences/journals adopt structured templates (module schemas, I/O specs, SCoT/SeCoT artifacts) to make papers machine-actionable for reproduction.
- Tools/workflows: Publication checkers; templated LaTeX/Markdown; artifact badges tied to auto-generated code.
- Assumptions/dependencies: Community consensus; author incentives; tooling integration in submission workflows.
- Curated, continuously updated repositories of reproduced systems
- Sectors: research platforms, benchmarking
- What: Maintain an open repository of auto-reproduced networking systems with standardized metrics and scenarios for meta-analyses and rapid comparison.
- Tools/workflows: Versioned benchmarks; provenance tracking; automated refresh with new papers.
- Assumptions/dependencies: Sustainable maintenance; licensing compliance; governance and quality control.
- Automated migration and modernization (e.g., C/C++ to Rust)
- Sectors: software modernization, security
- What: Use paper-grounded reproduction to reimplement networking code in safer languages/frameworks, reducing memory-safety risks.
- Tools/workflows: Language-agnostic SeCoT; migration guides; formal verification hooks.
- Assumptions/dependencies: Mature target ecosystems; performance parity; validation of correctness under real workloads.
- Integration with CI/CD as a reproducibility gate
- Sectors: DevOps, QA
- What: PRs and releases include auto-generated reproduction tests; changes to key algorithms require simulation-based validation before merge.
- Tools/workflows: CI pipelines; policy-as-code; reproducibility badges in repos.
- Assumptions/dependencies: Engineering culture; compute budgets; stable test environments.
- Specialized LLMs trained on networking reproduction corpora
- Sectors: AI/ML, tooling vendors
- What: Train domain-specific models with SCoT/SeCoT exemplars, improving precision, reducing hallucinations, and expanding multimodal comprehension.
- Tools/workflows: Curated datasets; evaluation harnesses; safety filters; open benchmarks.
- Assumptions/dependencies: Access to high-quality training data; compute resources; responsible use policies.
- Patent/whitepaper prior-art reconstruction and legal analytics
- Sectors: legal tech, IP management
- What: Systematically reproduce patented or claimed algorithms to assess novelty, scope, and infringement risks.
- Tools/workflows: Litigation-grade reproducibility reports; similarity analyses; evidentiary chains.
- Assumptions/dependencies: Legal permissions; robust equivalence metrics; expert validation.
- Scalable education platforms for “paper-to-lab”
- Sectors: EdTech, MOOCs
- What: Students submit papers and receive auto-generated labs with runnable experiments and rubric-based grading tied to performance.
- Tools/workflows: LMS integrations; secure sandboxing; plagiarism/AI policy enforcement.
- Assumptions/dependencies: Institutional adoption; reliable infrastructure; pedagogical alignment.
- End-user gains via faster adoption of performant protocols
- Sectors: consumer internet, enterprise networks
- What: Accelerated reproduction and validation pipelines shorten the path from research to deployment (e.g., better congestion control), improving real-world performance.
- Tools/workflows: Vendor integration pipelines; staged rollouts; telemetry feedback loops.
- Assumptions/dependencies: Productionization effort; interoperability; risk management.
Notes on Feasibility
Common dependencies across applications include access to high-quality, detailed papers; LLMs with large context windows and multimodal capabilities; licenses for external solvers/simulators (e.g., Gurobi, NS-3); robust PDF parsing; human-in-the-loop validation of semantics; organizational buy-in; and clear legal/ethical policies regarding reproduction of proprietary designs. The framework’s effectiveness is sensitive to paper clarity, model capability, and the availability of domain-specific tooling and datasets.
Glossary
- Autoregressive models: Neural sequence models that generate tokens by conditioning on previously generated context; commonly used for generative text and code tasks. "prefix prompts~\cite{lester2021power} prepend instructions for autoregressive models like GPT."
- Chain-of-Thought (CoT): A prompting technique that elicits step-by-step reasoning from LLMs to solve complex tasks more reliably. "Chain-of-Thought (CoT) prompting~\cite{wei2022chain} is an in-context learning technique that enhances the problem-solving capabilities of LLMs by decomposing complex tasks into intermediate reasoning steps."
- Cloze prompts: Fill-in-the-blank templates designed for masked LLMs to elicit specific knowledge or completions. "Cloze prompts~\cite{cui2021template,petroni2019language} use a fill-in-the-blank format for masked LMs like BERT~\cite{devlin2019bert}, while prefix prompts~\cite{lester2021power} prepend instructions for autoregressive models like GPT."
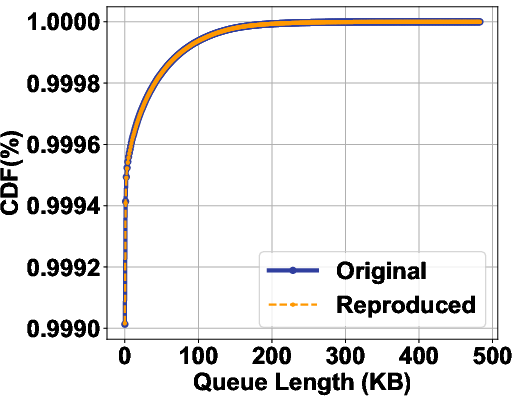
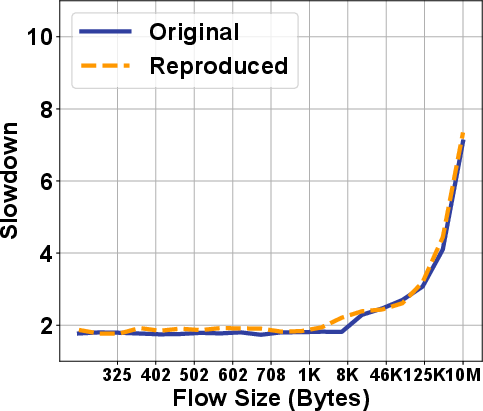
- Congestion control: Techniques and algorithms that manage network traffic sending rates to prevent congestion and packet loss. "These papers cover several influential research areas, including traffic engineering (NCFlow), graph pattern mining (Arya), transport-layer protocols (DCTCP), DNS verification (GRooT), control-plane verification (Tiramisu), and congestion control algorithms (HPCC)."
- Context window: The maximum amount of input tokens an LLM can consider at once, affecting its ability to process long documents. "A larger context window confers a significant advantage in processing extensive documents."
- Control flow: The order and structure of execution in a program (e.g., sequencing, branching, looping). "SCoT ~\cite{li2025structured} utilizes natural language reasoning steps in a pseudo-code format to describe the program's control flow, guiding the model to generate a logically coherent framework."
- Control-plane verification: Methods to ensure the correctness and safety of a network’s control-plane logic and policies. "These papers cover several influential research areas, including traffic engineering (NCFlow), graph pattern mining (Arya), transport-layer protocols (DCTCP), DNS verification (GRooT), control-plane verification (Tiramisu), and congestion control algorithms (HPCC)."
- Data flow: The movement and transformation of data through variables and functions within a program. "We apply the Semantic Chain-of-Thought (SeCoT) method, which incorporates control and data flow, to structure the model's output."
- DCTCP: Data Center TCP, a transport protocol variant optimized for datacenter networks using ECN for fine-grained congestion feedback. "For DCTCP and HPCC, we use Cursor~\cite{cursor} to facilitate error correction."
- DNS verification: Techniques to validate the correctness and security properties of DNS configurations and behavior. "These papers cover several influential research areas, including traffic engineering (NCFlow), graph pattern mining (Arya), transport-layer protocols (DCTCP), DNS verification (GRooT), control-plane verification (Tiramisu), and congestion control algorithms (HPCC)."
- Few-shot learning: Adapting an LLM to a task by providing a small number of input-output examples within the prompt instead of training. "For each function, we employ a few-shot learning approach, providing the LLM with examples that map requirement descriptions to their corresponding code implementations."
- Graph pattern mining: Discovering frequent or significant subgraph patterns within large graphs, often for analytics or optimization. "These papers cover several influential research areas, including traffic engineering (NCFlow), graph pattern mining (Arya), transport-layer protocols (DCTCP), DNS verification (GRooT), control-plane verification (Tiramisu), and congestion control algorithms (HPCC)."
- Gurobi Solver: A commercial optimization solver widely used for linear and integer programming. "Gurobi Solver"
- HPCC: High Precision Congestion Control, a congestion control scheme emphasizing precise in-network feedback for high throughput and low latency. "For DCTCP and HPCC, we use Cursor~\cite{cursor} to facilitate error correction."
- Human-in-the-Loop: A workflow where human guidance or oversight is integrated with automated processes to improve correctness or safety. "Human-in-the-Loop: We first manually identify the precise error location and perform a root cause analysis."
- In-Context Learning: The ability of LLMs to infer task behavior from instructions and a few examples in the prompt without parameter updates. "In-context learning enables LLMs to adapt to new tasks without parameter updates, relying solely on task descriptions and a few examples within the input prompt."
- LLMs: Large-scale neural models trained on vast text corpora capable of natural language understanding and generation, often used for code. "While LLMs can automate code generation, current approaches lack the generalizability required for the diverse networking field."
- Linearization: Converting structured data (e.g., trees, tables) into a sequential textual form suitable for LLM input. "Structured data (e.g., trees, tables) is often transformed via linearization~\cite{jiang2023structgpt} or code-based representations~\cite{beurer2023prompting} to facilitate model ingestion."
- Low Earth Orbit (LEO) satellite networks: Communication networks using satellites in low Earth orbit, with unique mobility and topology characteristics. "LASER was introduced as a semi-automated, LLM-assisted framework for experiment reproduction, but its application is currently limited to the specific domain of Low Earth Orbit (LEO) satellite networks~\cite{wang2025llm}."
- Masked LMs: LLMs trained to predict masked tokens in an input sequence (e.g., BERT), used with cloze-style prompts. "Cloze prompts~\cite{cui2021template,petroni2019language} use a fill-in-the-blank format for masked LMs like BERT~\cite{devlin2019bert}, while prefix prompts~\cite{lester2021power} prepend instructions for autoregressive models like GPT."
- Multimodal LLM: An LLM capable of processing and reasoning over multiple input modalities such as text and images. "Figures and Tables: Processed directly in their native visual formats by the multimodal LLM."
- NS-3: A discrete-event network simulator used for research and evaluation of network protocols and systems. "NS-3"
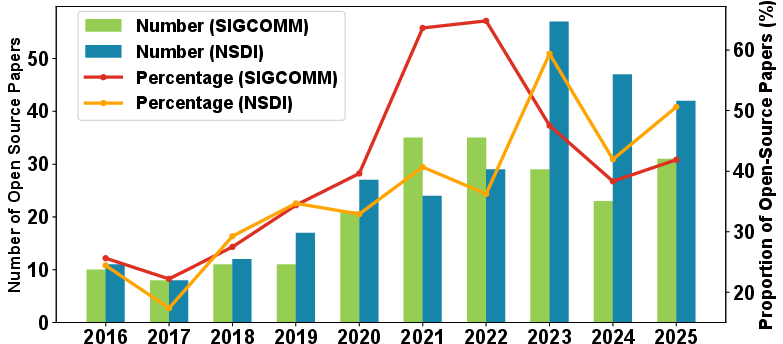
- NSDI: USENIX Symposium on Networked Systems Design and Implementation, a top-tier systems and networking conference. "even in top-tier conferences such as SIGCOMM and NSDI"
- Output token limit: The maximum number of tokens an LLM can generate in a single response, constraining output completeness. "The output token limit is a critical determinant of a model's generative capacity, directly influencing the completeness of the resulting code."
- Paper-to-code generation: Automated translation of academic paper content into executable code using LLMs. "recent advances in paper-to-code generation~\cite{seo2025paper2code,lin2025autop2c,luo2025intention} have shown promising results in machine learning and biomedical domains"
- Prefix prompts: Instructional prefixes prepended to inputs to steer autoregressive models’ behavior. "Cloze prompts~\cite{cui2021template,petroni2019language} use a fill-in-the-blank format for masked LMs like BERT~\cite{devlin2019bert}, while prefix prompts~\cite{lester2021power} prepend instructions for autoregressive models like GPT."
- Program analysis: Systematic techniques to analyze and reason about program behavior and structure. "This process integrates principles from program analysis with advanced prompt engineering techniques, notably Structured Chain-of-Thought (SCoT) and In-Context Learning (ICL)."
- Prompt Engineering (PE): Designing and structuring prompts to guide LLMs toward accurate understanding and high-quality outputs. "Prompt Engineering (PE)~\cite{gu2023systematic} involves designing effective prompts to guide an LLM toward accurate task comprehension and high-quality output generation."
- Request for Comments (RFC) documents: Formal technical documents (primarily from the IETF) that specify protocols, procedures, and policies for the internet. "such as network configurations and RFC documents"
- Retrieval-augmented approach: A technique that augments prompts with retrieved, relevant context to ground model outputs. "This retrieval-augmented approach grounds the LLM, allowing it to discern relationships between document sections and efficiently pinpoint necessary information."
- Role-playing: A prompting style that assigns roles or personas to the model to influence reasoning and output style. "Techniques like direct instruction, question-based framing, or role-playing~\cite{chen2023chatcot} can influence output coherence, especially for complex, multi-step tasks."
- SCoT (Structured Chain of Thought): A CoT variant that structures reasoning like pseudo-code with explicit control structures and interfaces. "SCoT ~\cite{li2025structured} utilizes natural language reasoning steps in a pseudo-code format to describe the program's control flow, guiding the model to generate a logically coherent framework."
- SeCoT (Semantic Chain of Thought): A CoT variant that incorporates program semantics (data and control flow) into stepwise reasoning for code generation. "We apply the Semantic Chain-of-Thought (SeCoT) method, which incorporates control and data flow, to structure the model's output."
- SIGCOMM: ACM’s flagship conference on communications and computer networks. "even in top-tier conferences such as SIGCOMM and NSDI"
- Stack traces: Call-stack records produced on errors to help locate sources of runtime failures. "including stack traces, exception types, and specific messages"
- Structured program theorem: The Böhm–Jacopini result stating any computable function can be implemented using sequence, selection, and iteration. "Motivated by the structured program theorem~\cite{bohm1966flow}, which establishes that any computable function can be implemented using only sequential, conditional, and iterative control structures"
- Test-Driven: A debugging strategy that uses expected input-output pairs (tests) to guide model self-correction. "Test-Driven: To facilitate self-correction, the LLM is prompted with the expected input-output pairs and functional requirements, effectively providing it with a test case to validate its generation."
- Traffic engineering: Optimizing the flow of traffic across a network to meet performance objectives under constraints. "These papers cover several influential research areas, including traffic engineering (NCFlow), graph pattern mining (Arya), transport-layer protocols (DCTCP), DNS verification (GRooT), control-plane verification (Tiramisu), and congestion control algorithms (HPCC)."
- Transport-layer protocols: Communication protocols operating at the transport layer (e.g., TCP), providing end-to-end data transfer services. "These papers cover several influential research areas, including traffic engineering (NCFlow), graph pattern mining (Arya), transport-layer protocols (DCTCP), DNS verification (GRooT), control-plane verification (Tiramisu), and congestion control algorithms (HPCC)."
Collections
Sign up for free to add this paper to one or more collections.