- The paper introduces a dual-branch diffusion model that jointly synthesizes multi-view RGB videos and kinematic part segmentations from monocular inputs.
- It employs spatial color encoding and a contrastive loss to ensure temporally and spatially consistent part decompositions across views and frames.
- Experimental results demonstrate superior mIoU and rigging precision over state-of-the-art baselines, reducing manual rigging effort.
Stable Part Diffusion 4D: Multi-View RGB and Kinematic Parts Video Generation
Introduction and Motivation
Stable Part Diffusion 4D (SP4D) addresses a critical gap in 4D content generation: the lack of kinematic part decomposition in generative models for articulated objects. While prior 4D and 3D generative models have achieved impressive results in synthesizing geometry and appearance, they typically fail to produce part-aware, temporally consistent segmentations that align with object articulation. This limitation hinders downstream applications such as animation, auto-rigging, and motion retargeting, where understanding the object's internal structure and articulation is essential.
SP4D introduces a dual-branch diffusion architecture that jointly generates multi-view RGB videos and kinematic part segmentation maps from monocular video or single-image input. The framework is designed to produce part decompositions that are consistent across time and viewpoints, and that reflect the underlying kinematic structure rather than merely semantic or appearance-based segmentation.

Figure 1: SP4D generates novel-view RGB videos and consistent part segmentation videos from monocular input, supporting both video and single-image input, and enabling 3D riggable mesh reconstruction.
Methodology
Architecture Overview
SP4D extends the SV4D 2.0 multi-view video diffusion model with a dual-branch UNet architecture. One branch is dedicated to RGB synthesis, while the other predicts kinematic part segmentation. Both branches share positional embeddings and a VAE encoder/decoder, but maintain separate feature streams to avoid cross-task interference. The branches are coupled via the Bidirectional Diffusion Fusion (BiDiFuse) module, which enables bidirectional feature exchange at every block, promoting cross-modal consistency.
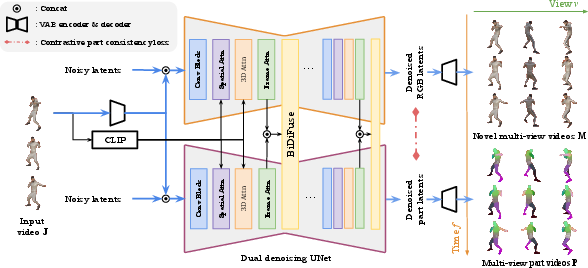
Figure 3: SP4D architecture: dual-branch UNet with BiDiFuse modules for cross-branch feature exchange, spatial color encoding for part masks, and a contrastive loss for part alignment.
Spatial Color Encoding
To enable efficient joint modeling and decoder sharing, part segmentation maps are encoded as continuous RGB-like images using a deterministic spatial color encoding. Each part is assigned a color based on its normalized 3D center, ensuring consistent color assignment across frames and views. This encoding allows the segmentation branch to leverage the same VAE as the RGB branch, facilitating unified training and efficient inference.
Part Mask Recovery
Discrete part masks are recovered from the generated color-encoded images using a two-step process: (1) SAM (Segment Anything Model) is applied in auto-generation mode to produce candidate segments, and (2) clustering (HDBSCAN) is used to assign part IDs based on color modes within each segment. This approach robustly eliminates pixel-level noise and produces clean, discrete part masks.
Contrastive Part Consistency Loss
A contrastive loss is introduced to enforce spatial and temporal consistency of part assignments. Part-specific features are aggregated and projected into a shared embedding space; features corresponding to the same part across views and frames are treated as positives, while others are negatives. An InfoNCE-style loss encourages consistent encoding of the same part, mitigating temporal fragmentation and view inconsistency.
Training Strategy and Dataset
SP4D is trained in two stages. The RGB branch is first pretrained on ObjaverseDy with RGB supervision only, leveraging strong pretrained priors. The full dual-branch model is then fine-tuned on the newly curated KinematicParts20K dataset, which contains over 20,000 rigged objects with multi-view RGB and kinematic part video annotations. Bone merging is applied to control granularity, and per-bone skinning weight maps are rendered to provide high-quality supervision.
2D-to-Kinematic Mesh Pipeline
SP4D enables a lightweight pipeline for generating riggable 3D assets from a single image:
- SP4D generates multi-view RGB and part segmentation images.
- Hunyuan 3D 2.0 reconstructs the 3D mesh from the multi-view RGB images.
- Part segmentation is mapped onto the mesh using HDBSCAN clustering.
- Harmonic skinning weights are computed by solving Laplace equations on the mesh, propagating part influence and yielding soft per-vertex assignments.
This pipeline produces animation-ready assets without explicit skeleton annotations.
Experimental Results
SP4D is evaluated against state-of-the-art 2D and 3D part segmentation baselines, including SAM2, DeepViT, Segment Any Mesh, and SAMPart3D. Quantitative results on the KinematicParts20K validation set demonstrate that SP4D achieves substantially higher mIoU, ARI, F1, and mAcc scores in both multi-view and multi-frame settings. Notably, removing the contrastive loss or BiDiFuse module leads to significant performance degradation, confirming their necessity.

Figure 2: Qualitative results on synthetic and real-world videos: SP4D produces temporally and spatially consistent kinematic part decompositions across diverse object categories and motions.

Figure 4: Visual comparison of part segmentation: SP4D (middle row) yields more structured, articulation-aligned, and view-consistent decompositions than SAM2 (bottom row).
User studies further corroborate the superiority of SP4D in terms of part clarity, view consistency, and rigging suitability, with average ratings exceeding 4.2/5, compared to <2 for baselines.
3D Segmentation and Rigging
SP4D outperforms SOTA 3D segmentation methods in both segmentation accuracy and rigging precision. On the KinematicParts20K test set, SP4D achieves mIoU of 0.64 and rigging precision of 72.7, compared to 0.15/0.13 mIoU and 63.7/64.3 precision for Segment Any Mesh and UniRig, respectively. In user studies on animation plausibility for generated objects, SP4D is rated significantly higher than auto-rigging baselines.
Ablation and Architectural Analysis
Ablation studies confirm that both the BiDiFuse module and the contrastive part consistency loss are essential for robust, temporally and spatially consistent kinematic part segmentation. The dual-branch architecture with cross-modal fusion outperforms single-branch alternatives, which suffer from cross-task interference and degraded consistency.
Implications and Future Directions
SP4D demonstrates that kinematic part decomposition can be learned from 2D multi-view supervision using diffusion models, without reliance on category-specific priors or explicit skeleton templates. This enables robust generalization to novel object categories, rare articulated poses, and both synthetic and real-world data. The approach substantially reduces manual rigging effort, democratizing access to animation-ready 3D assets for creators in diverse domains.
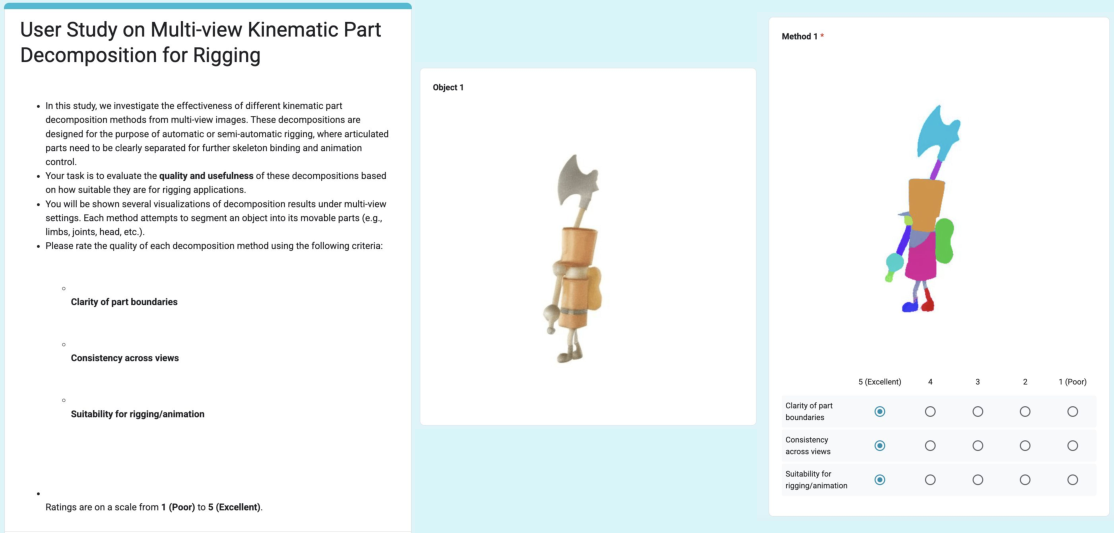
Figure 5: User study interface for evaluating multi-view kinematic part segmentation, focusing on part consistency, structural correctness, and motion coherence.
However, SP4D inherits certain limitations from its backbone, including restricted camera parameterization (azimuth/elevation only) and single-object scene assumptions. Extending the framework to support full 6-DoF camera motion, multi-object scenarios, and more complex articulation remains an open research direction. Integrating lightweight structural priors or explicit skeleton extraction could further enhance downstream animation capabilities.
Conclusion
SP4D introduces a principled, diffusion-based framework for joint RGB and kinematic part video generation from monocular input, closing a key gap in the 3D content creation pipeline. By leveraging a dual-branch architecture, spatial color encoding, cross-modal fusion, and contrastive consistency loss, SP4D achieves state-of-the-art performance in kinematic part segmentation and rigging, with strong generalization across domains. The method paves the way for scalable, category-agnostic, and animation-ready 3D asset generation, with broad implications for graphics, vision, and robotics.