- The paper presents a systematic evaluation comparing LLM-generated code with human-developed green solutions across multiple hardware platforms.
- It analyzes four prompting strategies and measures energy consumption using rigorous statistical methods across six state-of-the-art LLMs.
- The study highlights that hardware context and expert coding remain critical for achieving optimal energy efficiency in Python implementations.
Generating Energy-Efficient Code via Large-LLMs: An Empirical Assessment
Introduction
This paper presents a comprehensive empirical study on the energy efficiency of Python code generated by LLMs, comparing their output to human-written code and code developed by a Green software expert. The study is motivated by the increasing adoption of LLMs in software engineering pipelines and the growing importance of sustainability and energy efficiency in software development. The authors systematically evaluate six state-of-the-art LLMs using four prompting techniques across three hardware platforms (server, PC, Raspberry Pi), measuring the energy consumption of 363 solutions to nine coding problems from the EvoEval benchmark. The study provides statistically robust insights into the current capabilities and limitations of LLMs in generating energy-efficient code.
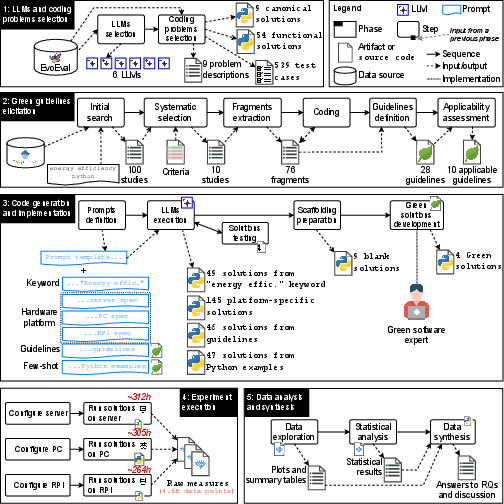
Figure 1: Overview of study phases, including LLM selection, guideline elicitation, code generation, and energy measurement across hardware platforms.
Experimental Design and Methodology
The study employs a rigorous experimental protocol, including:
- LLM Selection: Six models (GPT4, ChatGPT, DeepSeek Coder 33B, Speechless Codellama 34B, Code Millenials 34B, WizardCoder 33B) are chosen for diversity in architecture and accessibility.
- Benchmark Problems: Nine computationally challenging Python problems from EvoEval are selected, ensuring all LLMs can generate functionally correct solutions.
- Prompt Engineering: Four prompting strategies are evaluated: base (functional), keyword ("energy efficient"), hardware-specific, guideline-based (using 10 systematically derived green coding guidelines), and few-shot learning.
- Human Baselines: Canonical solutions from EvoEval and expert-developed green solutions are included for comparison.
- Energy Measurement: Solutions are executed on three platforms (server, PC, Raspberry Pi) with high-frequency energy sampling (up to 5000Hz), totaling ~881 hours and 4.6 billion data points.
- Statistical Analysis: Non-parametric ART ANOVA and Cliff's Delta are used to assess significance and effect sizes, with post-hoc corrections.
Key Findings
LLM Energy Efficiency Varies by Model and Hardware
Energy consumption of LLM-generated code exhibits significant variation across models and hardware platforms. On the server, Speechless Codellama produces the most energy-efficient code, while Code Millenials and WizardCoder excel on PC and Raspberry Pi, respectively. GPT4 consistently generates the least energy-efficient code across all platforms. The effect sizes for these differences are large, indicating practical significance.
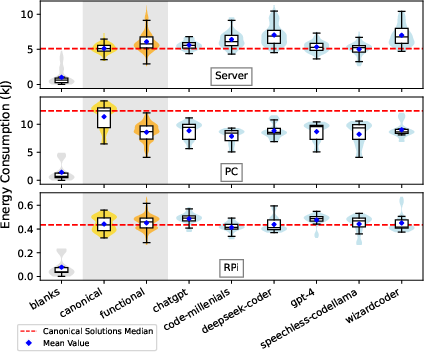
Figure 2: Energy distributions for canonical (human) and functional (LLM-generated) solutions across hardware platforms.
Human vs. LLM-Generated Code
Canonical human solutions are 16% more energy-efficient than LLM-generated code on the server and 3% more efficient on the Raspberry Pi, but LLMs outperform humans by 25% on the PC. The difference on the Raspberry Pi is statistically insignificant. The type of LLM does not heavily influence this comparison, suggesting that hardware context is a dominant factor.
Prompt Engineering Has Limited Impact
Prompting strategies, including energy-specific keywords, hardware details, green guidelines, and few-shot examples, do not consistently yield more energy-efficient code. The most energy-efficient prompt varies by hardware, and the effect sizes for prompt-induced differences are generally small or negligible. Notably, guideline and few-shot prompts increase the variance in energy consumption, indicating unpredictable LLM behavior when given explicit energy-saving instructions.
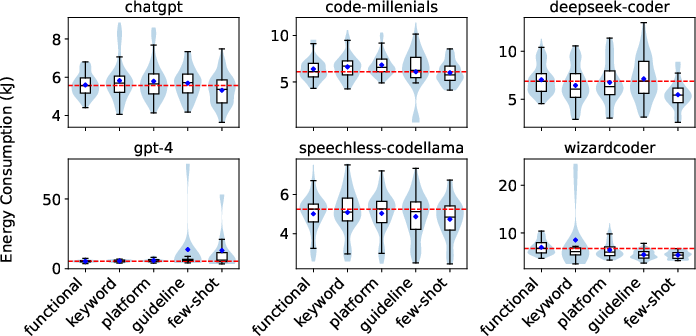
Figure 3: Energy consumption on the server for solutions generated via different prompting techniques, showing high variance for guideline and few-shot prompts.
Green Expert Code Sets the Lower Bound
Code developed by a Green software expert is consistently more energy-efficient than all LLM-generated solutions, with a margin of 17–30% across platforms. In rare cases, Speechless Codellama and WizardCoder, when prompted with guidelines or few-shot examples, produce solutions that rival or slightly outperform expert code, but no LLM-prompt combination consistently matches expert performance across all hardware.
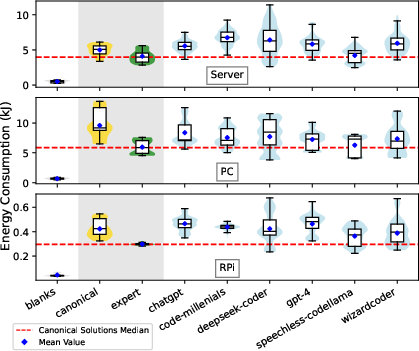
Figure 4: Comparison of energy usage between Green expert solutions and LLM-generated solutions across platforms.
Implications
For Developers
- Critical Evaluation Required: LLM-generated code's energy efficiency is highly context-dependent. Developers should not assume that code generated by LLMs is optimal for their target hardware.
- Manual Refinement Necessary: Reviewing and refining LLM-generated code using green coding guidelines remains essential for energy-critical applications.
- Prompt Engineering Limitations: Current prompt engineering techniques do not reliably improve energy efficiency; hardware-aware or guideline-based prompts may increase code variance rather than guarantee improvements.
For LLM Vendors
- Non-Functional Metrics Needed: LLMs should be evaluated and fine-tuned for non-functional properties such as energy efficiency, not just correctness.
- Green Code Generation as a Competitive Advantage: Vendors should invest in model architectures, training data, and fine-tuning strategies that explicitly target energy efficiency, potentially leveraging domain-specific models or retrieval-augmented generation.
For Researchers
- Hardware Context is Crucial: Energy efficiency results are not generalizable across hardware; future studies must include diverse platforms and report hardware-specific findings.
- Green Code Benchmarks Needed: The community should develop and maintain benchmarks of energy-efficient code to facilitate reproducible research and model evaluation.
- Expertise Remains Valuable: Human expertise in green software engineering is still necessary; LLMs have not yet matched expert-level energy optimization.
Limitations and Threats to Validity
- Language Scope: The study focuses on Python; results may not generalize to other languages.
- Hardware Coverage: Only three platforms are tested; broader hardware diversity may yield different results.
- Expert Baseline: The Green expert's solutions represent a practical lower bound, not an absolute optimum.
- LLM Evolution: Rapid advances in LLMs may affect the long-term relevance of these findings.
Conclusion
The empirical evidence demonstrates that, as of now, LLMs do not consistently generate energy-efficient Python code compared to human experts. Prompt engineering offers limited and unpredictable improvements. Hardware context is a major determinant of energy efficiency, and expert knowledge remains indispensable for green software development. The study highlights the need for further research into LLM fine-tuning for non-functional requirements, the development of green code benchmarks, and the integration of energy efficiency as a first-class metric in both academic and industrial LLM evaluation.

