- The paper introduces the DIQA-5000 dataset and DocIQ model, addressing document-specific quality challenges.
- The methodology features a layout fusion downsampler and a multi-level feature fusion module that captures both fine details and semantic structure.
- Experimental results show that DocIQ outperforms conventional IQA methods in handling distortions like blur, shadow, and occlusion.
Detailed Summary of "DocIQ: A Benchmark Dataset and Feature Fusion Network for Document Image Quality Assessment"
Introduction
The paper "DocIQ: A Benchmark Dataset and Feature Fusion Network for Document Image Quality Assessment" addresses the vital task of assessing the quality of document images, a critical requirement for applications such as optical character recognition (OCR), document restoration, and more. Traditional image quality assessment (IQA) frameworks, primarily designed for natural scenes, do not adequately address the unique challenges posed by document images. These include structural and semantic complexities that demand specialized datasets and assessment models. To bridge this gap, the researchers propose a new dataset, DIQA-5000, and a novel model, DocIQ, which together offer a robust framework for document image quality assessment.
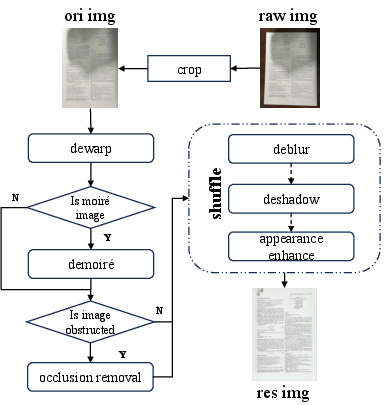
Figure 1: Document image processing pipeline. Each stage includes multiple available methods—dewarp (3 options), demoiré (2), occlusion removal (2), deblur (3), deshadow (4), and appearance enhancement (9)—and different processing flows are generated through random combinations.
The DIQA-5000 Dataset
DIQA-5000 is a comprehensive dataset specifically designed for document image quality assessment. It comprises 5,000 document images, each generated by applying various enhancement techniques to real-world images with distortions such as shadow, occlusion, blurring, creasing, and moiré patterns. Each image is subjectively rated by multiple individuals across three dimensions: overall quality, sharpness, and color fidelity. This multi-dimensional approach not only captures diverse perceptions of image quality but also supports the development of models capable of evaluating distinct quality aspects.
DocIQ Model Architecture
The DocIQ model offers a tailored solution for DIQA by integrating both document-specific features and advanced deep learning paradigms. At the core of DocIQ is a feature fusion module that aggregates multi-scale information from a hierarchical network. This module effectively blends low-level features, crucial for fine details, with high-level semantic representations necessary for understanding document structure and content.
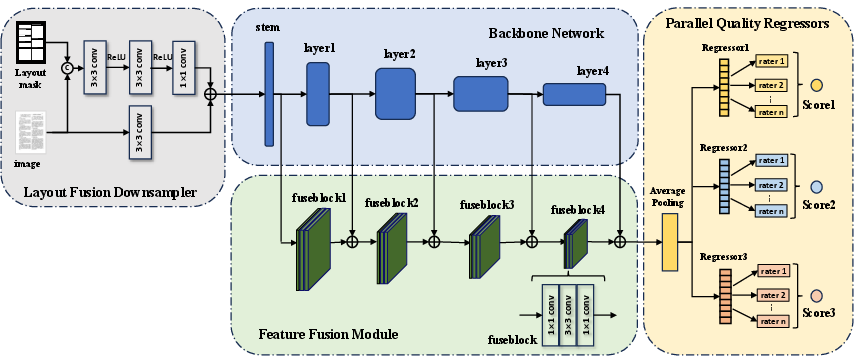
Figure 2: The network architecture of the proposed DocIQA model, which consists of 4 key components.
Key Components of the DocIQ Model
- Layout Fusion Downsampler: This component enhances computational efficiency by downsampling images while preserving layout-specific semantical features. It uniquely processes both the raw image and an associated layout mask to focus on critical document regions.
- Feature Fusion Module: By fusing multi-level features across different stages of the backbone network, this module enhances the model's capacity to encapsulate essential visual characteristics, thereby improving the accuracy of quality assessments.
- Parallel Quality Regressors: These independent modules facilitate multi-dimensional quality prediction by assigning separate regression tasks for different quality dimensions. This configuration allows the model to capture diverse quality nuances and provides robustness against varying perceptual biases among human raters.
Experimental Evaluation
Through extensive experiments, the proposed DocIQ model demonstrated superior performance compared to existing state-of-the-art IQA methods, particularly in the context of document images. The evaluation highlighted DocIQ's ability to generalize across different datasets, bolstered by its incorporation of semantic and geometric insights specific to document layouts. The novel use of a multi-head regression architecture significantly enhances its predictive reliability and versatility.
Conclusion
The introduction of the DIQA-5000 dataset and the DocIQ model represents a significant advancement in document image quality assessment. By addressing the limitation of existing IQA frameworks for document images, this work lays a robust foundation for future research and applications in various domains that rely on digital document processing. The methodologies and insights presented could inform the development of even more sophisticated models capable of handling complex document quality assessment challenges in the future.