Teaching LLMs to Plan: Logical Chain-of-Thought Instruction Tuning for Symbolic Planning
Abstract: LLMs have demonstrated impressive capabilities across diverse tasks, yet their ability to perform structured symbolic planning remains limited, particularly in domains requiring formal representations like the Planning Domain Definition Language (PDDL). In this paper, we present a novel instruction tuning framework, PDDL-Instruct, designed to enhance LLMs' symbolic planning capabilities through logical chain-of-thought reasoning. Our approach focuses on teaching models to rigorously reason about action applicability, state transitions, and plan validity using explicit logical inference steps. By developing instruction prompts that guide models through the precise logical reasoning required to determine when actions can be applied in a given state, we enable LLMs to self-correct their planning processes through structured reflection. The framework systematically builds verification skills by decomposing the planning process into explicit reasoning chains about precondition satisfaction, effect application, and invariant preservation. Experimental results on multiple planning domains show that our chain-of-thought reasoning based instruction-tuned models are significantly better at planning, achieving planning accuracy of up to 94% on standard benchmarks, representing a 66% absolute improvement over baseline models. This work bridges the gap between the general reasoning capabilities of LLMs and the logical precision required for automated planning, offering a promising direction for developing better AI planning systems.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching LLMs—the kind of AI behind chatbots—to make careful, step‑by‑step plans that follow strict rules. The authors create a training method called PDDL‑Instruct that helps an LLM not only suggest a plan, but also explain each step logically and check that the step is allowed by the rules. Think of it like training a student to show their work in math and use a calculator to verify each step.
What the researchers wanted to find out
The authors set out to answer a few simple questions:
- Can we train LLMs to plan well in rule‑based worlds (like puzzles or games) by making them show logical steps?
- Does giving the model detailed feedback (exactly what was wrong) help more than just saying “right” or “wrong”?
- Will this approach work across different types of planning problems?
How they did it (in everyday language)
First, a quick idea of the problem:
- Planning here is like solving a puzzle where you start in one situation and want to reach a goal by doing a sequence of actions. Each action has:
- Preconditions: what must be true before you can do it (like “you must have the key before opening the door”).
- Effects: what changes after you do it (like “the door becomes open, and the key may be used up”).
- The rules and problems are written in a formal language called PDDL. You can think of PDDL like the official rulebook for a board game: it exactly defines what moves are legal and what they do.
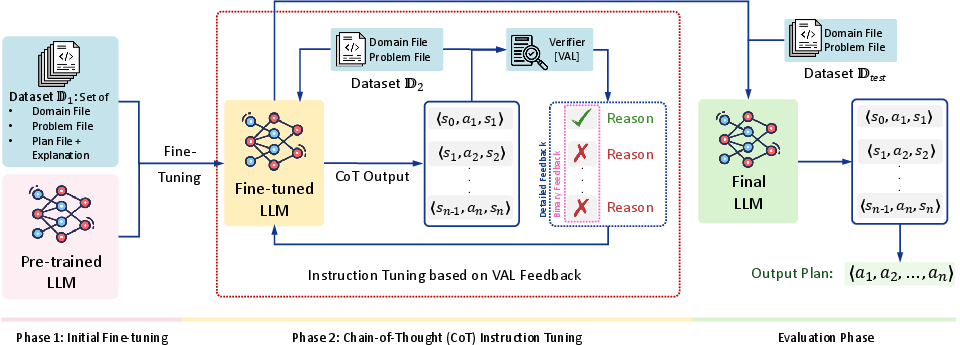
The training method has two big phases:
- Initial Instruction Tuning (teaching by examples)
- The model is shown planning problems with both correct and incorrect plans.
- For each plan, it learns to explain why each step is valid or invalid (e.g., “this action can’t happen because its preconditions aren’t met”).
- This is like a teacher showing full worked examples and common mistakes.
- Chain‑of‑Thought (CoT) Instruction Tuning (show your work + referee)
- Now the model must write out a plan as a chain of state‑action‑state steps (state = what’s true right now; action = what you do next).
- An external “referee” tool (called VAL) checks every step to see if it really follows the rules.
- The model gets feedback in two styles:
- Binary feedback: just “valid” or “invalid.”
- Detailed feedback: a specific explanation of what was wrong (e.g., “precondition X wasn’t true, so you couldn’t do action Y”).
- The process can loop a set number of times so the model can improve its reasoning.
A helpful analogy for the two‑stage training inside phase 2:
- Stage 1 (practice clean technique): focus on writing correct step‑by‑step reasoning (checking preconditions, applying effects correctly).
- Stage 2 (perform the whole routine): focus on producing full, correct plans that reach the goal.
How they tested it:
- They used a standard set of planning puzzles called PlanBench with three domains:
- Blocksworld: stacking blocks in the right order.
- Mystery Blocksworld: same as Blocksworld but with confusing, hidden names.
- Logistics: moving packages using trucks and planes between cities.
- They tried their method on two LLMs (Llama‑3‑8B and GPT‑4) and measured how often the model produced a valid plan.
What they found and why it matters
Here are the key results:
- Big accuracy gains: With PDDL‑Instruct, plan accuracy reached up to 94% on standard tests. That’s an absolute improvement of up to 66 percentage points over the unmodified models.
- Detailed feedback wins: Telling the model exactly what went wrong (not just “wrong”) consistently produced better planners.
- Works across different puzzles: The method improved results in all three domains. It did best on Blocksworld, was good on Logistics, and still made a huge difference on the trickiest one (Mystery Blocksworld). For example, one model jumped from 1% to 64% accuracy there.
- More refinement helps (to a point): Allowing more feedback loops (more chances to learn from the referee) usually improved plans further.
Why this is important:
- LLMs are good at language, but planning with strict rules is different. This work shows you can train an LLM to plan reliably by teaching it to think in logical steps and verify each step.
- It makes AI planning more trustworthy because the model both explains and checks itself with a formal rule‑checker.
What this could mean going forward
- Safer, more reliable AI planners: This approach could help in areas like robotics, delivery systems, or disaster response, where plans must follow rules and be verifiably correct.
- Bridging language and logic: It shows a practical way to combine natural language reasoning with formal, rule‑based checking.
- Still more to do: The current method focuses on finding any valid plan (not always the shortest or cheapest one) and uses a subset of the full planning language. Future work could handle more complex features, aim for the best (optimal) plans, or teach the model to self‑check without needing an external referee.
- Use responsibly: Better planning AIs can help, but they should be used with safeguards and human oversight to avoid misuse in sensitive situations.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list identifies concrete gaps and unresolved questions left by the paper. Each item is phrased to guide actionable follow-up research.
- Coverage of PDDL features is intentionally limited; performance on richer constructs (conditional effects, numeric fluents, derived predicates, action costs, durative/temporal actions, concurrency) remains unknown. Evaluate accuracy and robustness when introducing at least one of these features per domain.
- Scalability to large instances is not quantified (e.g., longer plans, more objects, deeper branching). Benchmark accuracy, inference time, and token/compute cost as functions of plan length and problem size to understand scaling behavior.
- The method targets satisficing planning only; how to instruct and tune for optimality (minimal steps or cost) is unresolved. Design cost-aware CoT and training objectives, and report optimality gap versus classical planners.
- Generalization to novel domains is not convincingly demonstrated beyond three PlanBench domains. Perform leave-one-domain-out training and zero-shot testing on entirely unseen domains (including different predicate and action schemas).
- Heavy reliance on a single external verifier (VAL) is unexamined for robustness. Test sensitivity to verifier choice and output format by repeating experiments with alternative validators (e.g., Planning.Domains, Tarski) and measure performance variations.
- Faithfulness of CoT at the step level is not evaluated. Compute per-step correctness by aligning predicted symbolic states with ground-truth states (from applying actions) and report precision/recall of precondition checks and effect applications.
- Loss functions and training specifics for Stage 1 and Stage 2 (exact and , curriculum, sampling, tokenization) are not fully specified in the main text. Release code and conduct ablations to quantify their contribution.
- The iteration budget is only tested at 10 and 15; no study of optimal or adaptive stopping. Sweep broader ranges and develop dynamic controllers (e.g., confidence- or feedback-driven early stopping) to balance cost and accuracy.
- Compute and cost efficiency are not reported (training time, inference latency, token usage). Provide detailed cost-performance tradeoffs, including throughput, GPU hours, and token counts per solved plan.
- Aggregate accuracies lack error taxonomy. Provide a breakdown of failure modes (e.g., unsatisfied preconditions vs. incorrect effect propagation vs. invariant violation) and evaluate targeted fixes per error type.
- No comparison with classical symbolic planners or hybrid LLM→PDDL pipelines. Benchmark against baselines like Fast Downward and recent LLM-assisted planning systems to contextualize absolute and relative performance, optimality, and runtime.
- Prompt sensitivity and design choices are not ablated. Systematically vary prompt templates (instruction style, rationales, formatting) and measure robustness of plan validity across prompt perturbations.
- Model scale effects are not analyzed (only Llama-3-8B and limited GPT-4 access). Evaluate scaling laws by training/testing across model sizes (e.g., 7B, 13B, 70B) to understand size-performance tradeoffs and saturation points.
- Generation of incorrect plans for training may be biased or limited in diversity. Develop automated mechanisms to synthesize diverse error types (ordering faults, conflicting effects, resource violations) and measure their impact on generalization.
- Performance degradation in Mystery Blocksworld suggests sensitivity to predicate obfuscation. Test controlled symbol permutation, synonym substitution, and learned symbol grounding to assess robustness to vocabulary shifts.
- Potential exposure bias from supervising on gold CoT versus model-generated CoT is not discussed. Compare teacher-forcing with scheduled sampling or reinforcement learning to mitigate distribution shift at test time.
- Self-verification without external tools is left as future work. Prototype internal plan critics and measure their reliability versus VAL, including scenarios where VAL is unavailable or noisy.
- Integration with tool orchestration (e.g., LLM-Modulo) is hypothesized but untested. Quantify reductions in verification loops and overall planning latency when combining the approach with tool routing frameworks.
- The formal CoT tuple includes an uncertainty estimate that is unused. Incorporate and calibrate to gate verification effort (e.g., verify only low-confidence steps) and evaluate efficiency/accuracy tradeoffs.
- Safety and formal guarantees in safety-critical settings are not addressed. Explore property checking, constraint verification, and human-in-the-loop safeguards to ensure safe deployment of generated plans.
- Extensions beyond classical deterministic planning (stochastic, partial observability, contingent planning) remain open. Evaluate the approach on non-classical planning benchmarks and adapt CoT to handle uncertainty.
- Hierarchical and multi-agent planning are not considered. Investigate CoT that reasons over task hierarchies and agent coordination, and measure benefits over flat planning.
- Reproducibility is limited by reliance on supplementary material; public assets are not confirmed. Release datasets, prompts, scripts, and seeds to enable independent replication and benchmarking.
- Interaction with symbolic search (e.g., using LLMs for heuristic guidance) is unexplored. Compare end-to-end CoT planning versus hybrid search-guided methods on the same domains.
- Benchmark coverage is narrow (three domains). Expand to a broader set from PlanBench and other suites (e.g., Rover, Satellite, Depots) to stress different reasoning patterns and constraints.
- Input modality assumes PDDL domain and problem are given; mapping from natural language to PDDL plus planning is untested. Evaluate the full pipeline (NL→PDDL→plan) and measure compounded error and recovery via verification.
- Potential overfitting to specific VAL error messages is unexamined. Randomize, mask, or paraphrase verifier feedback to test whether improvements depend on feedback format rather than underlying semantics.
- Calibration and abstention are not measured; the system always attempts full plans. Assess confidence calibration and implement abstain/seek-help behaviors when uncertainty is high or verification repeatedly fails.
- The comparative effect of feedback granularity is only reported at a coarse level. Ablate which components of detailed feedback (failed preconditions vs. misapplied effects vs. invariant violations) drive gains.
- Effects on general language capabilities post-tuning are unknown. Run standard NLP benchmarks pre/post instruction tuning to detect catastrophic forgetting or unintended behavior drift.
Glossary
- Action applicability: Whether an action can be executed in a given state based on its preconditions. "reason about action applicability, state transitions, and plan validity"
- Add set: The set of fluents that an action makes true when applied. "add(a_i) is the set of fluents that become true after executing "
- Automated planning: The study of computing sequences of actions that transform an initial state into a goal state. "An automated planning problem can be formally characterized as a tuple "
- Blocksworld: A benchmark planning domain involving stacking blocks on each other or the table. "Blocksworld: The classical planning domain with blocks that can be stacked on a table or on other blocks."
- Chain-of-Thought (CoT) prompting: A prompting technique that elicits explicit step-by-step reasoning from LLMs. "Chain of Thought (CoT) prompting"
- Classical planning: Planning with deterministic, fully observable states and instantaneous actions. "including classical planning"
- Conditional effects: Action effects that occur only when certain conditions hold. "conditional effects or durative actions."
- Del set: The set of fluents that an action makes false when applied. "del(a_i) is the set of fluents that become false after executing "
- Derived predicates: Predicates inferred from rules rather than directly asserted by action effects. "derived predicates, action costs, and temporal constraints"
- Durative actions: Actions that take time to execute rather than being instantaneous. "conditional effects or durative actions."
- Fluents: Boolean state variables that describe properties of the world in planning. " is a set of fluents used to describe a discrete and fully-observable state "
- Frame axioms: Assumptions that properties not affected by an action remain unchanged. "frame axioms are violated"
- Grounded actions: Actions whose parameters are fully instantiated with specific objects. "sequence of grounded actions"
- Invariant preservation: Ensuring constraints that must always hold are maintained across state transitions. "invariant preservation"
- Logical coherence: A property of reasoning where each step follows logically from previous steps. "logical coherence"
- Logistics (planning domain): A domain about transporting packages via trucks and airplanes across locations. "Logistics: A transportation planning domain where packages must be moved between locations using trucks and airplanes"
- Mystery Blocksworld: A variant of Blocksworld with obfuscated predicate names to increase difficulty. "Mystery Blocksworld: A more complex variant of Blocksworld with predicates identical but semantically obfuscated names."
- Mutual information: An information-theoretic measure of dependence between variables. "where represents the mutual information between reasoning state and the target output "
- Optimal plan: A plan that achieves the goal with minimal cost or steps. " is considered optimal if it takes the least number of actions (in this work, we consider actions with uniform cost) to reach a goal state"
- PDDL (Planning Domain Definition Language): A standard language for specifying planning domains and problems. "formal representations like the Planning Domain Definition Language (PDDL)."
- Plan accuracy: The percentage of tasks for which the model generates a valid plan achieving the goal. "Our primary evaluation metric is the Plan Accuracy"
- PlanBench: A benchmark suite for evaluating LLM planning capabilities. "PlanBench, a standardized benchmark framework for evaluating LLM planning capabilities."
- Plan validator (VAL): A tool that checks whether a plan is valid with respect to a domain and problem. "implemented using VAL"
- Precondition: A condition that must hold in the current state for an action to be executable. "pre(a_i) is the set of fluents that must hold in the current state for the action to be executable"
- Progressive refinement: A reasoning property where intermediate steps increasingly inform the final answer. "exhibits progressive refinement"
- PSPACE-complete: A complexity class indicating very high computational difficulty, often for planning tasks. "planning tasks, which are PSPACE-complete"
- Satisficing plan: A plan that achieves the goal but is not necessarily optimal. "it is considered satisficing if it reaches the goal successfully but with more actions than needed by an optimal plan."
- State space: The set of all possible states defined by assignments to fluents. "the state space in classical planning emerges from all possible truth assignments to the set of fluents."
- State transition: The change from one state to another due to executing an action. "produces state transitions "
- STRIPS: A foundational action representation for planning with preconditions and add/delete effects. "based on STRIPS"
- Symbolic planning: Planning that manipulates explicit symbols and logical structures rather than sub-symbolic representations. "structured symbolic planning"
- Temporal constraints: Restrictions involving time or durations in planning models. "derived predicates, action costs, and temporal constraints"
- VAL-based verification: Using the VAL tool to formally verify each reasoning step or plan. "A notable advantage of our VAL-based verification approach is its robustness against unfaithful chain-of-thought reasoning"
Practical Applications
Immediate Applications
The following applications can be deployed now in settings that use classical (deterministic, fully observable) planning models and can integrate an external verifier (e.g., VAL). They leverage PDDL-Instruct’s logical chain-of-thought (CoT) instruction tuning, explicit action applicability checks, and verifier-guided refinement to improve plan validity and interpretability.
- Provenance-aware Planning Copilot for Symbolic Domains
- Sector: Software, Robotics, Operations Research
- What it does: An assistant that generates satisficing plans for existing PDDL domains with stepwise state–action–state CoT and validator-backed correctness checks, providing human-readable justifications and pinpointing precondition/effect errors.
- Tools/workflows: “planning_copilot” combining Llama-3/GPT-4 tuned with PDDL-Instruct + VAL; integrates with planners (e.g., Fast Downward) as a hybrid pipeline.
- Assumptions/dependencies: Domain modeled in PDDL without advanced features (no conditional effects, durative actions, or temporal costs); external validator available; non-safety-critical use; satisficing plans are acceptable.
- Plan Explainer and Debugger for Classical Planners
- Sector: Academia, Software, Robotics
- What it does: Takes an existing plan (generated by humans or a planner), explains each step’s preconditions/effects, and uses VAL to highlight exactly where and why a step fails (or confirms correctness).
- Tools/workflows: “plan_explain_verify” CLI/UI that ingests domain, problem, and plan, emits CoT explanations and VAL diagnostics.
- Assumptions/dependencies: Accurate PDDL; VAL integration; limited to classical features; explanation faithfulness enforced by external validation.
- Curriculum and Autograder for AI Planning Courses
- Sector: Education, Academia
- What it does: Interactive labs that teach PDDL and STRIPS via CoT; autograder uses VAL feedback and CoT-based rubrics to give formative feedback on preconditions, effects, and invariants.
- Tools/workflows: “pddl_classroom” notebooks; automated grading pipeline that injects counterexamples and incorrect plans for feedback-driven learning.
- Assumptions/dependencies: Institutional compute or hosted service; curated PlanBench-like tasks; acceptance of external validation in grading.
- Rapid Prototyping of Planning Domains with CoT-Guided Sanity Checks
- Sector: Software Engineering, Research
- What it does: During domain engineering, the assistant generates test problems and minimal plans, flags ill-posed actions (missing preconditions/effects), and proposes fixes with explicit logical justifications.
- Tools/workflows: “domain_prototyper” using PDDL-Instruct + VAL; regression tests for domain evolution.
- Assumptions/dependencies: Engineers can modify PDDL; iterative cycles with validator; limited feature coverage.
- Simulation-based Robotics Task Planning in Labs and Warehouses (Pilot Use)
- Sector: Robotics, Manufacturing, Warehouse Automation
- What it does: CoT-backed planning for pick-and-place, simple assembly, and navigation tasks in simulators or tightly scoped cells; validator ensures action applicability in the symbolic layer.
- Tools/workflows: ROS/MoveIt pipeline where symbolic PDDL layer plans are verified (VAL) before execution; fallback to classical planner if invalid.
- Assumptions/dependencies: Accurate symbolic abstraction of the robot environment; deterministic effects at the planning layer; human-in-the-loop oversight; non-safety-critical.
- Enterprise RPA Process Validator and Assistant
- Sector: Enterprise Software, RPA
- What it does: Given process rules encoded in a PDDL-like rule set, the system proposes and verifies multi-step automation sequences with stepwise CoT and plan validation to prevent rule violations.
- Tools/workflows: “rpa_plan_check” plugin for RPA suites; external rule engine/VAL for applicability checks.
- Assumptions/dependencies: Process models must be formalized; deterministic process transitions; governance retains human approval.
- Benchmarking and Model-Training Pipeline for LLM Planning Research
- Sector: Academia, LLMOps
- What it does: A turnkey pipeline to generate training and evaluation datasets (including negative examples), run CoT instruction tuning, and produce VAL-informed metrics across domains (e.g., PlanBench).
- Tools/workflows: “pddl_instruct_lab” for dataset generation, training, and evaluation; reproducible experiments with binary vs. detailed feedback settings.
- Assumptions/dependencies: GPUs; access to foundation models (Llama-3/GPT-4); curated PDDL domains; reliance on VAL outputs.
- Auditable Plan Documentation in Regulated Workflows
- Sector: Compliance, IT Change Management
- What it does: Produces verifiable, step-by-step justifications for planned changes (e.g., migration steps), increasing transparency and enabling audits against formal preconditions (e.g., approvals, backups) and expected effects.
- Tools/workflows: “change_plan_explainer” that maps CMDB/policy rules to a PDDL-like abstraction; VAL-style checker for applicability.
- Assumptions/dependencies: Simplified, deterministic abstraction of processes; human review; acceptance of satisficing plans.
Long-Term Applications
These applications require broader PDDL feature support (conditional effects, temporal/durative actions, costs), robust real-world grounding, optimality, or self-verification without external validators. They may also need stronger safety cases and regulation-compliant deployment.
- Safety-Critical Clinical Workflow Planning and Verification
- Sector: Healthcare
- What it does: Plans for patient routing, sterilization logistics, treatment pathways with formal preconditions/effects and validator-backed CoT, providing traceability and compliance.
- Tools/products: “clinical_planner” integrated with EHR and hospital operations; formalized SOPs in rich PDDL.
- Dependencies: Rich PDDL features; strong data integration; regulatory validation; human oversight; probabilistic/temporal extensions.
- Disaster Response and Incident Management Planning
- Sector: Public Safety, Emergency Management
- What it does: Generates and verifies multi-step incident response plans with resource constraints, temporal windows, and dynamic updates, providing transparent justifications for each action.
- Tools/products: “responder_plan_assist” with geospatial integration; hybrid LLM + classical/temporal planners.
- Dependencies: Temporal/metric PDDL; partial observability handling; integration with real-time data; rigorous validation and drills.
- Autonomous Fleet and Multi-Robot Task Planning at Scale
- Sector: Robotics, Logistics
- What it does: Verifiable, coordinated task allocation and routing with explicit CoT and validator loops; resolves action conflicts, resources, and synchronization.
- Tools/products: “fleet_cot_planner” with multi-agent extensions and temporal constraints.
- Dependencies: Multi-agent planning, temporal and resource modeling, robust state estimation; safety certification; near-real-time performance.
- Energy Grid Maintenance and Scheduling
- Sector: Energy, Utilities
- What it does: Plans inspection/maintenance with temporal and resource constraints; validator-backed CoT offers transparent justifications and constraint adherence.
- Tools/products: “grid_ops_planner” integrated with asset management and outage planning systems.
- Dependencies: Temporal planning, action costs, stochastic modeling; integration with operational data and reliability standards.
- Finance Operations and Compliance Orchestration
- Sector: Finance, Risk and Compliance
- What it does: Plans KYC/AML investigation steps or change management sequences with evidence-backed precondition checks and audit-ready CoT.
- Tools/products: “fin_ops_planner” tying rules engines, case systems, and formalized policies.
- Dependencies: Formalization of complex business rules; secure data access; regulatory sign-off; handling non-determinism and exceptions.
- Optimal Planning with Cost/Resource Objectives
- Sector: Cross-sector (Logistics, Manufacturing, Cloud Ops)
- What it does: Moves beyond satisficing to optimal plans (least cost/time/resource use) using CoT-guided search with external solvers and validator feedback.
- Tools/products: “cot_opt_planner” that alternates LLM proposals with heuristic search or MILP solvers.
- Dependencies: Objective modeling; scalable search; richer feedback loops; performance guarantees.
- Self-Verification without External Validators
- Sector: AI Systems, Agents
- What it does: LLMs learn reliable internal verification of plan steps (faithful CoT), reducing reliance on tools like VAL while maintaining formal guarantees via learned checkers or neural-symbolic proofs.
- Tools/products: “learned_plan_verifier” paired with proof artifacts (e.g., certificates).
- Dependencies: Advances in faithful reasoning; formal methods integration; robust calibration and adversarial testing.
- Natural Language to Full Planning Models (NL→PDDL with Verified Semantics)
- Sector: Software, Robotics, Process Engineering
- What it does: Converts SOPs or manuals to domain/problem PDDL with verifiable semantics, then plans with CoT and validator loops; reduces domain-engineering overhead.
- Tools/products: “nl2pddl_verified” pipeline with back-prompted CoT and counterexample-guided refinement.
- Dependencies: High-precision NL understanding; interactive elicitation; human-in-the-loop validation; coverage of advanced PDDL features.
- Temporal, Stochastic, and Continuous-Hybrid Planning
- Sector: Autonomous Systems, Manufacturing, Mobility
- What it does: Extends CoT + verification to dynamic, uncertain, and continuous domains (e.g., motion + task planning), supporting robust plans with timing and probabilistic effects.
- Tools/products: “hybrid_cot_planner” combining temporal planners, probabilistic reasoning, and motion planning verifiers.
- Dependencies: Hybrid planning stacks; realistic simulators/digital twins; safety cases; compute for tight MPC-style loops.
- Governance, Auditing, and Assurance for Planning AI
- Sector: Policy, Regulation, Assurance
- What it does: Standardizes verifiable CoT artifacts (stepwise justifications, failure reports) as audit evidence for AI-driven planners in regulated industries.
- Tools/products: “planning_assurance_kit” templates for audit logs, test suites, and certification workflows.
- Dependencies: Standards for explainability and verification artifacts; third-party certification; legal clarity on accountability.
- Human-Centered Plan Co-Creation Interfaces
- Sector: Product Design, Collaboration Tools
- What it does: Mixed-initiative planners where humans edit goals, constraints, and steps while the system explains applicability and validates changes in real time.
- Tools/products: “co_create_planner” UI with live CoT and validator feedback.
- Dependencies: Usability research; incremental validation at interactive speeds; scalable feedback iteration.
Cross-Cutting Assumptions and Constraints
- Representation: Current method assumes classical planning (deterministic, fully observable), uniform action costs, and limited PDDL feature set; extensions are needed for temporal, conditional, or probabilistic domains.
- External verification: Strongest gains rely on VAL or equivalent verifiers and access to detailed error feedback; binary feedback is less effective.
- Satisficing vs. optimality: Out-of-the-box results target satisficing plans; optimality requires additional objectives and solvers.
- Domain engineering: Real-world adoption depends on high-quality PDDL models or robust NL→PDDL pipelines with human oversight.
- Safety and governance: Safety-critical use demands human-in-the-loop, rigorous validation, and compliance frameworks.
- Compute and access: Training/tuning requires GPUs and access to capable foundation models; deployment costs and latency should be considered.
Collections
Sign up for free to add this paper to one or more collections.

