- The paper introduces ExIt, a method that trains on single-step transitions to bootstrap iterative self-improvement, reducing computational cost versus traditional multi-step approaches.
- It leverages group return variance and exploration techniques, such as self-divergence and embedding-based diversity bonuses, to prioritize and refine task instances.
- Experimental results demonstrate up to 2.0% improvement in math accuracy and robust performance gains, highlighting enhanced task diversity and extended self-improvement iterations.
Bootstrapping Task Spaces for Self-Improvement: ExIt Strategies for RL Fine-Tuning of LLMs
Introduction and Motivation
The paper introduces Exploratory Iteration (ExIt), a family of reinforcement learning (RL) methods designed to enhance the self-improvement capabilities of LLMs at inference time. The central insight is that many complex tasks—such as mathematical reasoning, multi-turn tool use, and code generation—benefit from iterative refinement, where each solution attempt can be improved upon in subsequent steps. Traditional RL approaches to K-step self-improvement require training on multi-step trajectories, which is computationally expensive and inflexible. ExIt circumvents this by training exclusively on single-step self-improvement transitions, while dynamically generating new task instances by sampling from the most informative partial solution histories encountered during training.
ExIt: Methodology and Algorithmic Design
ExIt leverages the recurrent structure of self-improvement tasks by treating each partial solution (i.e., a solution at any intermediate step) as a potential new task instance. The method maintains a buffer of such partial histories, prioritized by a learnability score—specifically, the variance in group returns as measured by Group-Relative Policy Optimization (GRPO). This prioritization ensures that training focuses on those task instances where the model's performance is most variable, and thus most amenable to improvement.
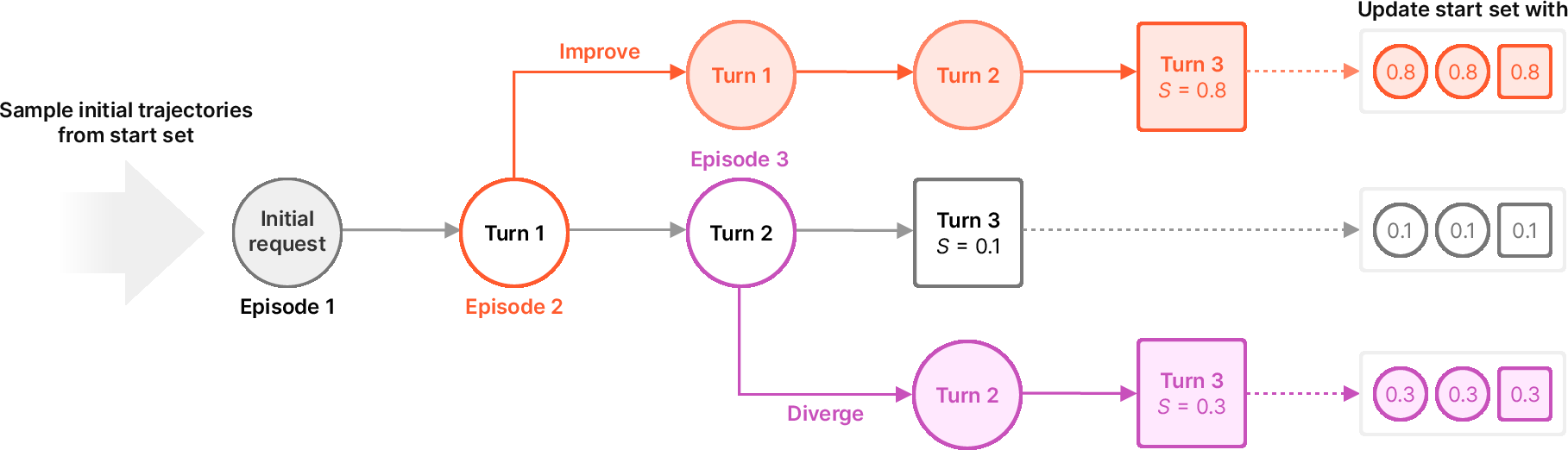
Figure 1: Overview of ExIt strategies. Each episode samples a new task or selects a partial turn history from a previous episode as a starting point for self-iteration, prioritizing those with higher group return variance.
The ExIt training loop alternates between sampling new base tasks and selecting partial histories from the buffer for further self-iteration. Two key transformations are used:
- Selection: Sampling a partial history from the buffer to serve as the starting point for a new self-improvement episode.
- Expansion: Extending a partial history by one self-improvement step, generating a new candidate for the buffer.
To further promote diversity and avoid RL-induced mode collapse, ExIt incorporates explicit exploration mechanisms:
- Self-divergence steps: With probability pdiv, the model is prompted to generate a solution that is not only improved but also significantly different from the previous attempt.
- Embedding-based diversity bonus: The group-relative advantage in GRPO is multiplicatively scaled by the embedding distance of each solution from the group centroid, upweighting novel trajectories.
Experimental Evaluation
Task Domains
ExIt is evaluated across three domains:
- Competition Math: Single-turn mathematical reasoning tasks.
- Multi-turn Tool Use: Simulated user interactions requiring sequences of function calls.
- ML Engineering (MLE-bench): Code generation and debugging tasks based on Kaggle competitions, evaluated within a greedy-search scaffold.
Baselines and Ablations
Comparisons are made against:
- The base pretrained model.
- Standard GRPO fine-tuning.
- Curriculum-only (selection without expansion).
- Improve (selection + self-improvement).
- Diverge (selection + self-divergence).
- Full ExIt (all mechanisms, including diversity bonus).
ExIt consistently improves both initial solution quality and the ability to self-improve over multiple inference-time steps, outperforming both the base model and standard GRPO fine-tuning. Notably, the full ExIt strategy and its direct exploration variants (Diverge) achieve the highest net corrections and performance gains across all domains.
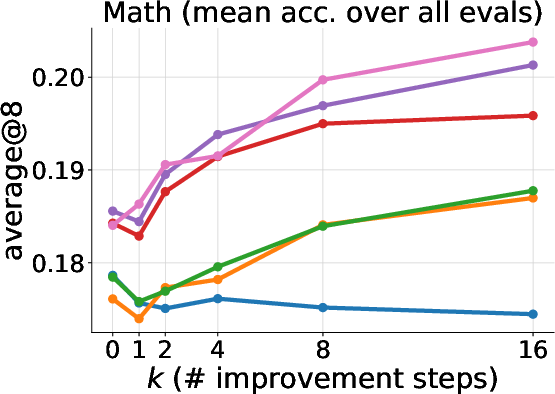
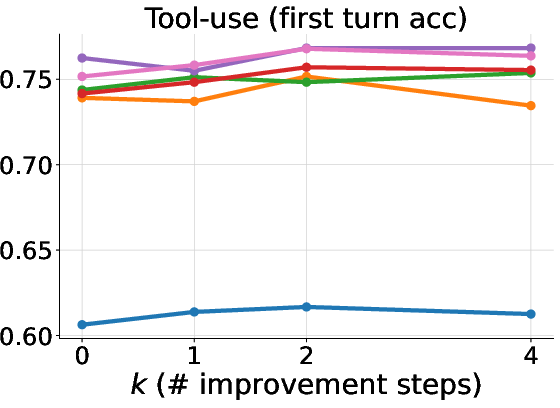
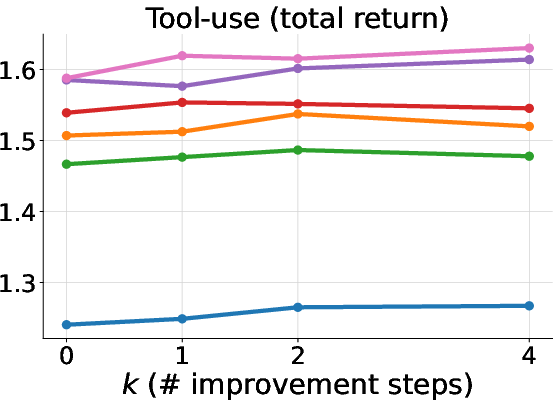
Figure 2: Left: Mean accuracy on all math test splits. Center: Mean first-turn accuracy on the multi-turn tool-use test split. Right: Mean total task return on the multi-turn tool-use test split. ExIt variants outperform baselines, especially after multiple self-improvement steps.
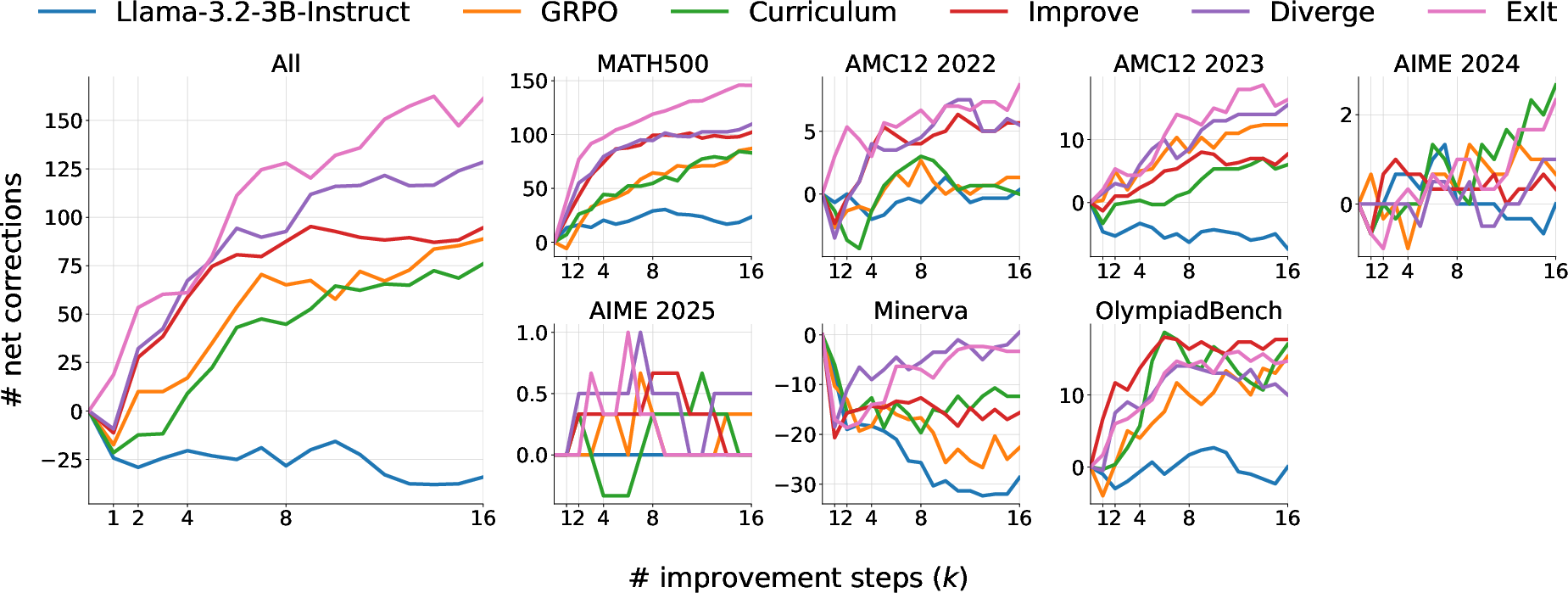
Figure 3: Net corrections across held-out math splits, showing that ExIt and Diverge accumulate more successful corrections over 16 self-improvement steps.
In the math domain, ExIt and Diverge continue to yield additional corrections even after 16 self-improvement steps, despite the mean self-iteration depth during training being less than two. In multi-turn tool use, ExIt strategies improve both first-turn and all-turn accuracy, with exploration mechanisms being critical for surpassing the GRPO baseline. In MLE-bench, ExIt enables the model to discover higher-quality solutions within the search scaffold, even when trained only on single-step iterations.
Emergent Curriculum and Task Complexity
ExIt induces an emergent curriculum by adaptively sampling task instances with the highest group return variance. This results in a natural progression toward more complex and challenging tasks over the course of training.
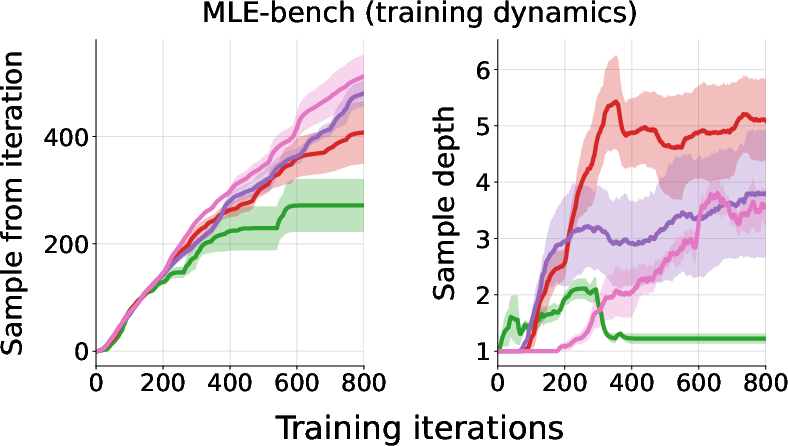
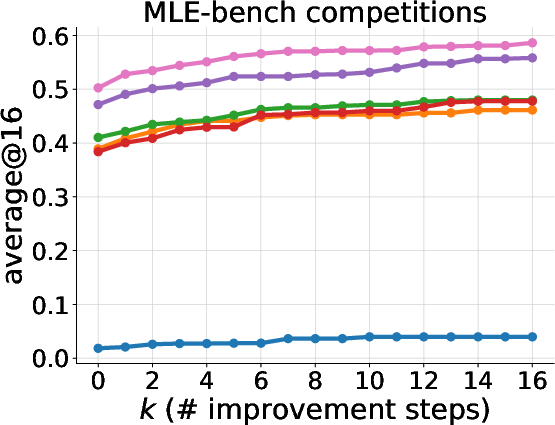
Figure 4: Left: Emergent curriculum over the sampled history's recency and starting depth during MLE-bench training. Right: Normalized MLE-bench scores achieved by each method over all train and test tasks as the greedy-search budget increases.
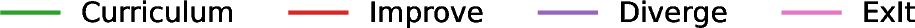
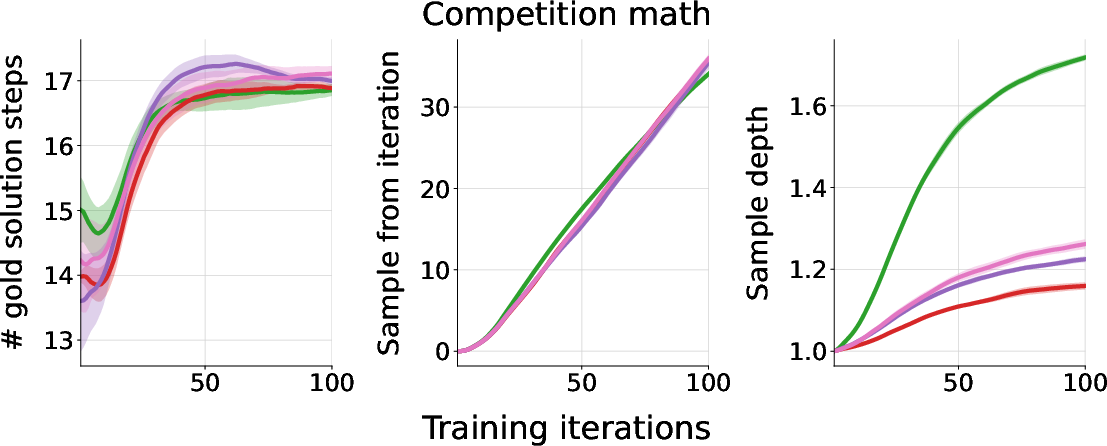
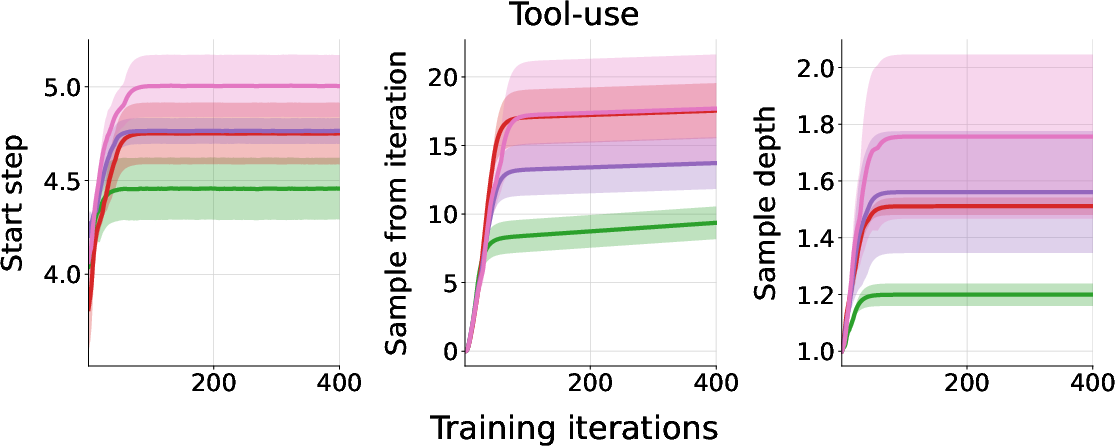
Figure 5: The evolution of various task instance properties during training in the math (left) and multi-turn tool-use (right) domains, showing increasing complexity and depth.
Task Diversity
A critical finding is that curriculum-only approaches, while focusing on learnable instances, can reduce task diversity by oversampling high-variance cases. ExIt’s self-iteration and divergence mechanisms counteract this, substantially increasing the number and diversity of distinct training instances encountered.
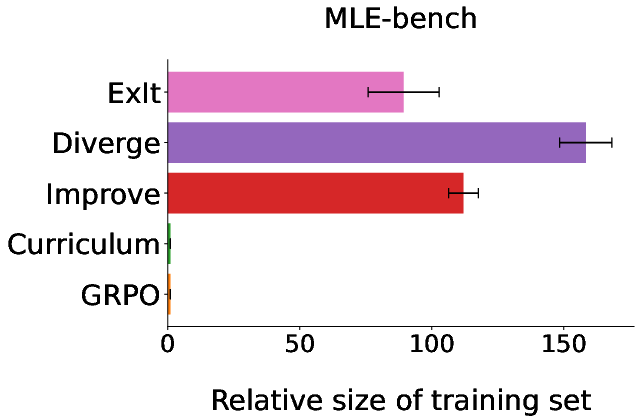
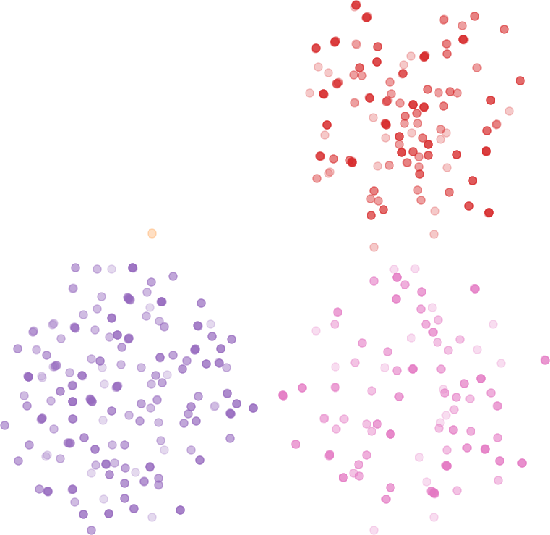
Figure 6: Relative number of distinct training task instances under each method for the multi-turn tool-use domain (left) and MLE-bench (middle). UMAP projection (right) shows ExIt strategies increase the diversity of the training distribution.
Quantitative metrics (mean pairwise cosine and L2 distances) confirm that ExIt variants, especially those with explicit novelty-seeking, achieve greater diversity in the training set.
Implementation Considerations
- Computational Efficiency: ExIt achieves K-step self-improvement capability by training only on single-step transitions, avoiding the combinatorial explosion of multi-step trajectory sampling.
- Buffer Management: The task buffer is prioritized by group return variance, with a fixed capacity. Efficient buffer updates and sampling are essential for scalability.
- Embedding Computation: The diversity bonus requires embedding each solution, which can be efficiently implemented using a frozen encoder (e.g., BERT or CodeXEmbed).
- Prompt Engineering: Self-improvement and self-divergence prompts are critical for eliciting diverse and improved solutions. Domain-specific prompt templates are provided for math, tool use, and code.
- Resource Requirements: Experiments are conducted on 3B and 7B parameter models, with batch sizes and rollout counts tuned per domain. The approach is compatible with asynchronous distributed RL training.
Theoretical and Practical Implications
ExIt demonstrates that RL fine-tuning for LLMs can be made more effective and efficient by leveraging the recurrent structure of self-improvement tasks. The method bridges ideas from autocurriculum learning, prioritized replay, and diversity-driven exploration, showing that open-ended task-space bootstrapping can yield robust, generalizable self-improvement policies. The approach is particularly well-suited for settings where inference-time iteration is the norm, such as search scaffolds for code generation or multi-turn dialog systems.
Strong empirical results include:
- ExIt achieves up to 2.0% absolute improvement in math accuracy and 8.4–11.9% in MLE-bench normalized scores over GRPO.
- ExIt variants accumulate over 170 successful corrections across held-out math problems after 16 self-improvement steps.
- ExIt-trained models generalize to deeper self-improvement at inference than seen during training.
Limitations and Future Directions
- Stochastic Environments: The current variance-based learnability metric is tailored to deterministic tasks; extensions to stochastic settings are left for future work.
- Prompt Sensitivity: The effectiveness of self-improvement and divergence steps depends on prompt design, which may require domain-specific tuning.
- Scalability: While demonstrated on 3B/7B models, scaling to larger models and more complex domains may require further engineering, especially for buffer and embedding management.
Potential future developments include:
- Integrating more sophisticated diversity metrics or generative task augmentation.
- Extending ExIt to hierarchical or multi-agent settings.
- Applying ExIt to domains with weaker or delayed reward signals, leveraging its autocurriculum properties.
Conclusion
ExIt provides a principled and practical framework for RL fine-tuning of LLMs in self-improvement settings, enabling efficient training for multi-step inference-time improvement using only single-step transitions. By adaptively bootstrapping the task space and promoting diversity, ExIt yields models that are both more robust and more capable of iterative refinement across a range of domains. The approach is directly applicable to real-world systems that rely on iterative LLM inference, such as code search scaffolds and multi-turn assistants, and opens new avenues for autocurriculum-driven RL in language modeling.