Multi-View Attention Multiple-Instance Learning Enhanced by LLM Reasoning for Cognitive Distortion Detection
Abstract: Cognitive distortions have been closely linked to mental health disorders, yet their automatic detection remained challenging due to contextual ambiguity, co-occurrence, and semantic overlap. We proposed a novel framework that combines LLMs with Multiple-Instance Learning (MIL) architecture to enhance interpretability and expression-level reasoning. Each utterance was decomposed into Emotion, Logic, and Behavior (ELB) components, which were processed by LLMs to infer multiple distortion instances, each with a predicted type, expression, and model-assigned salience score. These instances were integrated via a Multi-View Gated Attention mechanism for final classification. Experiments on Korean (KoACD) and English (Therapist QA) datasets demonstrate that incorporating ELB and LLM-inferred salience scores improves classification performance, especially for distortions with high interpretive ambiguity. Our results suggested a psychologically grounded and generalizable approach for fine-grained reasoning in mental health NLP.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching computers to spot “cognitive distortions” in text—unhelpful thinking patterns like “I always mess up” or “If I’m not perfect, I’m a failure.” The goal is to help identify these patterns quickly and clearly, which could support mental health work. The researchers built a new system that uses powerful AI LLMs plus a clever way of combining clues from a sentence to figure out what kind of distortion is present.
What are cognitive distortions?
Cognitive distortions are common thinking errors that can make people feel worse. Examples include:
- All-or-Nothing Thinking: seeing things as totally good or totally bad (“If I fail one test, I’m a complete failure.”)
- Jumping to Conclusions: assuming something negative without proof (“She didn’t text back—she must be angry.”)
- Personalization: blaming yourself for things outside your control (“My friend seems sad; I must have done something.”)
Key Objectives
In simple terms, the researchers wanted to answer:
- Can AI detect different types of cognitive distortions in text more accurately?
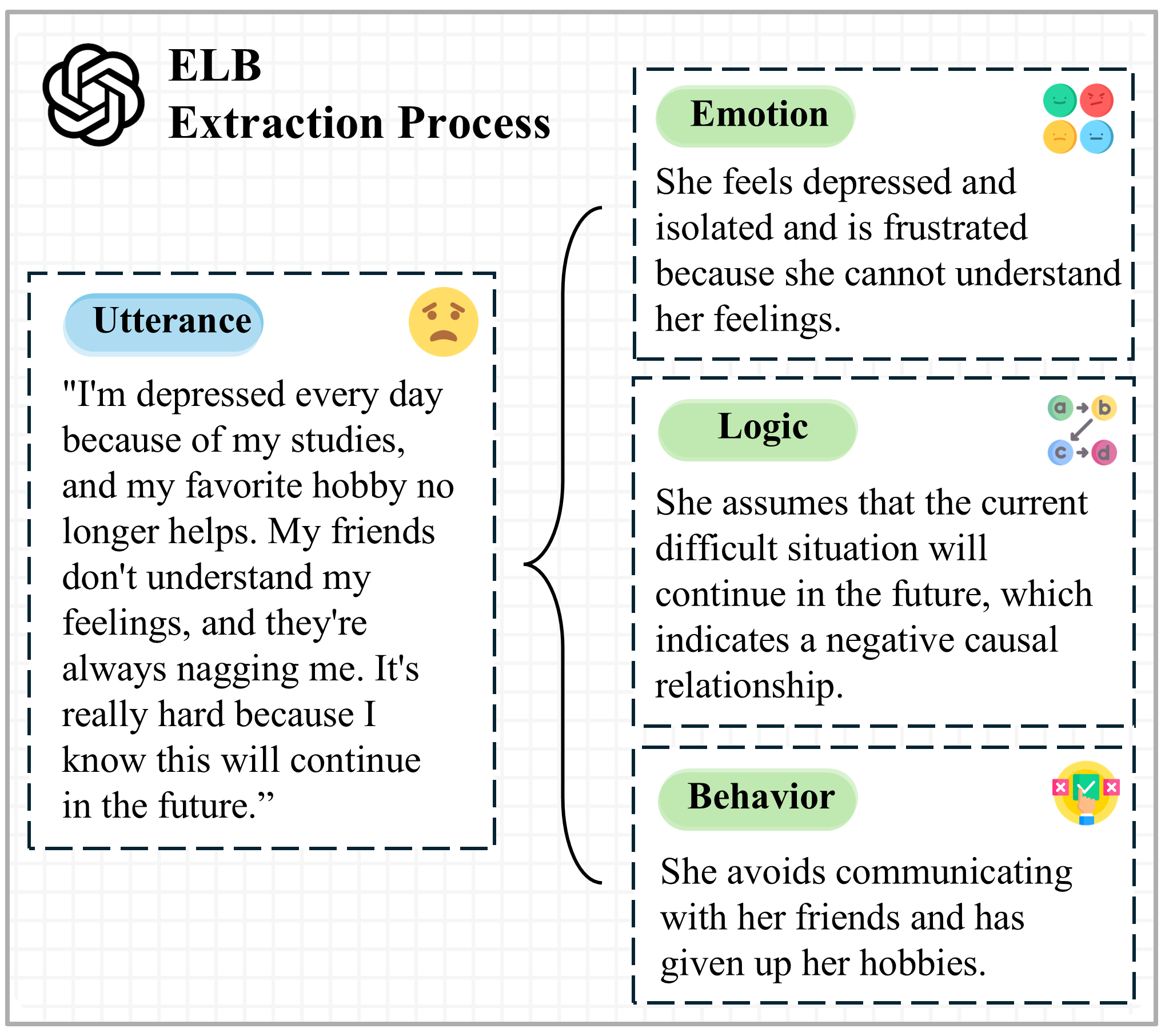
- Can breaking a sentence into parts—Emotion, Logic, and Behavior (ELB)—help the AI understand what’s really going on?
- Can we make the AI’s reasoning more understandable, especially when multiple distortions show up in the same sentence?
Methods: How Did They Do It?
First, here’s the big idea: instead of treating a whole sentence as one lump, the system looks for several “mini-evidences” inside the sentence and then decides which distortion fits best.
To do this, they:
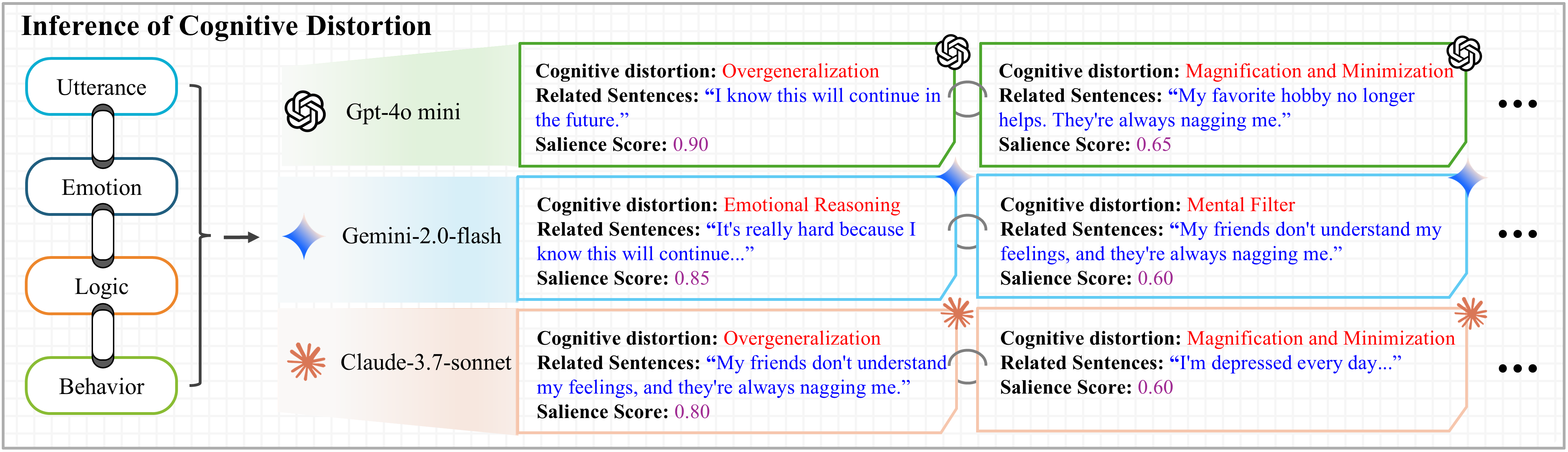
- Used three LLMs—like GPT-4, Gemini, and Claude—to analyze each sentence.
- Broke each sentence into three parts called ELB:
- Emotion: how the person feels (“I feel anxious.”)
- Logic: the person’s reasoning or belief (“I think failing once means I’m a failure.”)
- Behavior: what they do or plan to do (“I’m going to stop trying.”)
- Asked the LLMs to find possible distortion “instances,” each with: 1) A predicted distortion type (like “All-or-Nothing Thinking”), 2) The exact text snippet that shows it, 3) A “salience score,” which is a number showing how important or convincing that snippet is.
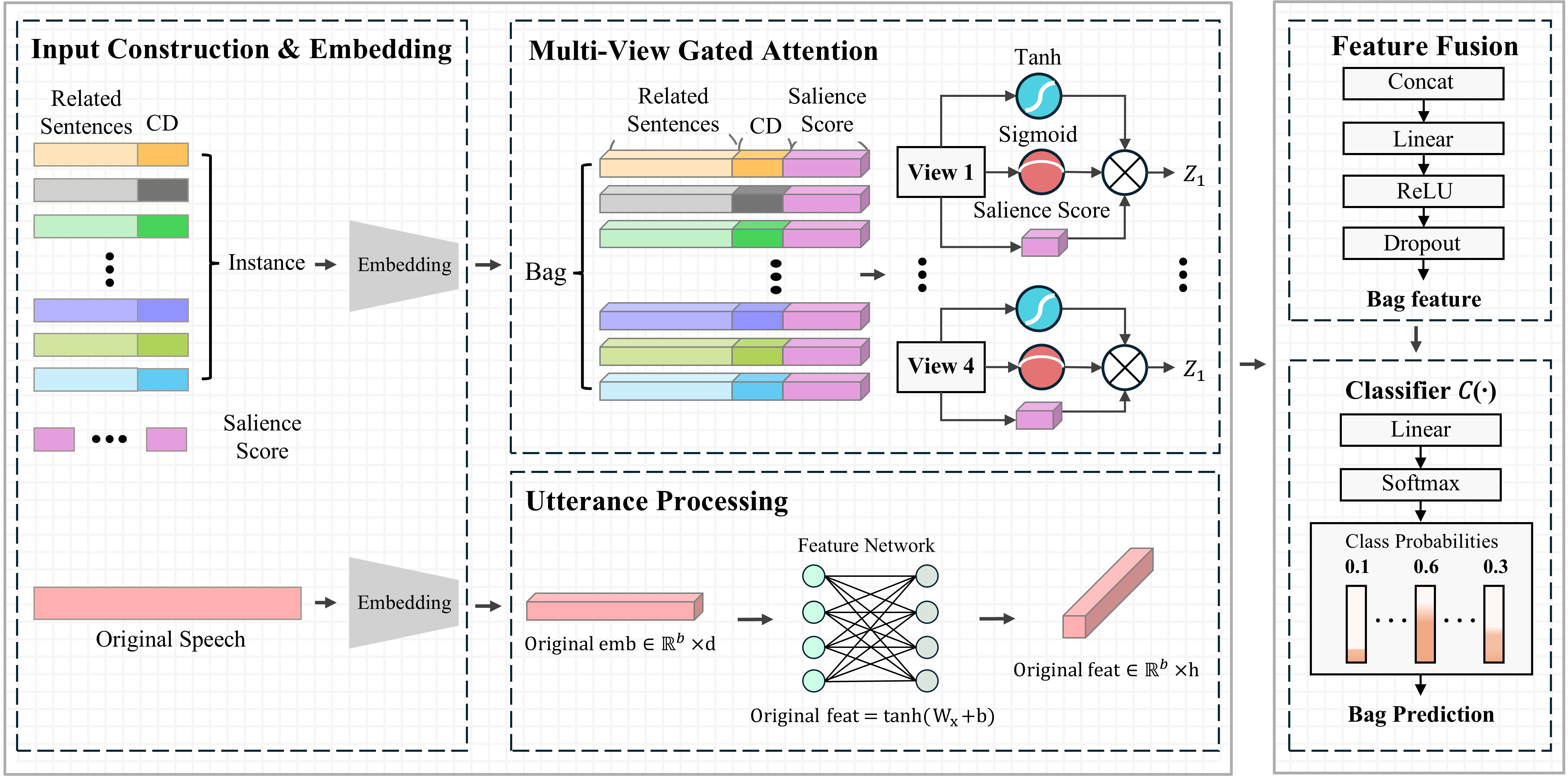
Then they combined all these clues using a method called Multiple-Instance Learning (MIL). Think of it like this:
- Imagine a sentence is a backpack (a “bag”).
- Inside the backpack are several note cards (the “instances”)—each note card points to a possible distortion with a highlighted sentence bit and an importance score.
- The model looks at all the note cards together and decides which distortion label best fits the full sentence.
To make this combination smarter, they used “Multi-View Gated Attention,” which you can think of as:
- Several judges (views) each shining a spotlight (attention) on the note cards they think matter most.
- A gate is like a filter that decides how much a card’s features should count.
- The salience score is like a bright highlighter: the brighter it is, the more the spotlight pays attention.
- The judges’ opinions are averaged to form the final decision.
They also used “embeddings,” which means turning sentences and instances into numbers so the computer can compare them. Finally, they tested their system on two datasets:
- KoACD: Korean counseling texts from teenagers (4,510 labeled sentences).
- Therapist QA: English patient–therapist Q&A texts (1,597 labeled sentences).
Main Findings
Here are the key results and why they matter:
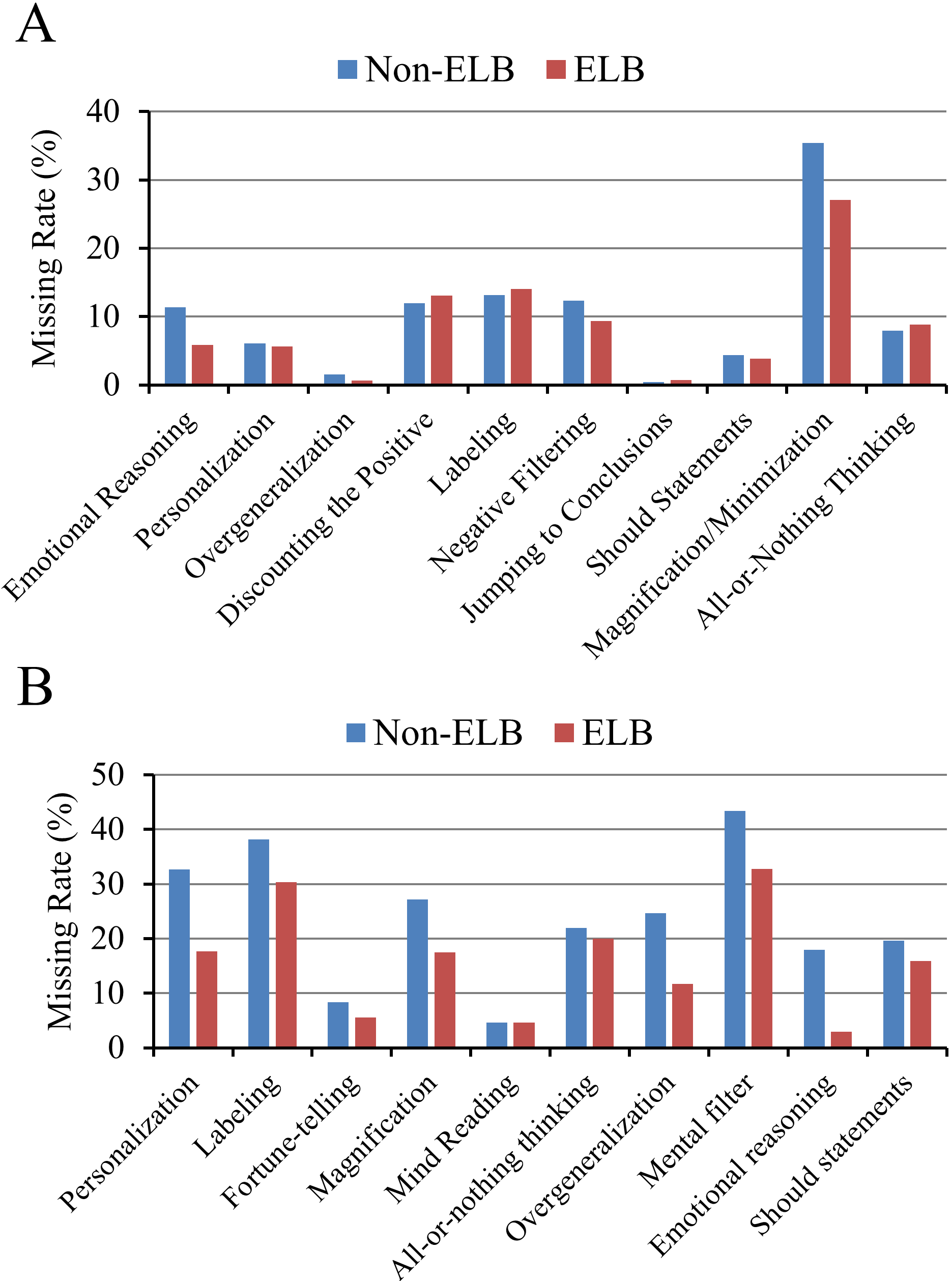
- Breaking sentences into ELB helped the AI find the right labels more often. For example, in the Korean dataset, the “missing rate” (cases where none of the instances included the true label) dropped overall from about 10.9% to 8.9% when ELB was used. In the English dataset, “Emotional Reasoning” missing rate dropped dramatically (from about 17.9% to 3.0%).
- Using both ELB and salience scores produced the best performance:
- KoACD test F1-score (a measure of accuracy) improved to about 0.505.
- Therapist QA test F1-score improved to about 0.394, beating a prior method that scored ~0.346.
- Some distortion types were easier to detect than others:
- “Should Statements” did particularly well.
- More vague or emotion-heavy types like “Emotional Reasoning” were harder, especially in English.
- The method handled overlapping distortions better, since multiple instances can be considered at once.
Why this is important: mental health texts are tricky. People’s words can carry more than one distortion, and some distortions sound very similar. This system looks at multiple small clues and weighs them, leading to better and more explainable results.
Implications and Impact
In simple terms, this research shows a new way to teach computers to understand complex, messy human thinking patterns:
- It could help mental health tools flag unhelpful thought patterns earlier and more clearly, supporting therapists, counselors, and self-help apps.
- The ELB breakdown makes the system’s reasoning easier to follow—useful for building trust and understanding in real-world mental health settings.
- It works across languages (Korean and English), suggesting it can be generalizable.
At the same time, the authors note limits:
- Some subtle or emotional distortions are still hard to detect.
- The system is not a medical diagnosis tool—any real-world use should be supervised by trained professionals.
- Future improvements could focus on better balancing how instances are generated and improving explanations of final decisions.
Overall, this approach—combining ELB, LLM reasoning, and MIL attention—offers a more thoughtful and interpretable path toward understanding how people express cognitive distortions in text.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Multi-label learning mismatch: KoACD uses single-label bags despite acknowledged co-occurrence of distortions; extend the MIL head to true multi-label objectives and evaluate with multi-label metrics.
- Therapist QA labeling handling: The dataset allows up to two labels per utterance, but the model uses softmax cross-entropy; clarify target construction and report multi-label results (e.g., micro/macro F1, subset accuracy).
- Lack of instance-level ground truth: No human-validated annotations for expression spans/types/salience; create a small gold set to directly evaluate instance extraction precision/recall and salience validity.
- Salience calibration and robustness: LLM-assigned salience scores are unvalidated; measure correlation with clinician-rated importance, test robustness to miscalibrated/noisy salience, and explore learning-to-weight or calibrating salience (e.g., temperature scaling, isotonic regression).
- Ensemble ablation and conflict resolution: Quantify each LLM’s contribution, develop principled methods to reconcile contradictory instances across models (e.g., voting, confidence aggregation, deduplication), and analyze sensitivity to LLM choice.
- Reproducibility of LLM stages: Proprietary LLMs and prompt-based extraction risk non-determinism and model drift; report version control, seeds, and variance across model updates; compare with open-source LLMs for replicability.
- ELB extraction validity: The ELB decomposition (Emotion–Logic–Behavior) is not validated against human judgements; measure inter-rater agreement vs LLM outputs, and quantify downstream performance sensitivity to ELB quality/errors.
- Language-specific embeddings: The embedding model (all-MiniLM-L12-v2) may be suboptimal for Korean; compare multilingual/Korean-specific sentence embeddings and fine-tuned encoders versus frozen features.
- End-to-end learnable generation: Current two-stage pipeline (LLM generation → MIL) is not trained jointly; explore trainable/lightweight generators or RL to optimize instance quality and missing-rate end-to-end.
- Contextual breadth: Only single-utterance inputs are modeled; extend to multi-turn conversational context and speaker metadata to capture discourse cues and evolving distortions.
- Instance imbalance and attention bias: The MIL attends more to types with abundant instances; develop type-aware regularization, reweighting, or constrained attention to prevent over-focusing on frequent types.
- Alternative MIL aggregators: Ablate number of views K, gating vs non-gated attention, transformer-based set encoders, Deep Sets, and max/mean pooling; analyze sensitivity and stability across aggregation choices.
- Salience integration form: Multiplicative gating by s_i may oversuppress useful signals; compare additive integration, learned gating, clipping/normalization strategies, and per-type calibration of salience.
- Baseline breadth: Benchmark against strong fine-tuned transformers (e.g., multi-label RoBERTa/BERT), span-rationale models, hierarchical classifiers, and sequence tagging baselines, not just DoT prompting.
- Error and confusion diagnostics: Provide confusion matrices and qualitative analyses of commonly confused types; explore hierarchical label structures, metric learning, or label-graph regularization to separate semantically overlapping types.
- Instance generation controls: Specify and study the policy for number of instances per bag (min/max, stopping criteria, thresholds), and its effect on precision/recall; introduce pruning by diversity/uncertainty measures.
- Quality-aware instance selection: More instances do not guarantee better performance; design selection mechanisms that prioritize informative, non-redundant instances (e.g., determinantal point processes, diversity-promoting penalties).
- Robustness to distribution shift: Test paraphrases, adversarial rewordings, slang/code-switching, and out-of-domain sources (e.g., forums, clinical notes) to assess robustness and generalization.
- Population and domain coverage: Current datasets target Korean adolescents and public English Q&A; evaluate on broader age groups, cultures, clinical settings, and additional languages to assess external validity.
- Interpretability validation with clinicians: Conduct user studies to rate instance relevance, perceived faithfulness, and decision-support value; measure whether ELB + instance rationales improve clinician judgments.
- Fairness and harm analysis: Assess performance disparities across demographic groups (age, gender, culture) and analyze potential harms from misclassification; propose mitigation strategies and uncertainty-aware abstention.
- Calibration and uncertainty at bag level: Report calibration metrics (ECE/Brier), provide confidence intervals, and implement selective prediction/abstention policies for high-stakes decisions.
- Data contamination risk: Evaluate whether LLMs were exposed to the benchmark data during pretraining; run contamination checks or use held-out/private test sets.
- Cross-dataset taxonomy alignment: Label sets differ across datasets (e.g., Negative Filtering vs Mental Filter); formalize mappings, learn a shared latent taxonomy, and test transfer learning with aligned labels.
- Metric completeness: Include per-class AUPRC and macro-averaged metrics to better reflect rare/ambiguous types; for Therapist QA, report multi-label metrics explicitly.
- Mathematical clarity: Equations for multi-view aggregation and fusion contain bracket/notation typos; clarify whether raw or normalized salience is used in Eq. (3) and ensure consistent definitions across sections.
- Efficiency and cost: Running three LLMs per utterance is expensive; quantify latency and monetary cost, and evaluate lightweight approximations (distilled generators, retrieval-augmented prompts, smaller models) with cost–performance trade-offs.
- Privacy and deployment pathways: Outline requirements for privacy-preserving inference (on-device/edge, federated processing) and human-in-the-loop triage protocols for real-world deployment.
Practical Applications
Overview
Based on the paper’s Multi-View Attention MIL framework augmented by LLM-based reasoning and ELB (Emotion–Logic–Behavior) decomposition, below are practical applications grouped by deployment horizon. Each application notes relevant sectors, potential tools/workflows, and key assumptions or dependencies impacting feasibility.
Immediate Applications
- Cognitive distortion tagging and summarization for therapists
- Sectors: healthcare, software
- Tools/workflows: ELB extractor microservice; LLM ensemble to produce instance-level types and salience; multi-view MIL classifier; EHR/telehealth plugin that highlights segments (e.g., “Should statements,” “Personalization”) and provides brief, evidence-based rationales
- Dependencies: clinician oversight; HIPAA/PHI compliance; prompt stability across cases; threshold tuning to minimize false positives; acceptance by clinical workflows
- Digital journaling and self-help apps that flag distortions in user entries
- Sectors: consumer health/wellness, software
- Tools/workflows: in-app ELB decomposition of entries; instance-level distortion detection; lightweight suggestions for cognitive restructuring; weekly dashboards tracking distortion trends
- Dependencies: clear disclaimers (not a diagnosis tool); data privacy consent; culturally appropriate feedback; latency/cost considerations for LLM calls
- Helpline and chat triage assistants for mental-health support services
- Sectors: healthcare, public health
- Tools/workflows: real-time ingestion of messages; ELB + LLM instance generation; MIL risk scoring; alerts to moderators when high-salience patterns co-occur (e.g., “Emotional reasoning” + “Magnification”)
- Dependencies: staffing for human-in-the-loop review; guardrails to prevent over-escalation; robust performance under noisy text; SLA for latency
- CBT training simulators and annotation practice for clinicians-in-training
- Sectors: education, healthcare
- Tools/workflows: interactive labeling exercises using KoACD/Therapist QA-like materials; automated feedback guided by ELB and multi-view attention; case-based learning with ambiguous labels and rationales
- Dependencies: curricular integration; access to annotated examples; consensus guidelines on cognitive distortion taxonomies
- Research-grade annotation accelerators for psychology/NLP labs
- Sectors: academia
- Tools/workflows: ELB-assisted pre-annotation pipelines; salience-weighted candidate labels; human adjudication UI to resolve co-occurrence/ambiguity; reproducible scripts with
all-MiniLM-L12-v2embeddings - Dependencies: inter-annotator agreement protocols; budget for LLM inference; versioning and documentation to ensure replicability
- Workplace well-being analytics for HR/EAP programs
- Sectors: enterprise HR, software
- Tools/workflows: analysis of anonymized employee feedback; periodic reports on distortion prevalence (e.g., “All-or-nothing thinking”); recommended psychoeducational content
- Dependencies: strict consent and privacy; non-clinical positioning; fairness and bias auditing; governance to avoid surveillance concerns
- Conversational coaching for customer support and sales teams
- Sectors: customer experience, software
- Tools/workflows: real-time assistant that flags distorted phrasing in agent or customer messages and suggests reframes (e.g., mitigating “Overgeneralization”)
- Dependencies: domain adaptation beyond clinical text; UX guardrails to avoid intrusive feedback; measurement of impact on outcomes
- Multilingual monitoring in Korean and English contexts
- Sectors: healthcare, public health, software
- Tools/workflows: dual-language ELB prompts; cross-lingual instance aggregation; dashboards comparing distortion profiles by language/community
- Dependencies: cultural/linguistic calibration; differing label distributions by language; bias evaluations across demographics
- Writing assistant for emails and messages that highlights distortions
- Sectors: productivity software, education
- Tools/workflows: browser/IDE extension; inline ELB parsing; gentle prompts to reconsider “Jumping to conclusions” or “Labeling”
- Dependencies: user acceptance; false positive suppression; privacy (client-side inference preferred)
- Instrumentation for clinical studies (pre/post intervention measurement)
- Sectors: academia, clinical research
- Tools/workflows: standardized pipelines to score distortion frequency/severity; per-type F1-based confidence reporting; exportable metrics for RCT analysis
- Dependencies: IRB approval; validated outcome measures; documented reliability and external validity
Long-Term Applications
- Clinical decision support integrated into EHR/telepsychiatry
- Sectors: healthcare
- Tools/workflows: longitudinal distortion profiling; alerts for persistent high-salience patterns; integration with safety plans
- Dependencies: prospective clinical validation; regulatory approval; continuous monitoring for drift; robust explainability beyond attention weights
- Personalized CBT program sequencing based on distortion profiles
- Sectors: healthcare, education
- Tools/workflows: adaptive therapy modules targeting frequent distortions (e.g., “Should statements”); dynamic homework tailored by ELB-derived patterns
- Dependencies: longitudinal efficacy studies; interoperability with digital therapeutics; clinician acceptance and training
- Population-level mental health surveillance (opt-in, privacy-preserving)
- Sectors: public health, policy
- Tools/workflows: federated pipelines across platforms; trend analysis of distortion prevalence; public dashboards informing outreach campaigns
- Dependencies: ethical frameworks and consent; differential privacy; fairness and equity audits; governance to prevent misuse
- Standardization of cognitive distortion taxonomies, benchmarks, and tooling
- Sectors: academia, policy
- Tools/workflows: shared multilingual datasets; benchmark suites that include ELB decomposition and instance-level salience; community scoring guidelines
- Dependencies: expert consensus; funding for dataset curation; sustained maintenance and versioning
- On-device, privacy-first ELB + MIL models for low-resource settings
- Sectors: software, global health
- Tools/workflows: distilled LLMs and compact MIL architectures; edge inference for offline contexts; localizable prompts and UI
- Dependencies: model compression without performance collapse; hardware constraints; careful UX in low-connectivity environments
- Culturally adaptive models for diverse populations
- Sectors: global health, education
- Tools/workflows: region-specific prompt templates; localization of distortion definitions; community co-design and evaluation
- Dependencies: broad, representative datasets; sociocultural expertise; continuous calibration to evolving language norms
- Advanced interpretability with quantitative, psychologically grounded explanations
- Sectors: healthcare, AI safety
- Tools/workflows: counterfactuals, causal attributions linking ELB components to predictions; clinician-facing explanation scores aligned with CBT theory
- Dependencies: research on explanation validity; user studies with clinicians; integration into documentation and audit trails
- Regulatory and auditing frameworks for AI in mental health
- Sectors: policy/regulation
- Tools/workflows: standards for error rates, bias, and harms; model cards with ELB/MIL-specific disclosures; post-deployment monitoring requirements
- Dependencies: multi-stakeholder consensus; alignment with GDPR/HIPAA and local laws; enforcement capacity
- School-based mental wellbeing tools and curricula
- Sectors: education, public health
- Tools/workflows: student journaling platforms that flag distortions; teacher guidance materials; privacy-first analytics for classroom well-being
- Dependencies: parental consent; age-appropriate design; educator training; safeguarding protocols
- Decision journaling in finance to mitigate cognitive distortions in trading/investing
- Sectors: finance, productivity software
- Tools/workflows: ELB-based reflection prompts; distortion detection in trading notes; nudge-based reframes prior to high-stakes decisions
- Dependencies: domain adaptation to financial language; institutional compliance; evidence of impact on risk management
- Voice-based distortion detection in calls (ASR + ELB + MIL)
- Sectors: telehealth, contact centers
- Tools/workflows: speech-to-text integration; real-time ELB decomposition; instance-level alerts for supervisors or clinicians
- Dependencies: ASR accuracy across accents/noise; latency constraints; privacy and consent for call recording
- Therapeutic alliance analytics and progress tracking
- Sectors: healthcare
- Tools/workflows: trends in distortion types over time; correlation with symptom measures; clinician dashboards for shared decision-making
- Dependencies: validated metrics linking distortion change to outcomes; careful interpretation to avoid overfitting; robust handling of co-occurrence and ambiguity
Cross-Cutting Assumptions and Dependencies
- Access to reliable LLMs (e.g., GPT-4o, Gemini Flash, Claude 3.7) and cost-effective inference; stability of prompt templates and ELB extraction quality
- Data privacy, consent, and compliance (HIPAA/GDPR/locally applicable regulations); strong anonymization and security practices
- Cultural and linguistic adaptation (distortion definitions and examples can vary across languages/contexts)
- Human-in-the-loop review for any high-stakes or clinical setting; clear user-facing disclaimers
- Fairness and bias evaluation across demographics; monitoring for performance drift over time
- Need for improved interpretability beyond attention weights (quantitative explanations), and better balancing of instance generation across types
- Real-time latency and scalability constraints in production; robust handling of noisy, multi-turn conversational data
Glossary
- all-MiniLM-L12-v2: A compact transformer-based sentence embedding model that produces fixed-length vector representations. "using the {all-MiniLM-L12-v2} model"
- All-or-Nothing Thinking: A cognitive distortion that frames situations in binary terms (e.g., perfect vs. failure). "All-or-Nothing Thinking"
- Attention-based MIL: A Multiple-Instance Learning variant that uses attention mechanisms to weigh instance contributions within a bag. "attention-based MIL has been applied to fake news detection with improvements in precision and interpretability"
- Bag: In MIL, a collection of instances treated as a single unit for supervision and prediction. "in which an utterance is defined as a bag, and each of the multiple cognitive distortion expressions inferred by an LLM is considered as an instance"
- Bag-level prediction: The MIL practice of predicting a label for the entire bag rather than individual instances. "Multiple-Instance Learning (MIL) is a weakly supervised framework in which multiple instances are grouped into a single bag and a prediction is made at the bag level."
- Bag-instance mismatch: A discrepancy between bag-level labels and instance-level signals that complicates MIL training. "mutual-attention models have been used to address bag-instance mismatch in hate speech classification"
- CBT cognitive triangle: A psychological framework linking thoughts, emotions, and behaviors. "This decomposition draws on the CBT cognitive triangle"
- Cross-entropy loss: A standard objective function for multi-class classification that measures the difference between predicted and true distributions. "Model training was guided by the standard cross-entropy loss for multi-class classification."
- Diagnosis of Thought (DoT): A structured prompting approach for LLMs to interpret cognitive distortions more transparently. "The Diagnosis of Thought (DoT) framework introduced a structured prompting approach to improve interpretability"
- Discounting the Positive: A distortion where positive aspects are downplayed or dismissed. "Discounting the Positive"
- Domain-adaptive LLMs: Pretrained LLMs fine-tuned or adapted for performance in specific domains. "and domain-adaptive LLMs."
- Early stopping: A training regularization technique that halts training when validation performance no longer improves. "Early stopping was applied if the validation loss did not improve for 10 consecutive epochs."
- Emotion, Logic, and Behavior (ELB): A structured decomposition of utterances into three components to improve interpretability and inference. "we decomposed it into three components—Emotion, Logic, and Behavior (ELB)."
- Emotional Reasoning: A distortion where feelings are treated as evidence of truth. "Emotional Reasoning"
- Fortune-telling: A distortion involving predicting negative outcomes without sufficient evidence. "Fortune-telling"
- Gated Attention: An attention mechanism that uses gating (e.g., sigmoid) to modulate instance importance. "we adopted a gated attention mechanism inspired by prior work on attention-based MIL"
- Jumping to Conclusions: A distortion where negative judgments are made prematurely or without evidence. "Jumping to Conclusions"
- Label imbalance: Uneven distribution of classes that can hinder model performance and learning. "these approaches struggled with label imbalance and semantic overlap in multi-class scenarios."
- Labeling: A distortion that assigns a global negative label to oneself or others. "Labeling"
- LLMs: High-capacity neural models trained on vast text corpora for language understanding and generation. "LLMs"
- Linear projection: A learned affine transformation applied to embeddings or features. "passed through a linear projection followed by ReLU activation"
- Manifold regularization: A technique that leverages data geometry to improve generalization in weakly supervised settings. "Approaches such as manifold regularization"
- Mental filter: A distortion focusing only on negative details while ignoring positives. "Mental filter"
- mi-SVM: A Multiple-Instance Learning adaptation of Support Vector Machines that handles bag-level labeling. "mi-SVM, MILBoost, and other instance-level classifiers"
- MILBoost: A boosting-based algorithm tailored for Multiple-Instance Learning. "mi-SVM, MILBoost, and other instance-level classifiers"
- Mind Reading: A distortion assuming knowledge of others’ thoughts or intentions without evidence. "Mind Reading"
- Multiple-Instance Learning (MIL): A weakly supervised paradigm where labels apply to bags of instances instead of individual instances. "Multiple-Instance Learning (MIL) is a weakly supervised framework"
- Multi-label classification: A setup where each sample can be assigned multiple labels simultaneously. "later work introduced multi-label classification"
- Multi-turn interactions: Modeling conversational context across multiple dialog turns to improve continuity and prediction. "modeling multi-turn interactions to improve continuity and prediction"
- Multi-View Gated Attention: An architecture computing attention from multiple independent views to capture diverse instance signals. "These instances were integrated via a Multi-View Gated Attention mechanism for final classification."
- Mutual-attention: An attention variant that jointly models relationships to mitigate bag-instance issues. "mutual-attention models have been used"
- Negative Filtering: A distortion that exclusively focuses on negative aspects, ignoring positives. "Negative Filtering"
- Non-linear projection: A transformation using nonlinear activation functions to map embeddings into new feature spaces. "is first transformed using a non-linear projection"
- Normalization (salience score normalization): Scaling scores so their sum equals one to reflect relative importance. "Each instance’s salience score is normalized to reflect its relative importance within the model."
- One-hot encoded: A label representation where only the index of the true class is marked as 1 and others as 0. "Bag labels were one-hot encoded for loss computation only but were not included in the input embeddings."
- Overgeneralization: A distortion where broad conclusions are drawn from a single event. "Overgeneralization"
- Personalization: A distortion assigning excessive responsibility or blame to oneself. "Personalization"
- ReLU activation: A nonlinear function max(0, x) commonly used in deep networks. "followed by ReLU activation"
- Salience score: A model-produced weight indicating the perceived importance of an instance. "a salience score assigned by the LLM"
- Sentence embedding: A fixed-length vector representation of an entire sentence. "Each bag consisted of a sentence embedding vector for the original utterance"
- Should Statements: A distortion imposing rigid rules or expectations on oneself or others. "Should Statements"
- Sigmoid gate: A gating mechanism using a sigmoid function to modulate feature contributions. "The sigmoid gate modulates the transformed feature vector from the tanh layer"
- Softmax classifier: A final layer that converts logits to a probability distribution over classes. "The final prediction was obtained by applying a softmax classifier over the fused bag-level representation."
- Tanh activation: A nonlinear function mapping inputs to (-1, 1), used in feature transformations. "represent the sigmoid and tanh activations"
- Weighted aggregation: Combining instance representations using weights (e.g., salience) to form a bag-level summary. "weighted aggregation within the MIL structure"
- Weighted average F1 score: The F1 metric averaged across classes with weights proportional to class support. "weighted average F1 score across 10 runs."
- Zero-shot prompting: Guiding an LLM to perform a task without task-specific labeled training data. "extracted using a zero-shot prompting strategy based on GPT-4"
Collections
Sign up for free to add this paper to one or more collections.

