WebWeaver: Structuring Web-Scale Evidence with Dynamic Outlines for Open-Ended Deep Research
Abstract: This paper tackles open-ended deep research (OEDR), a complex challenge where AI agents must synthesize vast web-scale information into insightful reports. Current approaches are plagued by dual-fold limitations: static research pipelines that decouple planning from evidence acquisition and one-shot generation paradigms that easily suffer from long-context failure issues like "loss in the middle" and hallucinations. To address these challenges, we introduce WebWeaver, a novel dual-agent framework that emulates the human research process. The planner operates in a dynamic cycle, iteratively interleaving evidence acquisition with outline optimization to produce a comprehensive, source-grounded outline linking to a memory bank of evidence. The writer then executes a hierarchical retrieval and writing process, composing the report section by section. By performing targeted retrieval of only the necessary evidence from the memory bank for each part, it effectively mitigates long-context issues. Our framework establishes a new state-of-the-art across major OEDR benchmarks, including DeepResearch Bench, DeepConsult, and DeepResearchGym. These results validate our human-centric, iterative methodology, demonstrating that adaptive planning and focused synthesis are crucial for producing high-quality, reliable, and well-structured reports.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper is about building an AI helper that can do deep, open‑ended research on the web and turn what it finds into a clear, trustworthy report. Think of it like a super‑organized student who can search hundreds of websites, take good notes, build a smart outline, and then write a strong paper with proper sources.
The main questions the paper asks
- How can an AI research assistant handle very big, messy questions that don’t have a single right answer, like “What are the latest trends in clean energy and why do they matter?”
- How can it avoid common problems, like getting confused by too much information, forgetting important parts in the middle, or making things up (“hallucinations”)?
- Can an AI plan its research dynamically (changing the plan as it learns more), and write in a careful, step‑by‑step way that stays true to the sources?
How their approach works
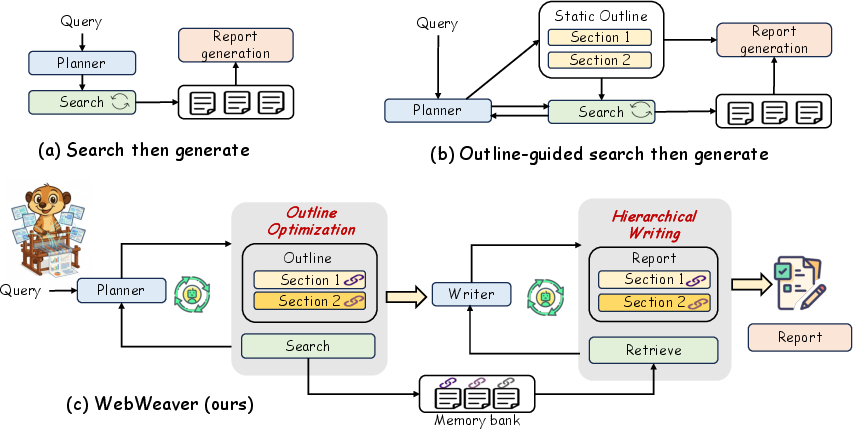
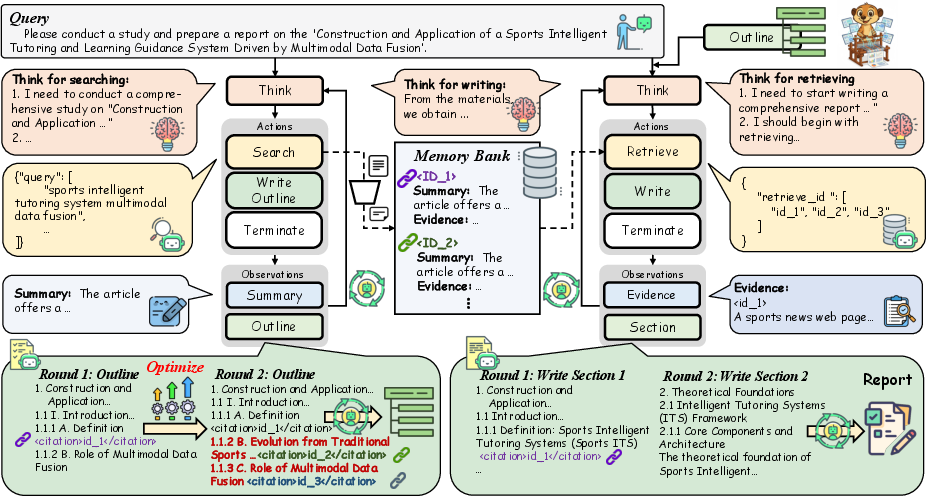
The authors build a system called WebWeaver that acts like a careful human researcher. It has two main “agents” (specialized roles) and a shared memory:
- Planner: Imagine a student who starts with a rough outline, goes searching online, updates the outline based on what they find, and keeps repeating this until the outline is solid. That’s the planner. It:
- Searches the web,
- Filters pages to keep the useful ones,
- Summarizes key parts,
- Extracts important evidence (quotes, numbers, facts) into a “memory bank,”
- Updates the outline, adding citations to the exact pieces of evidence.
- Writer: Think of writing a report one section at a time, using only the notes that matter for that section. The writer:
- Looks at the outline,
- Pulls only the relevant evidence for the current section from the memory bank,
- Thinks through how to explain it,
- Writes that section,
- Then moves on to the next section.
- Memory bank: This is like a well‑organized digital binder. It stores:
- Short summaries of web pages (so the system doesn’t overload itself),
- Detailed snippets of evidence (with source links),
- IDs that connect outline sections to their sources.
A simple way to picture it:
- Old way: “Gather everything, then write one giant essay all at once.” This often leads to confusion, errors, and messy writing.
- WebWeaver way: “Search, update outline, search more, refine outline. Then write section‑by‑section using only the right notes.” This keeps the AI focused and accurate.
A few technical ideas in plain words:
- Open‑ended deep research (OEDR): Big, complex questions with no single answer. Requires reading widely, thinking deeply, and connecting ideas.
- “Lost in the middle”: When there’s too much text at once, the AI can miss important stuff, especially in the middle—like a reader zoning out during a very long chapter.
- Hallucinations: The AI states something as a fact even though it didn’t find it in a source—like guessing.
- ReAct loop (think–act–observe): The AI makes a plan, does an action (like a web search), reads what it got back, and then plans the next step. It repeats this many times, like a “plan–do–check” study loop.
What they found and why it matters
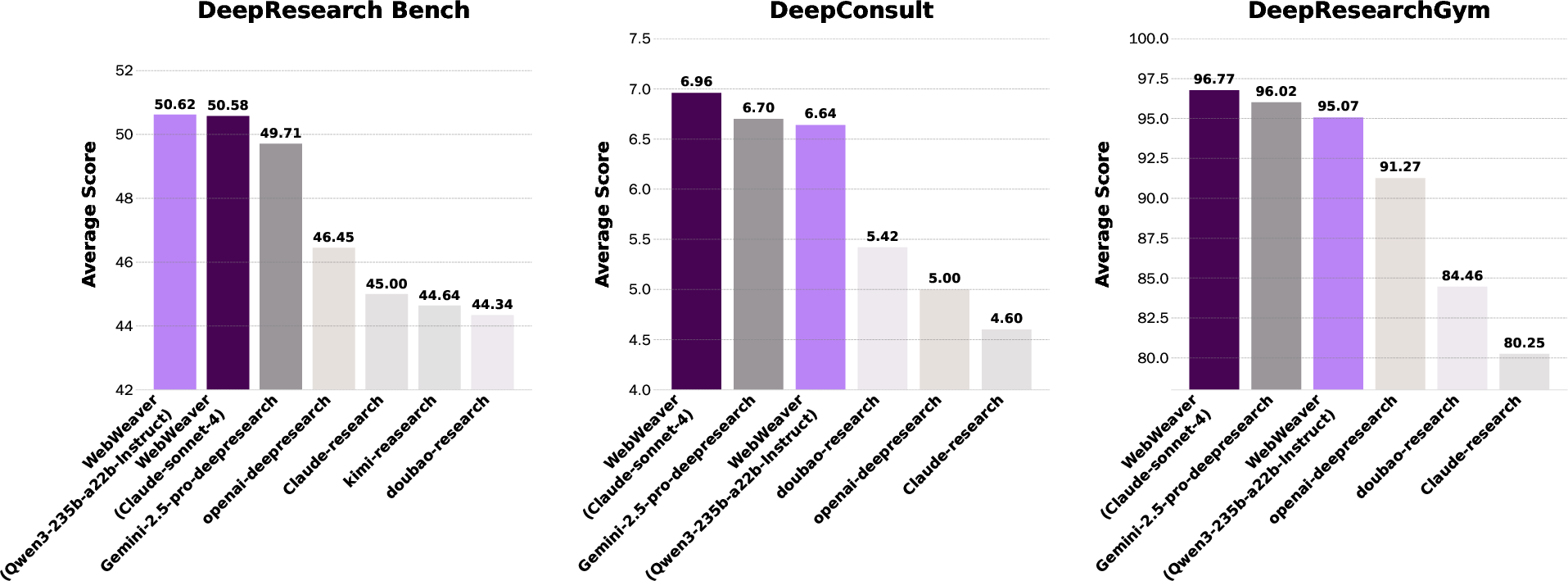
They tested WebWeaver on three tough benchmarks (standardized test sets for this kind of AI):
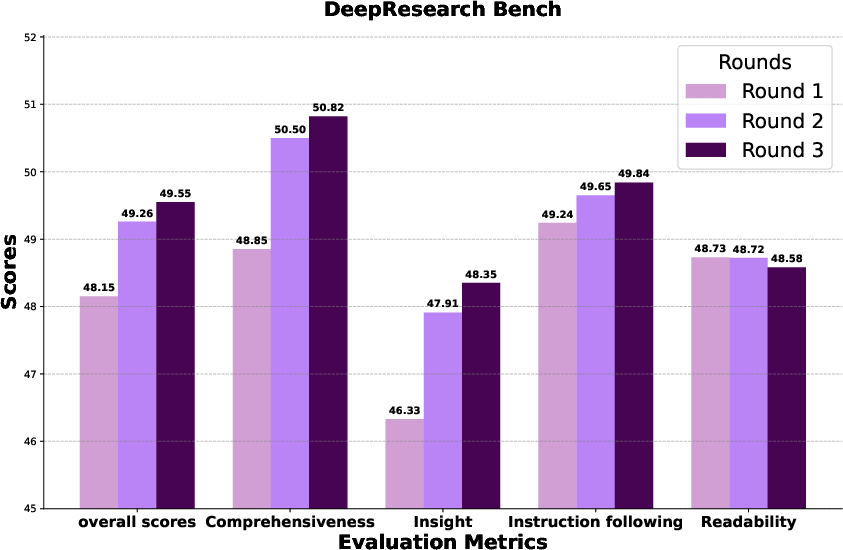
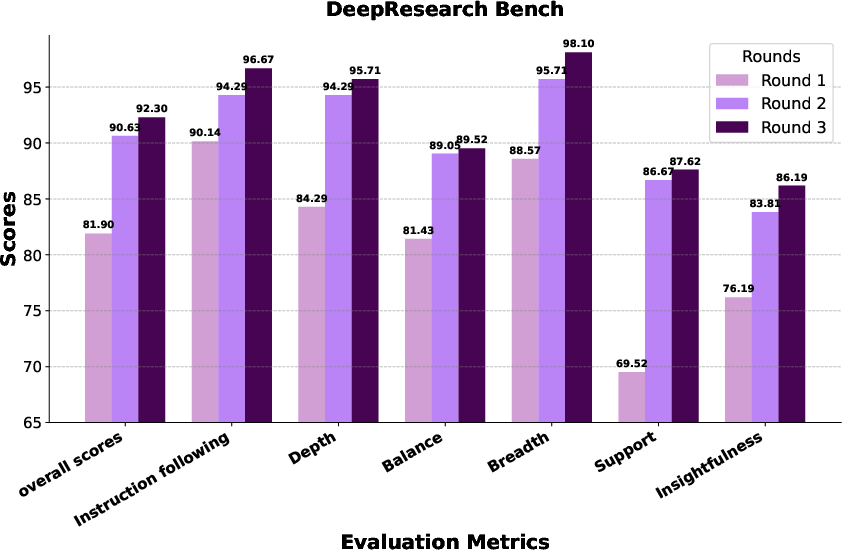
- DeepResearch Bench: 100 PhD‑level tasks across many fields.
- DeepConsult: Business and consulting research tasks.
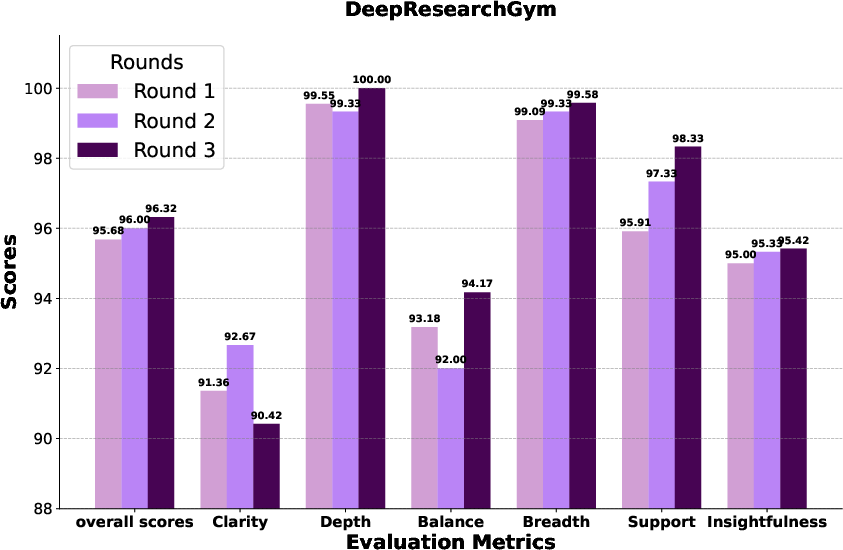
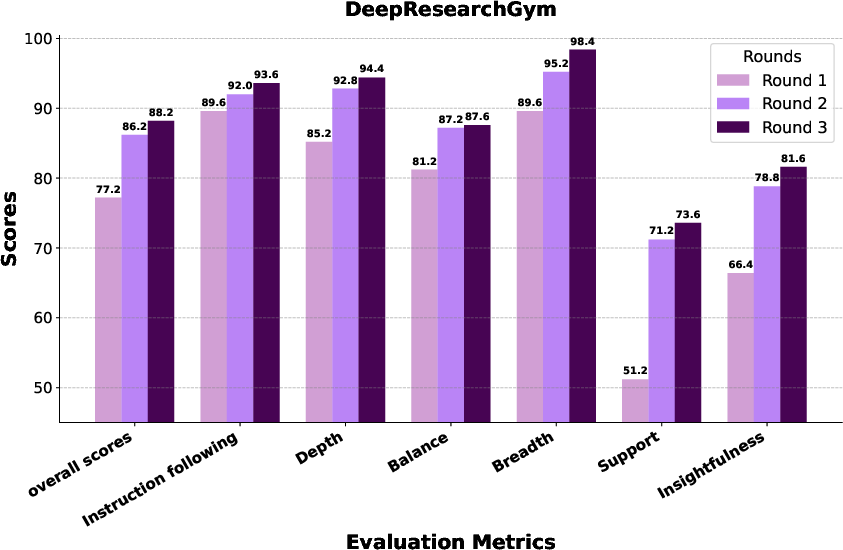
- DeepResearchGym: Real‑world, complex questions from the web.
Main results:
- WebWeaver reached state‑of‑the‑art performance across these benchmarks, beating both open‑source and several commercial systems.
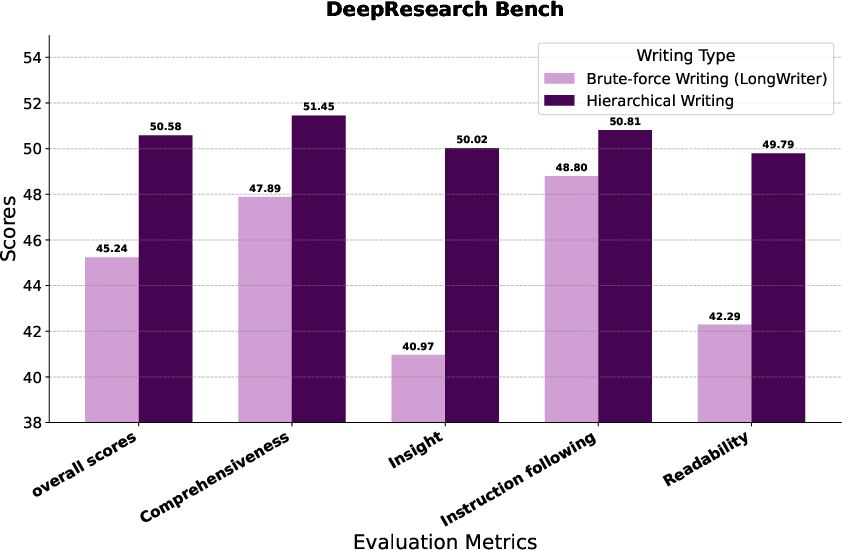
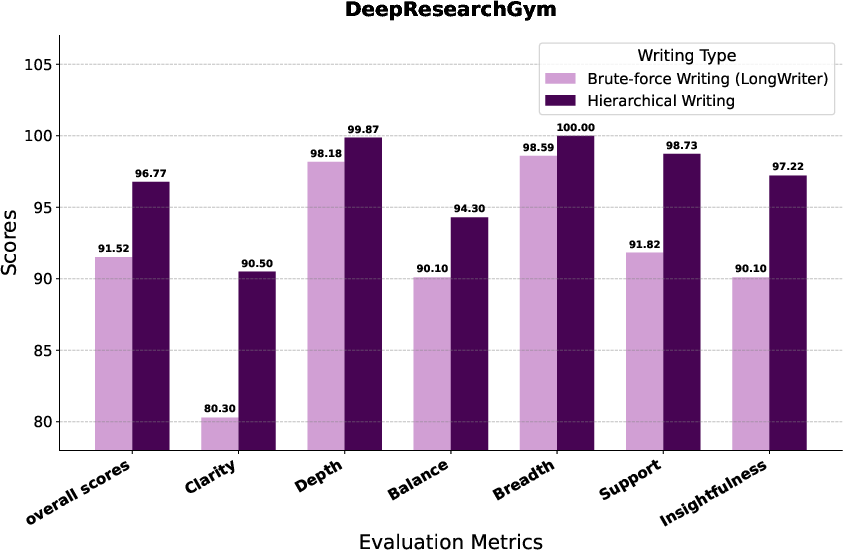
- It wrote reports that were more comprehensive (covered more important topics), deeper (better insights), and better supported (evidence tied tightly to claims).
- Its citation accuracy was very high (around 93% in one setup), meaning it pointed to the right sources reliably.
- The system’s success came from two key ideas:
- Dynamic outlining: Updating the outline as new facts are found made the final plan stronger and more complete.
- Section‑by‑section writing: Retrieving only the needed evidence for each part reduced confusion, improved clarity, and lowered hallucinations.
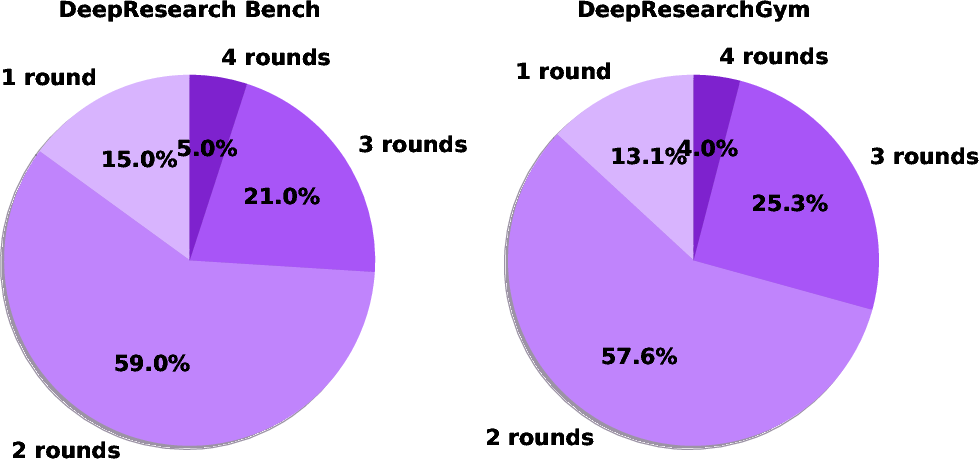
They also ran careful “ablation” tests (changing one thing at a time to see its effect):
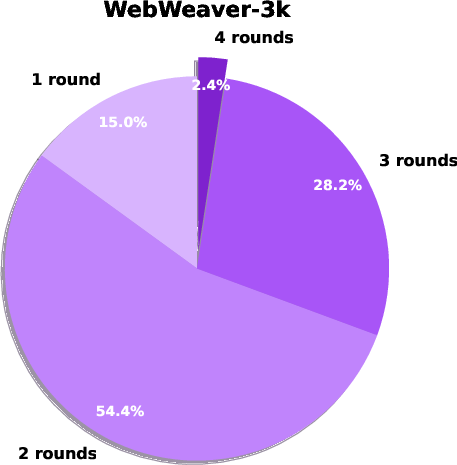
- More rounds of outline improvement led to better final reports.
- Writing hierarchically (one section at a time with targeted evidence) clearly beat the “just throw everything in and write once” approach.
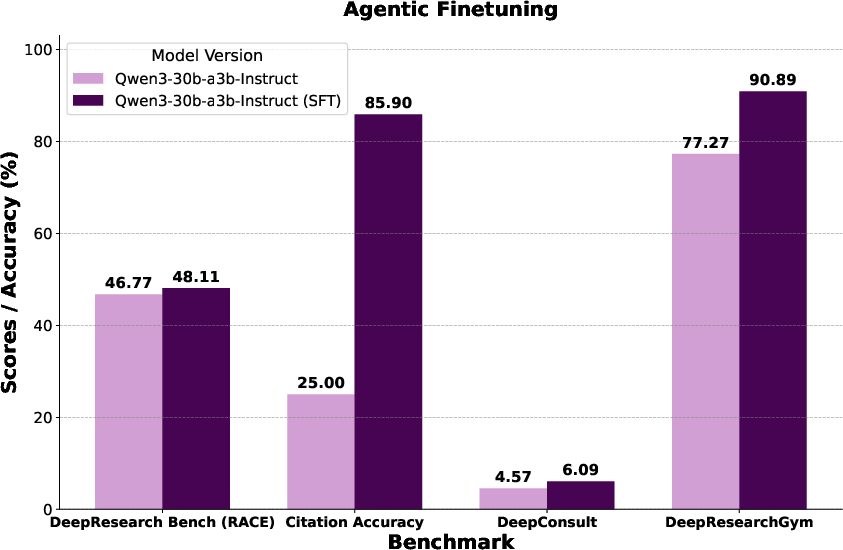
Finally, they built a training set called WebWeaver‑3k from their system’s own good examples, and showed this can teach smaller, cheaper AI models to think, search, and write much better—bringing strong performance to models that cost less.
Why this is important
- Better research helpers: This approach makes AI more trustworthy for big, messy research tasks—useful for students, analysts, journalists, and scientists.
- Fewer mistakes: By grounding every section in specific sources and keeping the AI’s attention focused, the system reduces made‑up facts and sloppy writing.
- Scales to huge information: The memory bank and section‑wise writing help the AI handle hundreds of sources without getting lost.
- More accessible: The new training data shows smaller models can learn these skills, which could make strong research AIs cheaper and easier to use.
- Human‑like process: The system succeeds by imitating how good human researchers really work—plan, search, revise the plan, then write carefully with proper citations.
Bottom line
WebWeaver shows that AI can do serious, open‑ended research better when it:
- Plans dynamically (keeps updating its outline as it learns),
- Stores evidence carefully (with summaries and citations),
- Writes piece‑by‑piece using only what’s relevant.
This leads to clearer, more accurate, and more insightful reports—and it could make reliable AI research assistants much more practical in school, business, and beyond.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and concrete directions that future researchers could pursue to strengthen, generalize, and scrutinize the proposed WebWeaver framework.
- Human evaluation and external validity: Results rely heavily on LLM-as-judge metrics (benchmark defaults). Conduct blinded expert evaluations, report inter-annotator agreement, and compare against professional analyst baselines to validate perceived insight, rigor, and usefulness.
- Cost, latency, and resource efficiency: Report wall-clock time, API/token costs, compute footprint, and energy per task; study quality–cost trade-offs, budget-aware planning policies, and latency under API rate limits.
- Reproducibility and stability: Quantify variance across random seeds, repeated runs, and different LLM backbones; provide deterministic settings and report confidence intervals for main results.
- Judge/model coupling bias: Assess whether performance gains persist when judges are changed (including weaker/stronger judges, non-overlapping model families) to rule out alignment bias between agent and judge.
- Termination criteria for planning: Define and evaluate principled stopping rules (e.g., topic coverage estimation, novelty saturation, uncertainty thresholds) to prevent premature or excessive searching and outline inflation.
- Writer autonomy for missing evidence: Explore allowing the writer to trigger new searches or request outline revision when encountering evidence gaps or contradictions during section synthesis.
- Memory bank design choices: Ablate evidence granularity (sentence/paragraph/page), indexing schemes (dense vs lexical vs hybrid), and retrieval ranking; evaluate deduplication, redundancy control, and contradiction clustering.
- Verification of citations and quotes: Implement exact-match quote verification, URL resolution checks, and anti-fabrication detectors; benchmark with faithfulness metrics beyond benchmark “citation accuracy.”
- Global coherence and cross-section consistency: Develop and report metrics for cross-section contradiction detection, entity/event consistency, and topical drift; add cross-referencing and global pass reconciliation.
- Robustness to misinformation and adversarial sources: Stress-test with noisy, conflicting, or adversarially perturbed web content; add source credibility scoring, provenance tracking, and stance diversity controls.
- Search engine dependence and personalization: Measure sensitivity to engine choice, region/personalization, and temporal drift; compare metasearch vs single-engine strategies.
- Query generation and reformulation: Analyze query drift, coverage, and specificity; compare against retrieval baselines (BM25, DPR, hybrid), and study reinforcement learning or bandit strategies for query refinement.
- Evidence extraction fidelity: Quantify information loss and distortions introduced by LLM-generated summaries; evaluate summary faithfulness against ground-truth passages and measure downstream impact on writing quality.
- Handling contradictory evidence: Introduce argumentation or evidence reconciliation modules with confidence scoring; evaluate quality of dispute resolution and balanced presentation.
- Scaling limits: Characterize performance as the number of sources and outline size grow (e.g., 1k+ pages, 1M+ tokens); study sharded memory, streaming retrieval, and section batching to sustain quality.
- Hallucination measurement: Use explicit faithfulness benchmarks (e.g., FactScore, TRUE/AttributionBench) and entailment checks to quantify hallucinations beyond citation metrics.
- Cross-lingual and multilingual research: Evaluate non-English queries/sources, translation quality, cross-lingual retrieval, and mixed-language synthesis; measure coverage and bias across languages.
- Multimodal and structured sources: Extend to tables, figures, datasets, code repositories, and videos (OCR/table parsing, dataset analysis tools); evaluate claims that require data analysis or visualization.
- Access to scholarly and paywalled content: Study legal and technical integration with academic indexes (e.g., Unpaywall, Crossref), handling of paywalls, and the effect of missing high-quality sources on conclusions.
- Ethical, legal, and compliance considerations: Address robots.txt, copyright, data retention, and privacy; propose red-teaming for harmful queries and add guardrails for risky content generation.
- Dataset WebWeaver-3k transparency: Release detailed documentation (domains, licenses, collection pipeline, quality filters), leakage checks against benchmarks, annotation noise analysis, and robustness of SFT gains across models.
- Component-wise causal impact: Provide fuller ablations (remove internal “think” step, pruning, URL selection LLM, evidence extraction, citation mapping) and quantify each component’s marginal contribution.
- Parameter sensitivity: Study effects of temperature, top-p, step limits, search depth, and outline optimization rounds; provide recommended settings and adaptive policies.
- Failure modes and recovery: Characterize and mitigate oscillatory planning, dead-ends, stale or broken links, and empty-result searches; add fallback strategies and health monitoring.
- Outline–performance coupling: Create predictive outline-quality metrics (coverage, support density, citation dispersion) to decide when to stop optimizing; learn policies that balance outline depth vs diminishing returns.
- Contradiction- and uncertainty-aware reporting: Integrate uncertainty quantification and confidence tagging; explicitly surface low-evidence areas, competing hypotheses, and limitations in the final report.
- Cross-domain generalization: Test on domains underrepresented in current benchmarks (e.g., medical guidelines, legal analysis, public policy, hard sciences with math-heavy PDFs) and report domain transfer results.
- Human-in-the-loop steering: Explore interfaces for user goals, constraints, and preferences; quantify gains from expert steering vs fully autonomous runs.
- Open-source completeness: Provide full prompts, tool configurations, search logs, memory snapshots, and seeds to enable exact reproduction; document environment dependencies and API versions.
- Long-range rhetorical planning: Study algorithms for global narrative structure (section ordering, foreshadowing, cross-references) and their effect on readability and argument strength.
- Knowledge retention across tasks: Investigate persistent memories/knowledge graphs to reuse verified evidence across related queries, with freshness checks and decay policies.
Collections
Sign up for free to add this paper to one or more collections.

