Beyond Language Barriers: Multi-Agent Coordination for Multi-Language Code Generation
Abstract: Producing high-quality code across multiple programming languages is increasingly important as today's software systems are built on heterogeneous stacks. LLMs have advanced the state of automated programming, yet their proficiency varies sharply between languages, especially those with limited training data such as Rust, Perl, OCaml, and Erlang. Many current solutions including language-specific fine-tuning, multi-agent orchestration, transfer learning, and intermediate-representation pipelines still approach each target language in isolation, missing opportunities to share knowledge or exploit recurring cross-language patterns. XL-CoGen tackles this challenge with a coordinated multi-agent architecture that integrates intermediate representation, code generation, translation, and automated repair. Its distinguishing feature is a data-driven mechanism for selecting bridging languages: empirically derived transfer matrices identify the best intermediate languages based on demonstrated translation success rather than raw generation accuracy. The system performs early output validation, iteratively corrects errors, and reuses intermediate artifacts as contextual scaffolds for subsequent translations. Extensive experiments show that XL-CoGen yields notable improvements with 13 percentage-point gains over the strongest fine-tuned baseline and as much as 30 percentage points over existing single-language multi-agent methods. Ablation studies further demonstrate that compatibility-guided bridging significantly outperforms LLM-based heuristics, confirming the value of cumulative cross-language knowledge transfer.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching AI to write code well in many different programming languages. Today’s AIs are great at popular languages like Python and JavaScript, but they struggle with less common ones like Rust, Perl, OCaml, and Erlang. The authors built a system called XL-CoGen that helps the AI “team up” across languages: it first tries to solve a problem in the target language, then uses a smart “bridge” language to translate and improve the solution, and finally fixes any remaining errors. The goal is to break language barriers so the AI can produce reliable code no matter which language you want.
The big questions
The paper tries to answer three simple questions:
- Can XL-CoGen make AI better at writing code in many different programming languages?
- Is XL-CoGen better than training a special AI just for one language (like fine-tuning a model only for Rust)?
- Which parts of XL-CoGen matter most for improving results?
How the system works
Think of XL-CoGen like a careful, three-step building process with a plan, a helpful translator, and a repair crew.
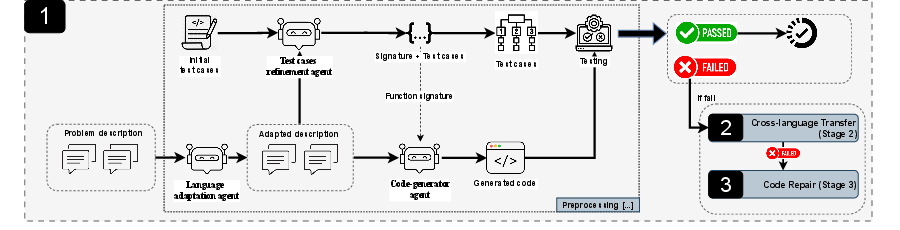
Stage 1: Build and test a first version
The AI reads a clear problem description and writes code in the target language (for example, Rust). It then runs tests to see if the code works. If the tests pass, great—we’re done. If not, we go to the next stage.
- “Validation” means running tests to check if the code does what it’s supposed to do, like checking if a calculator app gives the right answers.
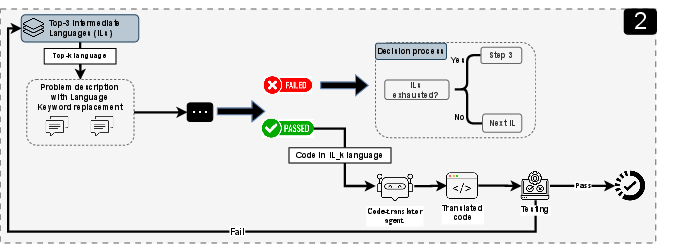
Stage 2: Use a “bridge language” to help
If the first try fails, the system uses a bridge language where the AI is stronger (for example, Python or Scala) to produce a working version, then translates that code back into the target language.
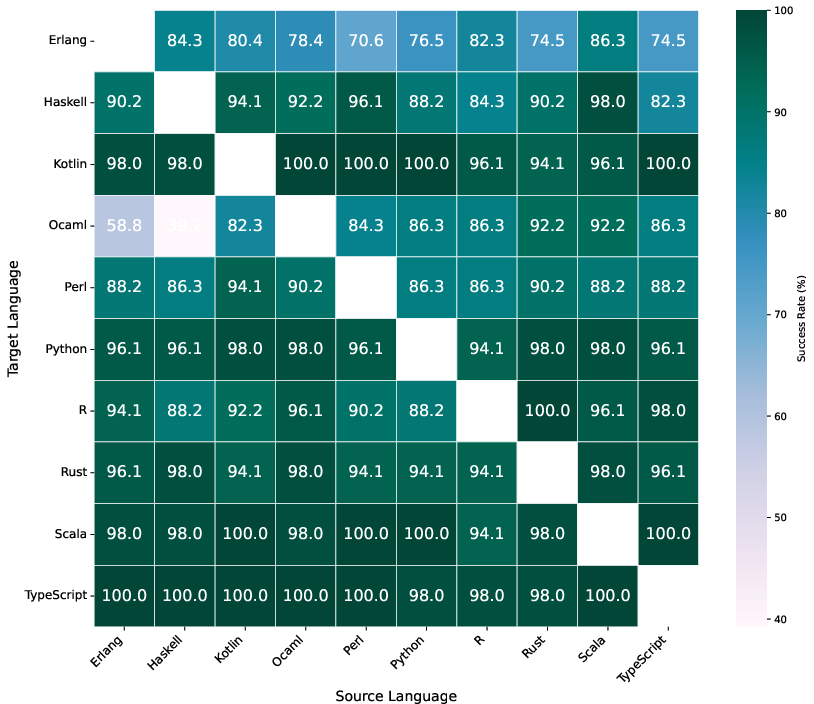
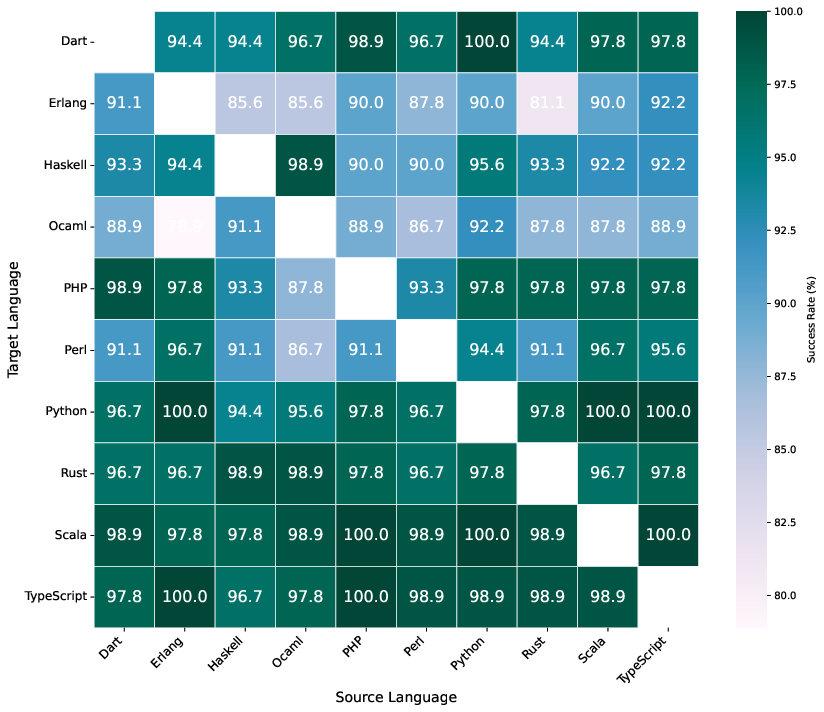
- The clever part: the system doesn’t just pick popular languages as bridges. It uses a “transfer matrix,” which is like a scoreboard showing which language translations tend to work best for each target language. This data-driven choice avoids bad guesses and picks bridge languages that have proven to translate well into the target language.
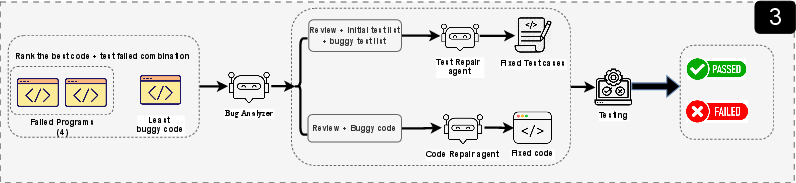
Stage 3: Fix what’s still broken
If the translated code still fails tests, a “repair” agent studies the errors and makes targeted fixes. It might adjust the code or the tests (for example, fixing type mismatches or adjusting function names) and then re-runs everything.
- Think of this like a bike repair: first you check what’s wrong (flat tire, loose chain), then you fix just that part, and test again.
What they found
XL-CoGen made a clear difference across many languages.
- It improved results by about 13 percentage points compared to the best fine-tuned baseline and up to 30 percentage points compared to earlier single-language multi-agent methods.
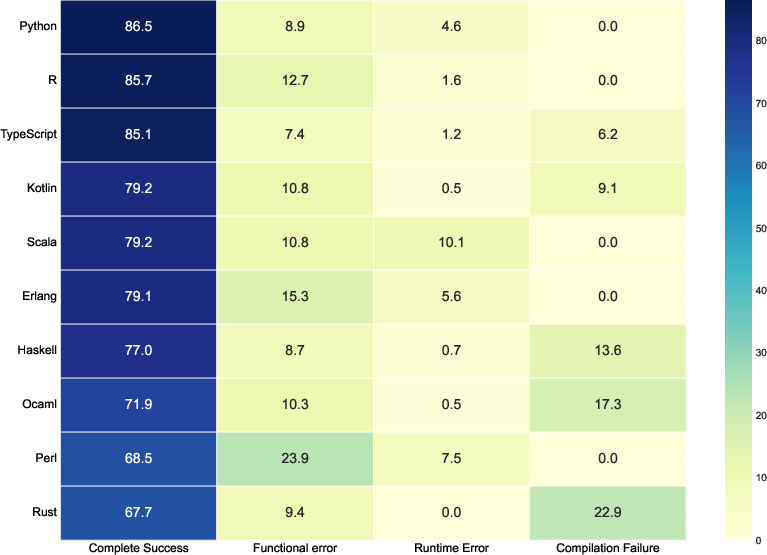
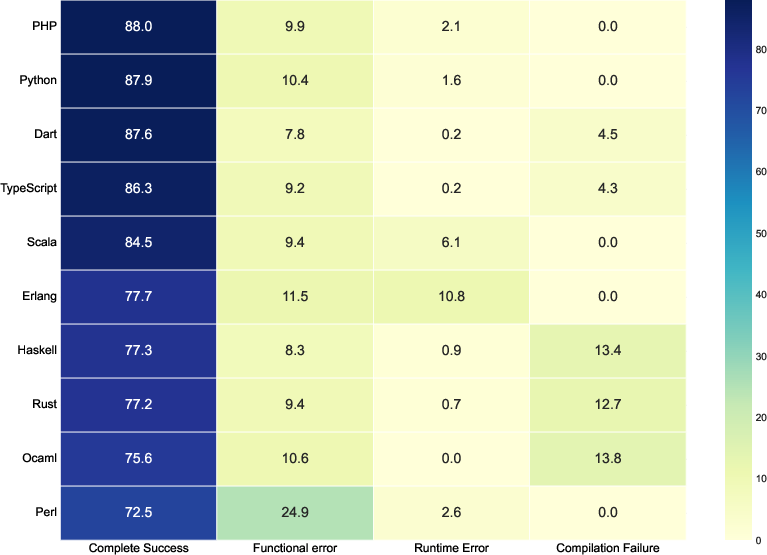
- It helped the most on tricky languages like Rust, Perl, OCaml, and Erlang.
- Choosing bridge languages with the “transfer matrix” (the scoreboard) beat just asking the AI to pick a bridge language. In other words, data-driven choices were more reliable than the AI’s intuition.
- Training a model only for one language (fine-tuning) didn’t help as much. In one test for Rust, more fine-tuning actually made performance worse, while XL-CoGen boosted success rates significantly.
Why this is important:
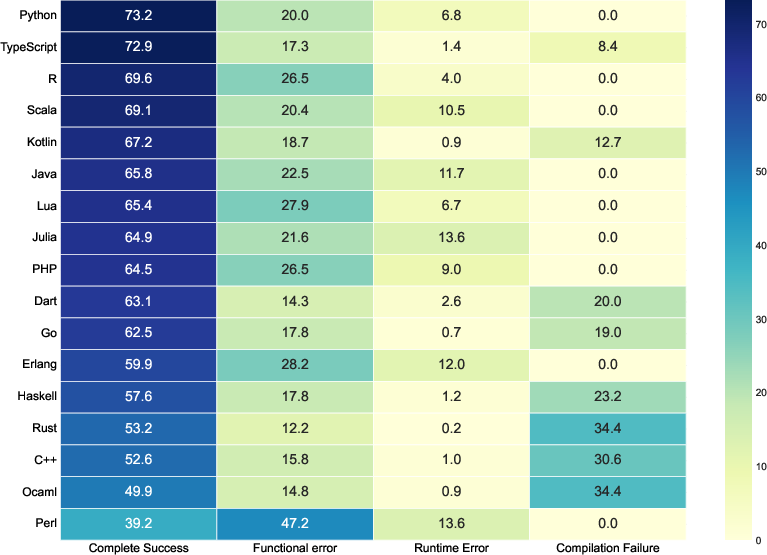
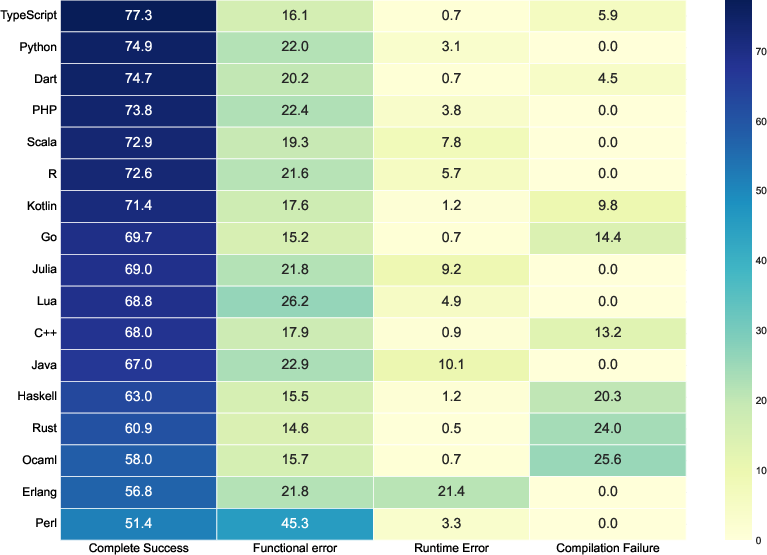
- The system not only raises overall success rates but also reduces common errors. That includes:
- Compilation errors: the code doesn’t even run because of syntax or type issues.
- Runtime errors: the code runs but crashes during execution.
- Functional errors: the code runs but gives the wrong answer.
- XL-CoGen especially cuts functional errors by using strong bridge languages and careful repair steps.
Why it matters
Modern software uses many languages. If AI can write good code across all of them, developers save time and can work more confidently. XL-CoGen shows that:
- We can use strengths in one language to lift performance in another, like translating a clear recipe to a different cuisine with the help of a skilled chef in between.
- Smart, data-based choices (like the transfer matrix) beat guessing.
- A coordinated “team” of AI agents—one to generate, one to translate, one to fix—can produce sturdier code than a single shot.
In simple terms, this research points to a future where AI is a reliable coding assistant across many languages, not just the popular ones, making software development faster, more accurate, and more inclusive of diverse tech stacks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper. Each point is phrased to be concrete and actionable for follow-up research.
Methodology and architecture
- The abstract claims integration of an “intermediate representation,” but the methodology describes only prompt reformulation and test standardization; the form, construction, and usage of any language-agnostic IR (e.g., pseudocode, typed ASTs, SSA) are unspecified and appear unimplemented.
- The multi-agent architecture is presented as workflows (generation, transfer, repair) but lacks operational details: agent roles, communication protocols, memory/state sharing, orchestration (e.g., concurrent vs. sequential), and whether agents are distinct models or role-conditioned instances of a single model.
- The “analysis agent” in Stage 3 is not formally defined: criteria for error categorization, diagnostic heuristics, and how execution traces/logs are leveraged remain opaque.
- Best partial result selection in Stage 2 (“minimizes failed test cases”) lacks an explicit scoring function (e.g., weighting of compile vs. runtime vs. functional errors, tie-breaking rules), making the selection step irreproducible.
Intermediate language selection and transfer matrices
- The construction of the empirical transfer matrix is under-specified: dataset size, task diversity, per-language sample counts, statistical confidence intervals, and procedures for handling missing/low-signal entries are absent.
- The combination rule for the two metrics (standalone generation reliability R and transfer success T) is not provided (e.g., normalization, weighting, aggregation), preventing replication and sensitivity analysis.
- Transfer matrices appear model-specific (DeepSeek vs. GPT) and potentially dataset-specific (MBPP-like tasks), but robustness across models, versions, and task distributions is untested; methods for updating matrices as LLMs evolve are not proposed.
- Only single-hop translation is considered; the value of multi-hop sequences (e.g., source → intermediate1 → intermediate2 → target), adaptive planning, or graph search (as in INTERTRANS/ToCT) is not evaluated.
- Per-problem adaptive intermediate selection (instance-level dynamic routing) is not explored; selection is global per target language rather than conditioned on problem type or semantics.
- No analysis of “why” certain languages are good bridges (e.g., paradigm similarity, typing discipline, library overlap); a feature-based or theoretical model of language compatibility could improve generalization.
Translation correctness and semantic fidelity
- Semantic equivalence is judged only via unit tests; there is no use of property-based testing, metamorphic relations, contract checking, or formal methods to detect semantic drift across translations.
- The methodology generates fresh test cases for intermediate languages rather than translating/aligning the original tests, introducing potential divergence in specifications; the decision criteria and risks are not discussed.
- Function signature and interface enforcement across translations are described but not formalized; how mismatches are detected and corrected (beyond ad hoc template usage) remains ambiguous.
- Non-functional characteristics (time/space complexity, resource usage, side effects, concurrency behavior) are not measured, yet translations across paradigms (e.g., Erlang/Haskell) may alter these properties.
Evaluation design and comparators
- The core benchmark is MBPP (simple, single-function tasks), adapted to multiple languages; external validity to complex, multi-file, stateful, or library-heavy tasks (e.g., CrossCodeEval, MultiPL-E, MBXP, HumanEval-X) is untested.
- Adaptation of MBPP prompts and tests to non-Python languages is not validated for paradigm-specific semantics (e.g., laziness in Haskell, actor model in Erlang, borrow checker in Rust); systematic verification of fair, language-idiomatic test harnesses is missing.
- Pass@1 is emphasized; the impact of sampling (pass@k), diversity, or re-ranking is not assessed, nor are coverage metrics for the test suites.
- Reported improvements over “single-language multi-agent methods” are claimed without direct, controlled head-to-head baselines across the same languages and tasks; reproducible protocols for competitor systems are not provided.
- Statistical testing is mentioned for RQ2 but not systematically applied across all results (e.g., per-language significance, multiple comparisons corrections); sample sizes per language/problem are not stated.
Practicality, cost, and reproducibility
- The computational profile of XL-CoGen (latency, token usage per stage, failure recovery costs, wall-clock and monetary cost) is not measured; trade-offs vs. simpler baselines are unknown.
- Environment details (compiler/interpreter versions, language-specific runners, dependencies, OS/toolchain configuration) are not documented, hindering reproducibility—especially for languages with strict toolchain requirements (Rust edition, Erlang OTP versions).
- Code, prompts, Jinja test templates, and the transfer matrices are not released; transparency and independent verification are currently not possible.
- The choice of retry limit = 1 in Stage 3 is not justified with sensitivity analyses; optimal iteration budgets and adaptive stopping criteria remain open.
- The claimed fine-tuning of GPT-4.1-mini lacks training hyperparameters, infrastructure, and feasibility details (model availability for fine-tuning, optimizer, learning rate, steps, data curation); the negative fine-tuning results may reflect setup issues rather than a general principle.
- DeepSeek-V3.1 is evaluated, but open-source fine-tuning comparisons are omitted (e.g., CodeLlama, StarCoder2), limiting insights into fine-tuning vs. transfer for models that can be fully controlled.
Coverage of languages and tasks
- Language coverage, while broad, omits several low-resource or niche languages (e.g., Elm, Nim, F#, Elixir, Scheme), limiting generalization claims; procedures to onboard a new language (building runners, templates, and matrix entries) are not described.
- Domain-specific stacks (data science, web frameworks, systems programming with crates/libs) are not evaluated; reliance on standard library-only tasks may inflate real-world applicability.
Quality, safety, and maintainability
- Code quality metrics (readability, idiomaticity, cyclomatic complexity, documentation/comments) are not assessed; the risk of “unidiomatic translations” (e.g., Pythonic patterns in Rust) is unexplored.
- Security analyses (unsafe API usage, injection risks, insecure defaults, memory safety pitfalls in C++/Rust, concurrency hazards) are absent; static analysis or linting could complement correctness testing.
- Robustness to adversarial/problematic specifications (ambiguous prompts, conflicting tests, non-deterministic tasks) is unexamined.
Open research directions
- Instance-level adaptive routing: learn a policy to choose bridging languages per problem using lightweight probes, meta-features, or uncertainty estimates.
- Multi-hop planning: evaluate sequence planning over a language graph (A* or bandit-based exploration) to exceed single-hop transfer performance under budget constraints.
- Formal IR and verification: define and leverage typed pseudocode/AST IR for translation, with contract enforcement and equivalence checking across languages.
- Online/continual matrix updates: design mechanisms to keep transfer matrices current as models evolve, with drift detection and active re-sampling.
- Richer evaluation: add project-scale, multi-file tasks, cross-module dependencies, and integration tests to assess scalability; include property-based and metamorphic tests.
- Cost-aware optimization: quantify and optimize token/latency budgets per stage; explore anytime variants that trade accuracy for latency.
- Human-in-the-loop workflows: study how developers interact with artifacts (intermediate solutions, diagnostics), and define UX for inspecting/overriding agent decisions.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed today using the paper’s methods and findings.
- Cross-language fallback code generation in IDEs and CI (software)
- What: Add an agentic fallback that, when initial code generation in the target language fails, routes through empirically optimal “bridging” languages, validates with tests, and applies one iteration of automated repair.
- Tools/products/workflows: IDE extensions (e.g., VS Code plugin), CI jobs for PRs that trigger XL-CoGen’s Stage 2–3; “CrossLang PR Assistant” that proposes test-validated patches.
- Assumptions/dependencies: Unit tests or executable specs exist; language runtimes and compilers are installed in sandboxed runners; transfer matrices precomputed for the chosen model (e.g., GPT‑4.1‑mini, DeepSeek‑V3); cost/latency budget acceptable for multistep generation.
- Multilingual SDK and documentation snippet generator (software, developer relations, education)
- What: Generate canonical examples in a high-performing language and reliably translate them to multiple target languages for API docs, tutorials, and sample apps.
- Tools/products/workflows: “DocSnippet Generator” service; docs CI that regenerates and validates code samples across Python/JS/Rust/…; artifact reuse to keep snippets consistent.
- Assumptions/dependencies: Example code is testable (or has golden outputs); availability of language-specific test harness templates (as in the paper’s Jinja approach); transfer matrix aligned with the LLM used.
- Prototype-to-production porting for performance/safety (software, robotics/embedded)
- What: Prototype algorithms in a familiar language (e.g., Python), validate, then back-translate to Rust/C++/Erlang for production, with execution-based checks.
- Tools/products/workflows: “Prototype Porter” pipeline; ROS/embedded workflows that translate validated Python nodes to C++/Rust equivalents.
- Assumptions/dependencies: Equivalent libraries or idioms exist in the target language; tests cover performance-critical/edge cases; toolchains for compiling/validation are containerized.
- Open-source maintenance across polyglot monorepos (software)
- What: Automated agents suggest fixes by generating in a bridging language, translating to the repo’s target language, running tests, and submitting PRs.
- Tools/products/workflows: “Monorepo Polyglot Assistant”; GitHub Actions that use XL‑CoGen’s Stage 2–3 for failing issues.
- Assumptions/dependencies: Reliable project-level tests; isolated execution to avoid supply-chain risks; model access keys and budget.
- Data science and analytics code translation (healthcare, finance, data platforms)
- What: Translate analysis utilities among R, Python, and Scala/Spark while preserving semantics via test standardization and execution validation.
- Tools/products/workflows: “Pipeline Porter” that converts validated R prototypes to PySpark/Scala; ETL library adapters auto-generated across languages.
- Assumptions/dependencies: Deterministic tests (watch for randomness and floating-point differences); comparable libraries across environments.
- Courseware and grading assistants for multi-language curricula (academia, education)
- What: Produce equivalent solutions and tests in multiple languages from a single assignment spec; auto-grade with language-specific harnesses.
- Tools/products/workflows: “MultiLang Assignment Builder”; autograder that runs XL‑CoGen to generate baseline solutions and tests in target languages.
- Assumptions/dependencies: Clear specs and unit tests; sandboxing for student code; curated language subsets to reduce library/version drift.
- Translation compatibility matrix as a service (industry R&D, academia)
- What: Maintain and publish per-model transfer matrices that rank best intermediate languages for specific targets.
- Tools/products/workflows: “Transfer Matrix Service” with APIs and dashboards; model-aware routing in toolchains.
- Assumptions/dependencies: Reproducible benchmarks; periodic recalibration as models change; coverage for the organization’s language set.
- Multilingual test harness and artifact reuse library (software tooling)
- What: Standardized test case JSON + templated harnesses to run the same tests across languages; reuse intermediate artifacts as scaffolding.
- Tools/products/workflows: “CrossLang Test Harness” open-source library; adjudication utilities that pick best partial results for repair.
- Assumptions/dependencies: Language runners; hermetic containers to ensure reproducibility; policy for storing/reusing intermediate artifacts.
Long-Term Applications
Below are use cases that require additional research, scale-out, or engineering to be deployment-ready.
- Automated large-scale codebase porting and modernization (enterprise, legacy systems)
- What: Plan multi-hop translations using empirically optimal bridges, iterative repair beyond a single retry, and coverage-guided testing to port subsystems (e.g., Python→Rust for memory safety).
- Tools/products/workflows: “Legacy Modernizer” for polyglot repos; migration planners using Trees of Code Translation with execution feedback.
- Assumptions/dependencies: Rich, property-based tests or formal specs to control semantic drift; broader library equivalence mapping; organizational tolerance for incremental porting.
- Continuous, model-aware routing for code generation (MLOps for coding tools)
- What: Online learning updates the transfer matrix per model version and domain; the system dynamically picks bridges by target language and problem class.
- Tools/products/workflows: “Routing Brain” that monitors pass@k and error types to adapt bridging strategies; A/B testing in IDEs/CI.
- Assumptions/dependencies: Telemetry from production usage; governance for data collection; experimentation frameworks.
- Multi-language SDK generation with long-term synchronization (platform engineering)
- What: Keep official SDKs across 8–12 languages in sync by regenerating from a canonical spec, validating with contract tests, and repairing drift automatically.
- Tools/products/workflows: “SDK Sync Bot” triggered by API schema changes; diff-aware repair agents; release pipelines with multi-language gates.
- Assumptions/dependencies: Stable canonical specs (OpenAPI/GraphQL/IDL); extensive contract test suites; style/lint conformity rules per language.
- Verified cross-language synthesis for safety-critical software (healthcare, automotive, aerospace)
- What: Combine execution-based testing with formal methods (e.g., contracts, model checking) to ensure translations preserve critical invariants.
- Tools/products/workflows: “Proof‑Aided Translator” that integrates property checking with agentic repair; certification-friendly logs/artifacts.
- Assumptions/dependencies: Formal specs exist; toolchains for proofs; domain auditors accept hybrid test+proof evidence.
- Cross-language security hardening and remediation (software security)
- What: Translate vulnerable components to memory-safe languages (e.g., C/C++→Rust) or synthesize patches by repairing in a bridging language and translating back.
- Tools/products/workflows: “SecurePort” for targeted modules; SAST/DAST-integrated agent that proposes validated, cross-language fixes.
- Assumptions/dependencies: Vulnerability test cases or proofs-of-exploit; Rust/C++ feature parity; performance/regulatory constraints.
- Polyglot microservice synthesis and synchronization (cloud, DevOps)
- What: Generate and keep aligned microservice implementations in different languages for heterogeneous stacks (e.g., Node.js, Go, Java), with shared test suites.
- Tools/products/workflows: “Service Twin Generator” that enforces behaviorally equivalent services and synchronizes changes via shared artifacts.
- Assumptions/dependencies: Contract-first development; strong test discipline; multi-runtime orchestration and observability.
- Education at national scale: multi-language curricula builders (policy, academia)
- What: Provide ministries and universities with tooling to auto-create equivalent course content and lab material across commonly taught languages, improving access where certain languages are resource-poor.
- Tools/products/workflows: “Curriculum Bridge Suite” for course authoring; repository of vetted transfer matrices for pedagogical stacks.
- Assumptions/dependencies: Public, curated benchmarks for target languages; educator workflows; funding for sandbox infrastructure.
- Public registries and standards for AI codegen transparency (policy, standards)
- What: Require vendors to report language coverage, transfer matrices, and test-based accuracy by language; standardize execution-based validation in procurement.
- Tools/products/workflows: “Language Transfer Index” as an open registry; conformance suites for multilingual codegen tools.
- Assumptions/dependencies: Multi-stakeholder governance; shared benchmarks; versioned reporting to track model drift.
- Edge/robotics translation for constrained environments (robotics, IoT)
- What: Auto-port from high-level prototypes to resource-constrained languages/runtimes (e.g., MicroPython→C/C++), with footprint and timing tests.
- Tools/products/workflows: “Edge Porter” that couples translation with performance regress testing and limited resource simulators.
- Assumptions/dependencies: Hardware-in-the-loop or accurate simulators; deterministic tests; optimization passes tied to target toolchains.
Cross-Cutting Assumptions and Dependencies
- High-quality, executable test suites are critical; weak tests increase the risk of semantic drift.
- Precomputed transfer matrices must be built per model and kept up to date; gains depend on the chosen model’s capabilities and data distribution.
- Reliable sandboxed execution environments for many languages are required (compilers/interpreters, package managers, version pinning).
- Cost and latency scale with multi-stage, multi-language attempts; budgets and user experience need careful management.
- Library/API parity varies by language; some translations require idiomatic substitutions or design changes.
- Governance and security: code execution must be isolated; logs and artifacts should be auditable, especially in regulated sectors.
- Representative benchmarks matter: matrices derived from narrow tasks may not generalize to complex, domain-specific code.
Glossary
- Ablation studies: Controlled experiments that remove or disable components of a system to measure their individual contributions. "Ablation studies further demonstrate that compatibility-guided bridging significantly outperforms LLM-based heuristics, confirming the value of cumulative cross-language knowledge transfer."
- Agentic iteration: An iterative process where autonomous agents repeatedly refine outputs through planning, critique, and revision. "Our approach combines agentic iteration, execution-based feedback, strategic cross-language knowledge transfer, and performance-aware language adaptation."
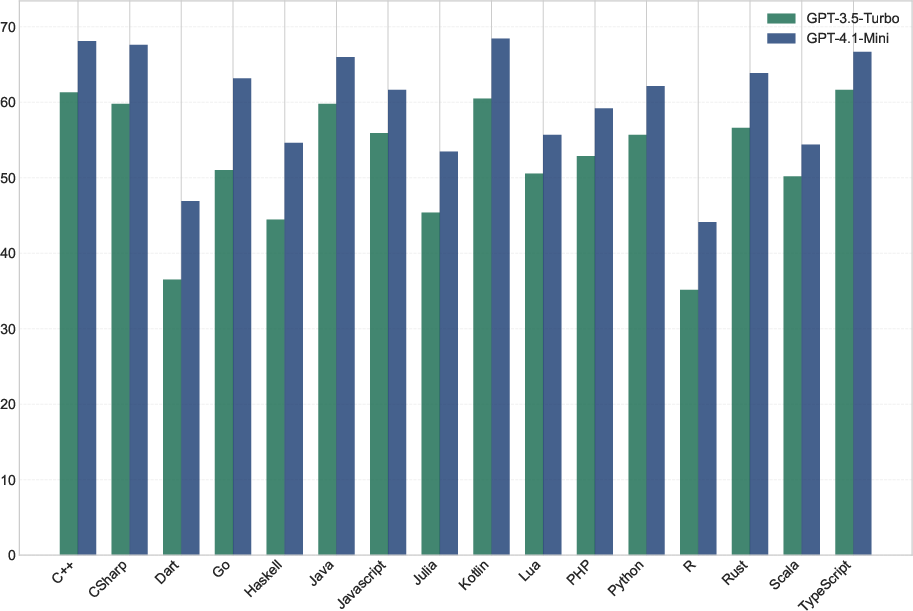
- BabelCode dataset: A multilingual benchmark for code generation and translation tasks across programming languages. "Cref{fig:motivation} illustrates these performance gaps using GPT-3.5-Turbo and GPT-4.1-Mini results on the BabelCode dataset."
- Back-Translation: Translating a solution from an intermediate language back to the target language to preserve functionality. "Back-Translation: For validated intermediate solutions, we regenerate code in the target language using the working intermediate code as foundation, requesting functional equivalence while maintaining semantic consistency."
- CodeNet: A large-scale dataset of programming problems and solutions used for code-related model evaluation. "Evaluated across CodeNet, HumanEval-X, and TransCoder benchmarks, INTERTRANS achieved 18.3\% to 43.3\% absolute improvements over direct translation methods."
- Cross-language knowledge transfer: Leveraging information or solutions from one programming language to improve performance in another. "confirming the value of cumulative cross-language knowledge transfer."
- CrossCodeEval: A benchmark designed to evaluate cross-language code understanding and completion, including multi-file contexts. "Recent benchmarks such as CrossCodeEval have further exposed these limitations by testing models' ability to understand cross-file information and accurately complete code across multiple languages..."
- DeepSeek-V3: An open-source LLM used for code generation and translation benchmarks. "Both DeepSeek-V3 and GPT-4.1-mini exhibit consistent improvement patterns under XL-CoGen, though with different magnitudes and characteristics."
- Empirical performance matrix: A data-driven matrix capturing observed success rates between languages to guide intermediate language selection. "We construct an empirical performance matrix across programming languages by evaluating benchmark problems where all languages can produce correct solutions."
- EvalPlus leaderboard: A public evaluation platform reporting code generation metrics (e.g., HumanEval+, MBPP+). "Results from the EvalPlus leaderboard~\cite{evalplus} confirm that GPT-4-class models achieve leading pass@1 performance on HumanEval+ and MBPP+..."
- Execution-based feedback: Using program execution outcomes (tests, errors) to guide iterative refinement of generated code. "Our approach combines agentic iteration, execution-based feedback, strategic cross-language knowledge transfer, and performance-aware language adaptation."
- Execution semantics: The runtime behavior and rules governing how code executes in a given programming language. "revealing model grasp of language-specific execution semantics and programming idioms."
- Fine-tuning: Adapting a pretrained model on a specialized dataset to improve performance in a specific domain or task. "Many current solutions including language-specific fine-tuning, multi-agent orchestration, transfer learning, and intermediate-representation pipelines..."
- Foundation models: Large, general-purpose models trained on broad data that can be adapted to many downstream tasks. "Code-specialized LLMs represent particularly significant implementations of foundation models..."
- Greedy decoding: A deterministic text generation strategy that selects the highest-probability token at each step. "For all experiments, we used greedy decoding with temperature set to 0 to mitigate randomness while preserving output coherence..."
- HumanEval-X: A multilingual extension of the HumanEval benchmark used to assess code generation. "Evaluated across CodeNet, HumanEval-X, and TransCoder benchmarks, INTERTRANS achieved 18.3\% to 43.3\% absolute improvements over direct translation methods."
- HumanEval-XL: An expanded benchmark suite for multilingual code generation evaluation. "Multiple benchmarks have been developed to evaluate code generation across programming languages, including HumanEval-X~\cite{zheng2023codegeex}, HumanEval-XL~\cite{peng2024humanevalxlmultilingualcodegeneration}..."
- Intermediate representation: A language-neutral or alternate-language form used as a bridge to facilitate translation or synthesis. "XL-CoGen tackles this challenge with a coordinated multi-agent architecture that integrates intermediate representation, code generation, translation, and automated repair."
- INTERTRANS: A method that improves code translation via transitive intermediate languages and planned translation paths. "Macedo et al.~\cite{macedo2024intertransleveragingtransitiveintermediate} developed INTERTRANS, which leverages transitive intermediate translations to enhance LLM-based code translation."
- Jinja templates: Templating artifacts used to generate language-specific test harnesses consistently across languages. "Language-specific Jinja templates provide structural frameworks for test execution, handling syntax variations and testing frameworks while maintaining consistent evaluation interfaces across languages."
- LANTERN: A framework that repairs low-resource language code by translating to high-resource languages, fixing, and translating back. "Luo et al.~\cite{luo2025unlockingllmrepaircapabilities} introduced LANTERN, a framework addressing code repair in low-resource programming languages through cross-language translation and multi-agent refinement."
- Language-agnostic terminology: Problem descriptions phrased to avoid language-specific constructs, aiding cross-language consistency. "We reformulate the instruction into a clearer, more precise version using standardized, language-agnostic terminology."
- Low-resource programming languages: Languages with limited training data or tooling, often yielding weaker model performance. "low-resource programming languages such as Julia, Rust, Perl, and Haskell"
- Mann-Whitney U test: A nonparametric statistical test for assessing differences between two independent samples. "Statistical analysis using Mann-Whitney U tests and t-tests confirms all improvements are highly significant."
- MBPP: A dataset of short programming tasks (Mostly Basic Python Problems) used to evaluate code generation. "We use MBPP (Mostly Basic Python Problems)~\cite{austin2021program}, consisting of approximately 974 short programming tasks..."
- Model-in-the-loop: A refinement setting where the model iteratively updates code using feedback from execution or evaluation. "The repair process continues iteratively using model-in-the-loop prompting augmented with execution environment error messages."
- Multi-agent orchestration: Coordinating multiple specialized agents to collaboratively plan, generate, and refine code. "Many current solutions including language-specific fine-tuning, multi-agent orchestration, transfer learning, and intermediate-representation pipelines..."
- Multi-hop translation: Translating code through one or more intermediate languages to bridge complex source-target gaps. "plan multi-hop translation sequences through intermediate programming languages."
- Pass@k: The fraction of tasks solved when considering up to k generated attempts; a standard code-gen metric. "Pass@k~\cite{chen2021evaluating}: Our primary evaluation metric measures the percentage of problems where generated solutions pass all provided test cases."
- Prompt Adaptation: Reformulating instructions to be clearer and language-neutral before generation. "Step 1: Prompt Adaptation."
- Semantic drift: Unintended changes in meaning introduced during translation or transformation steps. "may introduce semantic drift through multiple translation steps."
- Semantic fidelity: Preservation of intended meaning and behavior across representations or languages. "to preserve semantic fidelity throughout the process."
- Semantic validity framework: A structured scheme to categorize failures (compilation, runtime, functional) for deeper diagnostic analysis. "we implement a comprehensive semantic validity framework categorizing unsuccessful attempts into three mutually exclusive error types"
- SWE-bench Verified: A benchmark evaluating code models on software engineering tasks with verified solutions. "OpenAI reports 54.6\% performance on SWE-bench Verified compared to 33.2\% for GPT-4o"
- t-test: A statistical test used to compare means between groups to determine significance. "Statistical analysis using Mann-Whitney U tests and t-tests confirms all improvements are highly significant."
- Transfer learning: Reusing knowledge gained from one task or domain to improve performance in another. "Many current solutions including language-specific fine-tuning, multi-agent orchestration, transfer learning, and intermediate-representation pipelines..."
- Transfer matrix: A matrix capturing empirical translation success between language pairs to guide bridging-language selection. "empirically derived transfer matrices identify the best intermediate languages based on demonstrated translation success rather than raw generation accuracy."
- Tree of Code Translation (ToCT): A planning algorithm that structures multi-step translations through intermediate languages. "INTERTRANS employs a Tree of Code Translation (ToCT) algorithm to plan multi-hop translation sequences through intermediate programming languages."
Collections
Sign up for free to add this paper to one or more collections.