Logics-Parsing Technical Report
Abstract: Recent advances in Large Vision-LLMs (LVLM) have spurred significant progress in document parsing task. Compared to traditional pipeline-based methods, end-to-end paradigms have shown their excellence in converting PDF images into structured outputs through integrated Optical Character Recognition (OCR), table recognition, mathematical formula recognition and so on. However, the absence of explicit analytical stages for document layouts and reading orders limits the LVLM's capability in handling complex document types such as multi-column newspapers or posters. To address this limitation, we propose in this report Logics-Parsing: an end-to-end LVLM-based model augmented with reinforcement learning. Our model incorporates meticulously designed reward mechanisms to optimize complex layout analysis and reading order inference. In addition, we expand the model's versatility by incorporating diverse data types such as chemical formulas and handwritten Chinese characters into supervised fine-tuning. Finally, to enable rigorous evaluation of our approach, we introduce LogicsParsingBench, a curated set of 1,078 page-level PDF images spanning nine major categories and over twenty sub-categories, which will be released later. Comprehensive experiments conducted on LogicsParsingBench have validated the efficacy and State-of-the-art (SOTA) performance of our proposed model across diverse document analysis scenarios. Project Page: https://github.com/alibaba/Logics-Parsing



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-English Summary of “Logics-Parsing”
What is this paper about?
This paper introduces Logics-Parsing, a smart computer model that reads and understands complex PDF pages—like magazines, newspapers, and scientific papers. It doesn’t just read the words; it also figures out where things are on the page (like paragraphs, tables, and formulas) and in what order a person should read them. The goal is to turn a page image into a clean, structured output that computers can use.
What questions did the researchers want to answer?
The researchers aimed to solve a few practical problems:
- Can we build one end-to-end model that replaces many separate tools for reading documents?
- Can the model understand complex page layouts (like multiple columns) and follow the right reading order?
- Can it recognize many types of content—plain text, tables, math formulas, chemical diagrams, and even handwritten Chinese?
- How can we fairly test such a model on pages that are truly challenging?
How did they do it?
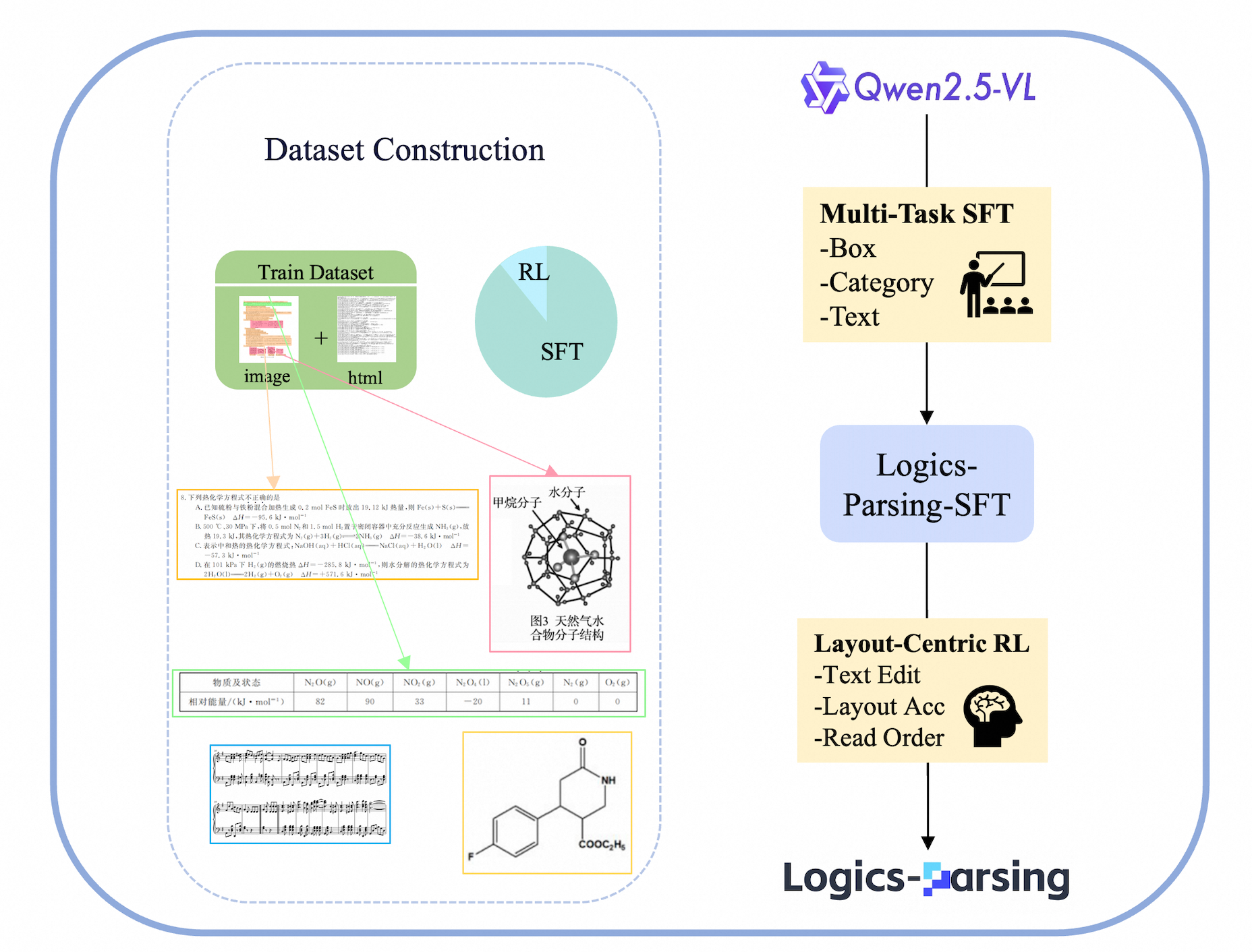
The team trained their model in two main steps. Think of it like learning to read a textbook and then practicing with tricky puzzles.
- Step 1: Supervised Fine-Tuning (SFT)
- They started with a strong base model (Qwen2.5-VL-7B), which can already see images and understand text.
- They showed it more than 300,000 labeled pages and taught it to output a structured description in HTML (like a blueprint of a webpage that lists paragraphs, tables, and formulas with their positions).
- Everyday analogy: First, teach the model the “rules of the page” and how to write a neat, organized summary.
- Step 2: Layout-Centric Reinforcement Learning (LC-RL)
- After the basics, they practiced on about 8,000 especially tricky pages (chosen because the model got them “partly right” but made notable mistakes).
- The model got points (“rewards”) for three things:
- Text accuracy: Are the words it outputs the same as the real page? (They used a standard measure of how similar two strings are.)
- Location accuracy: Did it place each text block at the right spot on the page? (Bounding boxes are like drawing a rectangle around each paragraph.)
- Reading order: Did it list the content in the order a human would read it (left-to-right, top-to-bottom, respecting columns)?
- Everyday analogy: Like grading a student’s homework not only by correct answers, but also by whether they followed the right steps and wrote things in the right places.
To support training, they built a diverse dataset:
- They combined public datasets for tables, math, and chemistry with their own large in-house pages.
- They used an automatic tool (Mathpix) to pre-annotate pages, had another AI (Gemini 2.5 Pro) check tough cases, and finally asked human experts to fix the hardest ones and mark the correct reading order.
- Using HTML as the label format made it easier to represent a page’s structure clearly.
They also created a new test set:
- LogicsParsingBench: 1,078 pages across 9 major categories (including scientific papers, posters, newspapers, music scores, and Chinese ancient books), designed to really test layout handling and scientific content.
What did they find, and why does it matter?
Here are the main takeaways from their experiments:
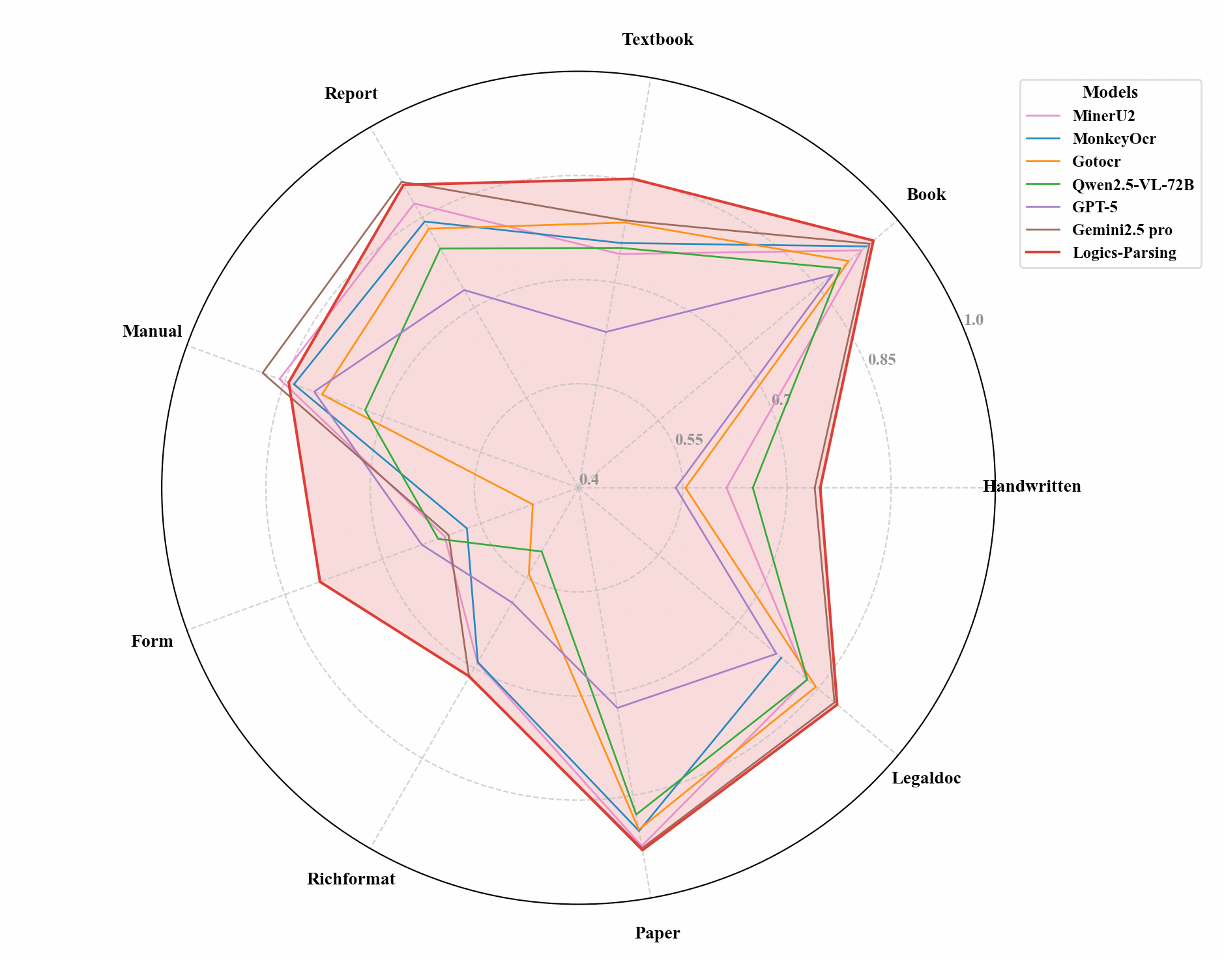
- Overall best performance on complex pages: On LogicsParsingBench, Logics-Parsing scored better than many existing systems in both English and Chinese.
- Much better reading order: The reinforcement learning step notably reduced errors in the order of content, which is critical for multi-column pages and posters.
- Strong on varied content: It did especially well on plain text, chemical structures, and handwritten Chinese.
- Two-stage training works: Starting with SFT to stabilize output, then using RL to fine-tune layout and order, improved accuracy and made results more human-like.
- Still room to grow: Tables and very complex math formulas remain challenging compared to some specialized tools, suggesting future focus on 2D layout modeling.
This matters because correct reading order and precise structure are crucial for search, data extraction, and AI systems that pull text from documents to answer questions. If the model reads things out of order, the meaning can get scrambled.
What impact could this have?
This research can:
- Make document AI more reliable for real-world pages, not just simple ones.
- Strengthen systems like RAG (Retrieval-Augmented Generation), which need clean, ordered text and accurate tables/formulas to give good answers.
- Help researchers, businesses, and libraries quickly convert archives, scientific articles, and complex PDFs into structured, searchable formats.
- Provide a tough, realistic benchmark (LogicsParsingBench) to push future models to handle tricky layouts better.
In short, Logics-Parsing shows that combining a solid base model with careful training and targeted rewards can produce a system that reads complex documents more like a person—accurately, in the right order, and with an understanding of layout.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, framed to guide future research concretely.
- RL reward design lacks structure-aware components for 2D layouts: no table-graph rewards (e.g., TEDS-driven or cell-level alignment) or formula-structure rewards (e.g., MathML/AST equivalence), which likely contributes to weaker table and math performance; quantify and test the impact of adding structure-specific rewards.
- Reading order reward depends on paragraph segmentation quality: the inversion-count metric presumes correct block segmentation; investigate robust segmentation-aware rewards and alignment strategies when predicted and reference blocks differ.
- Reward weighting and sensitivity are unspecified: the linear combination of the three rewards is not detailed; perform ablations on weights, scaling, and reward shaping (e.g., clipping, normalization) to assess stability and performance trade-offs.
- RL training scope is unclear (which parameters are updated): clarify whether RL updates the vision encoder and projector; compare RL on LLM-only vs full model updates to understand where gains originate.
- Hard-sample mining thresholds are heuristic: the NED range [0.5, 0.8] is not justified; ablate threshold ranges and sampling sizes, and test inclusion/exclusion of very hard (<0.5) and near-perfect (>0.8) cases to optimize sample efficiency.
- Limited RL steps and potential overfitting: only 250 RL steps on ~8k samples may overfit to the curated subset; study learning curves, generalization to unseen complex layouts, and techniques like curriculum RL or regularization.
- Freezing the visual encoder in SFT may cap perception gains: evaluate unfreezing strategies, partial adapters, or training a document-specialized encoder to improve small-text and dense-layout perception.
- Input resolution capped at ~1024×1024 pixels: assess the impact of higher resolution, multi-scale tiling, or patch-based inference on dense small fonts and intricate diagrams; report speed/accuracy trade-offs.
- Page-level only parsing: multi-page documents, cross-page references, and global reading order are not addressed; design and evaluate multi-page layout reasoning and content linking (e.g., figures/tables referenced across pages).
- Limited language/script coverage: evaluated on English and Chinese; investigate RTL scripts (Arabic/Hebrew), vertical text (Japanese), mixed scripts, and code blocks; extend reading-order rules beyond LTR, top-to-bottom assumptions.
- Music scores and specialized content are mentioned but not operationalized: clarify target outputs (e.g., MusicXML for scores), define evaluation metrics, and report results to demonstrate true multimodality beyond text/tables/formulas/chemistry.
- Chemistry evaluation may suffer from SMILES canonicalization issues: specify normalization (canonical SMILES, stereochemistry handling) and add semantic metrics (e.g., molecule isomorphism checks) to avoid penalizing equivalent strings.
- Global text evaluation changes comparability: concatenating page text reduces penalties from segmentation differences but may mask layout errors; include both global and block-level metrics to capture structure-sensitive performance.
- Layout localization reward is not reflected in reported metrics: IoU, AP for region detection, or alignment scores between predicted and GT boxes are not reported; add explicit localization metrics to validate the grounding component.
- Evaluation excludes images from reading order: test reading order that interleaves text, figures, captions, and tables to reflect real reading flows, and define penalties for misplacing captions or figure references.
- Benchmark availability and potential data overlap: LogicsParsingBench is “to be released later”; document non-overlap with training data (especially the in-house and Mathpix/Gemini-verified sets), include license details, and provide train/val/test splits for reproducibility.
- Annotation quality and consistency are unquantified: report inter-annotator agreement for reading order and structural labels, error rates from automated tools (Mathpix/Gemini), and bias analyses across categories.
- Potential biases from proprietary annotators: quantify how Mathpix/Gemini outputs influence training/evaluation, and test robustness on documents where these tools perform poorly to avoid tool-specific bias entrenchment.
- Table recognition underperforms SoTA: analyze failure modes (merged/split cells, spanning headers, nested tables) and evaluate architectural additions (graph decoders, structural pointer nets) targeted at cell topology and header semantics.
- Mathematical formula parsing underperforms leading methods: add normalization (LaTeX canonicalization), semantic equivalence checks (e.g., SymPy), and formula-specific sub-decoder or pretraining to better capture nested structures.
- Reading order still lags a top commercial tool (TextIn): perform targeted RL for non-linear layouts (posters, magazines), incorporate visual cues (gutters, column separators), and evaluate rule-augmented rewards for column-aware sequencing.
- Output HTML robustness is untested: report malformed rate, schema compliance, and downstream renderability; add validators and recovery strategies (e.g., self-repair decoding) for production reliability.
- Scalability to larger models and longer training is unexplored: ablate model size (e.g., 7B vs 72B), SFT epochs, and RL horizon to study scaling laws for document parsing.
- Inference efficiency and latency are not characterized: provide throughput, memory footprint, and latency under dynamic resolution; evaluate deployment feasibility on CPU/edge devices and batching strategies.
- Robustness to noisy scans and artifacts is not assessed: test skewed pages, blur, compression, watermarks, stamps, and handwritten additions; include augmentation strategies and robustness benchmarks.
- Cross-domain generalization and fairness: evaluate on legal, financial, healthcare, and low-resource domains; measure performance disparities across categories and propose domain-adaptive training.
- Safety and privacy considerations are absent: detail handling of sensitive documents, on-prem deployment options, and mechanisms to prevent data leakage during annotation and model training.
- Downstream task integration is untested: demonstrate how HTML/LaTeX/SMILES outputs enable RAG, content retrieval, or analytics; measure end-to-end pipeline gains versus pipeline OCR baselines.
- Lack of comparisons under identical evaluation protocols: since the paper introduces stricter normalization and global text metrics, ensure fair head-to-head comparisons with baselines under both the original and modified protocols.
Practical Applications
Immediate Applications
The findings and innovations in Logics-Parsing enable several practical use cases that can be deployed now, leveraging its end-to-end LVLM approach, dynamic-resolution vision encoder, layout-centric reinforcement learning for reading order, and multimodal recognition (text, tables, formulas, chemistry, handwriting). Below is a concise list of high-impact applications, each with sector alignment, potential tools/workflows, and feasibility notes.
- Layout-aware PDF-to-HTML conversion for websites and CMS
- Sectors: software, publishing, media
- Tools/workflows: “Logics-Parsing API” as a conversion service; batch converters in content pipelines; plugins for CMS/editors to export semantic HTML with bounding boxes and correct reading order
- Assumptions/dependencies: GPU/accelerator access for high-resolution inputs; acceptance of HTML schema; potential post-processing for tables and math
- Structure-preserving ingestion for RAG and enterprise search
- Sectors: software (knowledge management), enterprise IT
- Tools/workflows: document ETL that extracts text blocks, coordinates, and logical order; indexing with spatial metadata; downstream “layout-aware RAG” where chunking respects reading flow
- Assumptions/dependencies: vector store integration; prompt strategies leveraging structure metadata; quality varies for tables/formulas in edge cases
- Scientific document normalization (LaTeX math, SMILES chemistry) for publishers and databases
- Sectors: academia, scientific publishing, chemical informatics
- Tools/workflows: pipelines converting equations to LaTeX and chemical diagrams to SMILES; validation UI for editorial teams; batch normalization of archives
- Assumptions/dependencies: domain-specific QA needed; chemistry and math recognition are strong but not yet best-in-class for some complex structures
- Accessibility remediation for screen readers via correct reading order and structure
- Sectors: public sector, education, corporate compliance
- Tools/workflows: PDF remediation tool that outputs semantic HTML with verified reading order; automated WCAG/Section 508 checks using structure
- Assumptions/dependencies: alignment with accessibility standards; consistent mapping from HTML to accessible PDF/EPUB
- Newspaper and magazine digitization with multi-column handling
- Sectors: libraries/archives, media, public sector
- Tools/workflows: batch digitization toolkit; reading-order-correct export; OCR+layout extraction for historical archives
- Assumptions/dependencies: high-resolution scans; policies for metadata; quality validation for mixed text-graphic pages
- Legal e-discovery and compliance document parsing
- Sectors: legal, compliance (policy/finance/insurance)
- Tools/workflows: ingestion of exhibits and filings; preservation of logical flow for downstream analytics; structured extraction of sections and references
- Assumptions/dependencies: confidentiality and on-prem deployment; downstream review for critical decisions; table extraction caveats
- Financial and insurance document intake (invoices, statements, claim forms)
- Sectors: finance, insurance
- Tools/workflows: pipeline extracting text, tables, and layout; reconciliation workflows; anomaly detection aided by structured context
- Assumptions/dependencies: table structure recognition is good but has known gaps vs top tools; domain-specific post-processing likely required
- Education content conversion (textbooks, problem sets, notes)
- Sectors: education, edtech
- Tools/workflows: conversion of textbooks to structured web content; math-aware study materials; digitization of handwritten Chinese class notes
- Assumptions/dependencies: handwriting accuracy varies by style and scan quality; content licensing
- Multilingual document processing (English + Chinese, incl. handwritten Chinese)
- Sectors: cross-border business, government, academia
- Tools/workflows: bilingual batch processing; cross-language archives; knowledge bases enriched with structure
- Assumptions/dependencies: current strong support for EN/ZH; limited guarantees for other languages/scripts
- Document QA and parsing validation using RL-derived metrics
- Sectors: software tooling, quality engineering
- Tools/workflows: automated QA that flags reading-order inversions, bounding-box mismatches, and high edit distance; “layout QA” dashboards
- Assumptions/dependencies: reference ground truths or heuristics; calibration of thresholds per document type
- Developer SDKs/APIs for document intelligence
- Sectors: software, platform ecosystems
- Tools/workflows: REST/gRPC services; Python SDK for batch conversions and structured outputs; integration modules for DMS/ECM systems
- Assumptions/dependencies: model and license availability; GPU provisioning; security/privacy controls
- Data labeling accelerators replicating the paper’s annotation pipeline
- Sectors: ML ops, data services
- Tools/workflows: automated pre-annotation (e.g., Mathpix), verification/correction (e.g., Gemini), and human-in-the-loop refinement; generation of gold-standard subsets
- Assumptions/dependencies: licensing and cost for third-party tools; workforce for human validation; privacy policies
Long-Term Applications
These applications build on the paper’s methods (SFT-then-RL, layout-centric reward design, hard-sample mining) and results, but require further research, scaling, or productization. They target broader domains and higher reliability/coverage.
- Cross-language expansion beyond EN/ZH (Arabic, Devanagari, Cyrillic, CJK variants)
- Sectors: global enterprise, government, academia
- Tools/workflows: multilingual training corpora; script-specific encoders/normalization
- Assumptions/dependencies: additional high-quality data; font/handwriting diversity; language-specific reading norms
- Multi-page and document-level structure reasoning (sections, references, TOC coherence)
- Sectors: publishing, legal, academia
- Tools/workflows: parsers that maintain continuity across pages; linking figures/tables to mentions; document graph construction
- Assumptions/dependencies: new rewards for cross-page flow; memory and context scaling; improved page-to-page segmentation
- Best-in-class table and math parsing for complex 2D layouts
- Sectors: finance, engineering, STEM publishing
- Tools/workflows: specialized modules for nested tables and aligned equations; table-to-structured data pipelines (CSV/Parquet)
- Assumptions/dependencies: augmented datasets; architectural innovations targeting 2D layout; stricter normalization/evaluation
- Chemical knowledge extraction beyond molecules (reactions, conditions, yields)
- Sectors: pharmaceuticals, materials science, chemical engineering
- Tools/workflows: reaction OCR to RXN/SMARTS; experiment protocol extraction; curation tools for chemists
- Assumptions/dependencies: new annotation schemas; domain ontologies; expert-in-the-loop validation
- Structure-aware RAG agents for scientific reasoning
- Sectors: academia, biotech, engineering
- Tools/workflows: agents that reference structured blocks with coordinates and formula semantics; citation-preserving summarization and grounded retrieval
- Assumptions/dependencies: reliable math/chem parsing; citation linking; long-context LLMs integrated with layout metadata
- Interactive PDF editors and remediation assistants with RL-guided suggestions
- Sectors: publishing, accessibility, enterprise content
- Tools/workflows: UI tools that propose reading-order fixes, bounding-box corrections; “human-in-the-loop RL” that learns from edits
- Assumptions/dependencies: UX productization; feedback loops; continuous learning infrastructure
- Robotic process automation (RPA) powered by layout-aware document intelligence
- Sectors: finance, insurance, supply chain, HR
- Tools/workflows: automated intake and workflow triggers based on structured blocks; exception handling with layout cues
- Assumptions/dependencies: reliability thresholds; compliance and auditability; domain-specific templates
- Policy and public-sector large-scale digitization of archives and legislation
- Sectors: government, public libraries
- Tools/workflows: standardized digitization pipelines; public-access semantic web publishing; historical newspaper/magazine programs
- Assumptions/dependencies: procurement and data governance; sustained funding; multi-language expansion
- On-device or edge deployment through model compression and distillation
- Sectors: mobile scanning apps, field operations
- Tools/workflows: quantized/distilled variants of Logics-Parsing; offline parsing for privacy-sensitive contexts
- Assumptions/dependencies: accuracy retention with compression; hardware constraints; incremental decoding optimizations
- Domain-specific copilot for contracts, technical manuals, and standards
- Sectors: legal, manufacturing, energy
- Tools/workflows: copilot that understands structured sections, tables, diagrams; compliance cross-referencing
- Assumptions/dependencies: domain corpora; improved diagram parsing; policy-aware reasoning
- Benchmark standardization and procurement evaluation using LogicsParsingBench
- Sectors: software vendors, public procurement
- Tools/workflows: formalized test suites and protocols (global text, strict normalization); vendor bake-offs
- Assumptions/dependencies: public release of benchmark; community adoption; extensions for additional domains
- Training methodology transfer: “SFT memorizes, RL generalizes” for other perception-to-structure tasks
- Sectors: broader ML research and product teams
- Tools/workflows: RL reward plugins for layout/order; hard-sample mining frameworks; generalized LC-RL recipes
- Assumptions/dependencies: task-specific rewards; reproducible pipelines; scalable RL infrastructure
Cross-cutting assumptions and dependencies
- Model availability and licensing: Qwen2.5-VL-7B-based model terms; compatibility with commercial deployments.
- Compute and performance: high-resolution inputs and long outputs require GPUs; throughput considerations for batch processing.
- Data privacy and governance: handling sensitive documents; need for on-prem or private-cloud options.
- Quality caveats: table and math parsing are strong but not uniformly best; reading order is much improved yet can trail certain commercial tools; domain-specific QA is recommended for critical workflows.
- Benchmarking: LogicsParsingBench is announced but not yet publicly released; interim evaluation may rely on OmniDocBench or proprietary sets.
- Extensibility: additional languages/scripts, multi-page coherence, and advanced domain semantics will require further data and reward engineering.
Glossary
- AGI: A hypothetical AI system with broad, human-level capabilities across tasks. "and ultimately the AGI."
- Autoregressive token-by-token supervision: Training where the model predicts the next token in a sequence, conditioning on previous tokens. "the autoregressive token-by-token supervision of SFT provides indirect and often insufficient signals for page structure learning."
- Bounding box coordinates: Numerical coordinates that localize an element (e.g., text block) within an image or page. "their corresponding bounding box coordinates."
- CLIP objective: A contrastive learning objective aligning images and text embeddings used in CLIP-like models. "the CLIP objective adopted by popular LVLMs' visual encoder"
- Dynamic resolution mechanism: A model capability to process inputs at varying resolutions without fixed-size constraints. "Qwen2-VL series have introduced the native dynamic resolution mechanism to eliminate the spatial constraints."
- Global Text Evaluation: An evaluation protocol that concatenates all page text for holistic comparison, reducing penalties from segmentation differences. "Global Text Evaluation: We claim that the commonly used block-by-block text matching evaluation would impose excessive penalty for minor differences in paragraph segmentation granularity."
- Group Relative Policy Optimization (GRPO): A reinforcement learning algorithm that optimizes policies using group-relative baselines. "employing Group Relative Policy Optimization (GRPO), which we find well-suited to this problem class."
- Hard-sample mining strategy: Selecting challenging training samples (neither too easy nor too hard) to focus learning where the model struggles. "we propose a novel hard-sample mining strategy"
- HTML annotation schema: A structured labeling format using HTML to encode document hierarchy and content types. "into our unified HTML annotation schema."
- Human-in-the-loop verification: A process where human experts review and correct automated annotations to improve quality. "followed by human-in-the-loop verification."
- Large Vision-LLMs (LVLM): Models that jointly process and reason over visual and textual modalities at large scale. "Recent advances in Large Vision-LLMs (LVLM) have spurred significant progress in document parsing task."
- Layout analysis: The task of identifying and modeling a document’s structural arrangement (columns, blocks, tables) on the page. "optimize complex layout analysis and reading order inference."
- Layout-Centric Reinforcement Learning (LC-RL): An RL stage focusing rewards and optimization on layout structure and reading order. "the Layout-Centric Reinforcement Learning (LC-RL) is introduced."
- Levenshtein distance: An edit-distance metric counting insertions, deletions, and substitutions between strings. "the negative normalized Levenshtein distance"
- Multi-component reward function: An RL reward constructed from multiple criteria (e.g., text accuracy, localization, order). "By employing a multi-component reward function that explicitly evaluates text accuracy, layout precision, and logical reading order"
- Next-token prediction objective: The standard language modeling loss that trains models to predict the next token. "the next-token prediction objective widely adopted in current LVLMs"
- Normalized Edit Distance (NED): Edit distance scaled to [0,1], enabling comparable text-error measurements across lengths. "we calculate Normalized Edit Distance (NED) between the predicted outputs and ground-truth references"
- Optical Character Recognition (OCR): Technology that converts text in images into machine-encoded text. "Optical Character Recognition (OCR)"
- Pairwise inversion count: A measure of how many pairwise orderings in a predicted sequence disagree with a reference sequence. "calculated as the pairwise inversion count between reference and predicted paragraphs."
- Policy optimization: The process in RL of improving a policy to maximize expected reward. "adopting GRPO for policy optimization."
- Reading order inference: Determining the correct sequence in which content on a page should be read. "the disruptive effects of complex layouts on reading order inference."
- Reinforcement learning (RL): A learning paradigm where agents learn by receiving rewards based on their actions. "augmented with reinforcement learning."
- Retrieval-augmented Generation (RAG): A method that augments generative models with retrieved external knowledge. "Retrieval-augmented Generation (RAG)"
- ROLL: A scaling library/framework used to implement reinforcement learning training. "implemented via the ROLL"
- Simplified Molecular Input Line Entry System (SMILES): A textual representation of chemical molecules. "the Simplified Molecular Input Line Entry System (SMILES) strings for chemical molecules."
- Spatial grounding: Linking recognized textual content to precise locations in the image/page space. "performs accurate text recognition and spatial grounding"
- Stricter Content Normalization: An evaluation normalization protocol emphasizing semantic accuracy over formatting. "Stricter Content Normalization: To ensure fair comparisons across heterogeneous model outputs, we implemented stricter normalization protocols, especially for tabular data."
- Supervised Fine-Tuning (SFT): Post-training a model on labeled data with supervised objectives to adapt it to a task. "Supervised Fine-Tuning (SFT) stage."
- Tree Edit Distance Similarity (TEDS): A metric comparing tree-structured data (e.g., table structures) via edit distance-based similarity. "Table TEDS "
- Vision encoder: The component of a VLM that processes images into visual features. "the parameters of the vision encoder and vision-language projector are frozen."
- Vision-LLM (VLM): A model that integrates visual and textual inputs for joint understanding and generation. "Rather than training a large-scale Vision-LLM (VLM) from scratch"
- Vision-language projector: The module mapping visual features into the LLM’s embedding space. "the parameters of the vision encoder and vision-language projector are frozen."
Collections
Sign up for free to add this paper to one or more collections.

