- The paper introduces SciGPT, a domain-specific LLM that employs low-cost domain distillation and SMoE to enhance scientific literature understanding.
- It utilizes a two-stage training process with SFT and DPO, enabling superior performance in NER, RE, and cross-domain knowledge fusion.
- Results demonstrate that SciGPT outperforms GPT-4 on ScienceBench, achieving higher BLEU scores and improved factual accuracy in scientific tasks.
SciGPT: A Domain-Specific LLM for Scientific Literature
Introduction
The rapid expansion of scientific literature poses a significant challenge for efficient knowledge synthesis. LLMs such as GPT-4 have demonstrated notable potential in text processing yet often lack the capacity to effectively capture domain-specific language, especially in scientific contexts where technical jargon and rigorous methodologies are prevalent. This presents a critical obstacle to interdisciplinary research, where nuanced integration of diverse knowledge bases is essential. Addressing these challenges necessitates both architectural and data-driven innovations. SciGPT, a specialized domain-adapted LLM, emerges as a solution for understanding and discovering knowledge within scientific literature.
Methodology
SciGPT is built upon the Qwen3 architecture and brings several innovations tailored to the scientific domain: a low-cost domain distillation process, Sparse Mixture-of-Experts (SMoE) attention mechanism, and knowledge-aware adaptation.
The data collection strategy aggregated a comprehensive multi-source corpus from public scientific corpora, domain repositories, and synthetically generated data. The focus includes Named Entity Recognition (NER), Relation Extraction (RE), and cross-domain knowledge fusion. Data preparation involved significant cleaning processes—including hybrid filtering and MinHash deduplication—to ensure high-quality input.
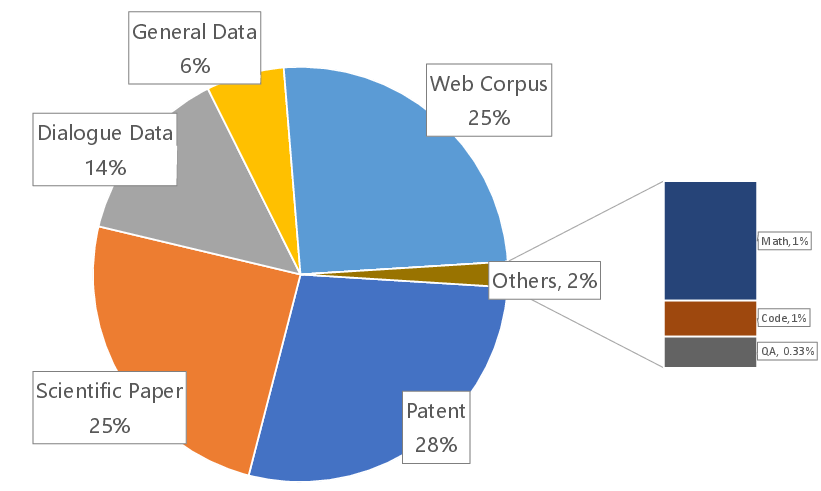
Figure 1: The distribution of different categories of pretraining data for SciGPT.
Key tasks were curated into ScienceBench, a novel benchmark designed to evaluate the scientific capabilities of LLMs across several dimensions, including factual accuracy, methodological rigor, and cross-reference coherence.
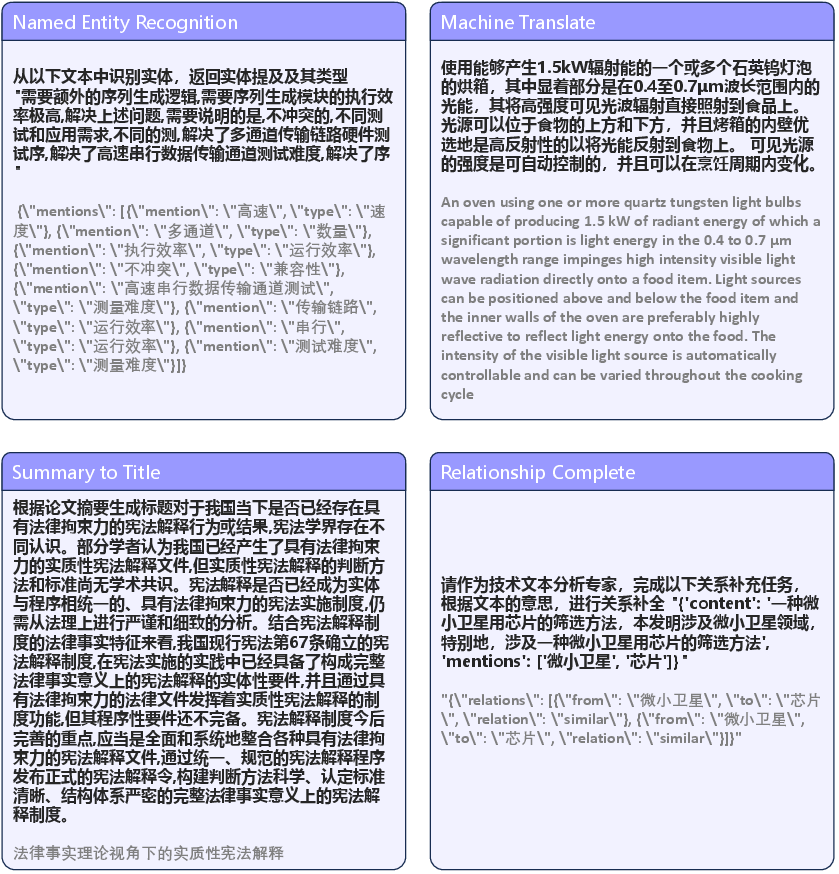
Figure 2: Examples of questions.
Training
The training process of SciGPT features a two-stage Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO). SciGPT leverages Qwen3-8B as its base, due to its balance between computational efficiency and cross-domain performance.
The first stage of SFT involves structured understanding tasks, while the second phase transitions to generation-intensive tasks like summarization. Training utilized a mix of A800 and L40s GPUs with QLoRA, optimizing memory and computational efficiency.
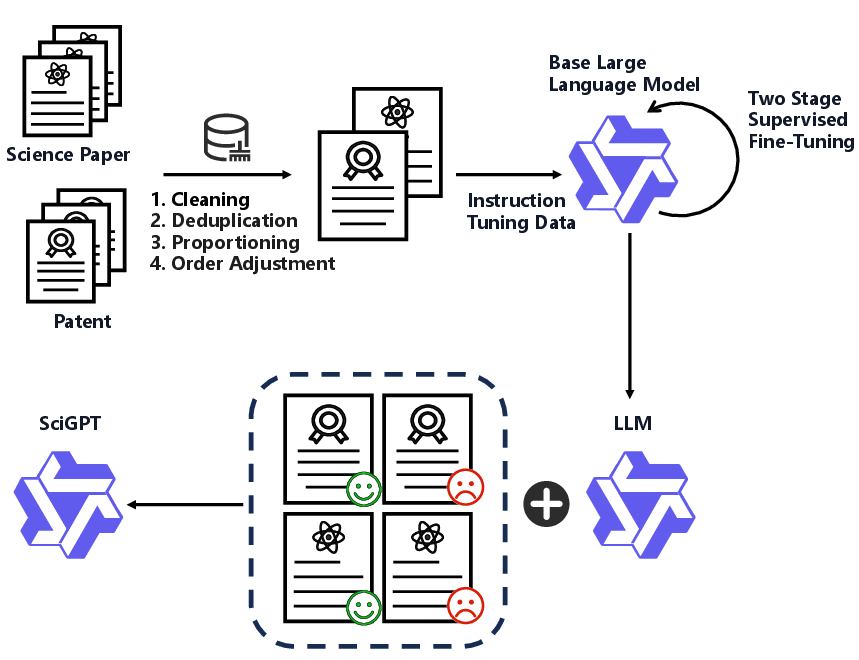
Figure 3: Schematic of LLM SciGPT.
DPO enhances SciGPT through preference learning, utilizing a hybrid dataset of human and AI-generated pairs to refine preference accuracy and factual consistency. Optimization strategies included AdamW with precision-targeted hyperparameters to maximize effectiveness in real-world scientific tasks.
Results
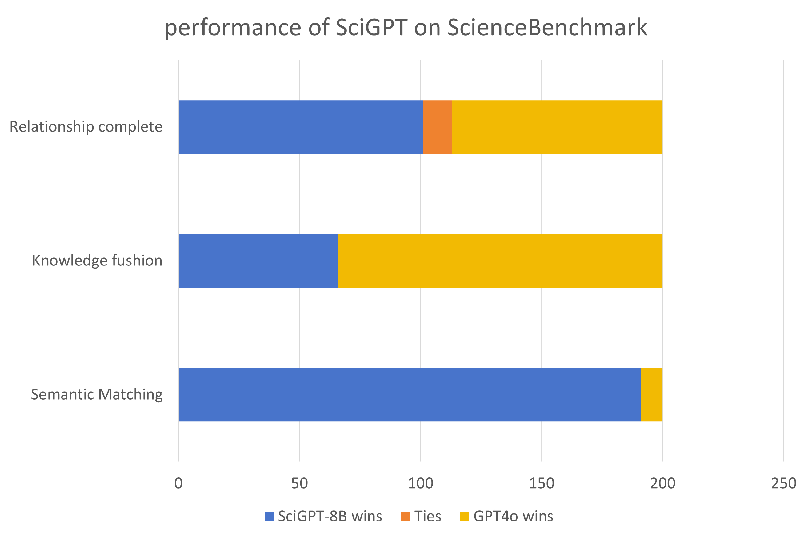
SciGPT's performance was evaluated on the bespoke ScienceBench benchmark, demonstrating significant advancement over general LLMs like GPT-4. Task-specific assessments reveal that SciGPT excels in tasks requiring fine-grained understanding of scientific contexts, including:
(Table 1)
Performance comparison of SciGPT with GPT-4 on ScienceBench tasks, indicating significant improvements in domain-specific benchmarks.
Robustness and Generalization
SciGPT exhibits robust generalization capabilities, adapting well to unseen tasks such as those emerging from new relation extraction datasets. However, challenges remain in niche fields with limited training data, where generalization is reduced.
Conclusions and Future Works
SciGPT represents a significant step forward in enhancing the utility of LLMs for scientific literature analysis. The model's innovative architecture and methodologies not only address current bottlenecks in knowledge synthesis but also set a benchmark for future development of scientific LLMs.
Future endeavors will focus on enhancing interdisciplinary reasoning, improving the integration of multi-modal data, and advancing interpretability to ensure adherence to scientific research standards. With ongoing refinement, SciGPT has the potential to become an indispensable tool in scientific research, facilitating more efficient knowledge discovery and innovation across domains.