- The paper introduces a recursive problem decomposition method that enables LLMs to generate and solve simpler variants for improved problem-solving.
- It leverages adaptive quadrature and reinforcement learning (GRPO) to verify solutions and dynamically calibrate task difficulty.
- Empirical results demonstrate significant gains, with a Llama 3.2 3B model advancing from 1% to 82% accuracy on integration tasks.
LADDER: Self-Improving LLMs Through Recursive Problem Decomposition
The paper "LADDER: Self-Improving LLMs Through Recursive Problem Decomposition" introduces an innovative framework for enhancing LLMs through self-guided learning techniques focused on recursive problem decomposition. Unlike prior methods relying on curated datasets or human feedback, LADDER leverages a model's intrinsic capabilities to generate easier question variants, fostering autonomous improvement in problem-solving.
Introduction to LADDER
Framework Overview
LADDER stands for Learning through Autonomous Difficulty-Driven Example Recursion, emphasizing the recursive generation and resolution of simpler variants of complex problems. This approach is particularly relevant in reinforcement learning (RL) contexts where the choice and calibration of task difficulty are crucial. The challenge is obtaining verifiable tasks aligned with the model's current capabilities, which LADDER addresses by allowing models to bootstrap their learning via recursive variant generation.
Core Components
The framework primarily involves:
- Variant Generation: The creation of easier problem variants utilizing the model’s internal knowledge.
- Solution Verification: A numerical method, specifically integration checking, to verify correct solutions objectively.
- Reinforcement Learning: Employing GRPO without a critic model, utilizing group advantages for efficient learning.
Through these components, LADDER demonstrates significant advancements in mathematical reasoning abilities, particularly in indefinite integration tasks, outperforming both human-level and large model baselines.
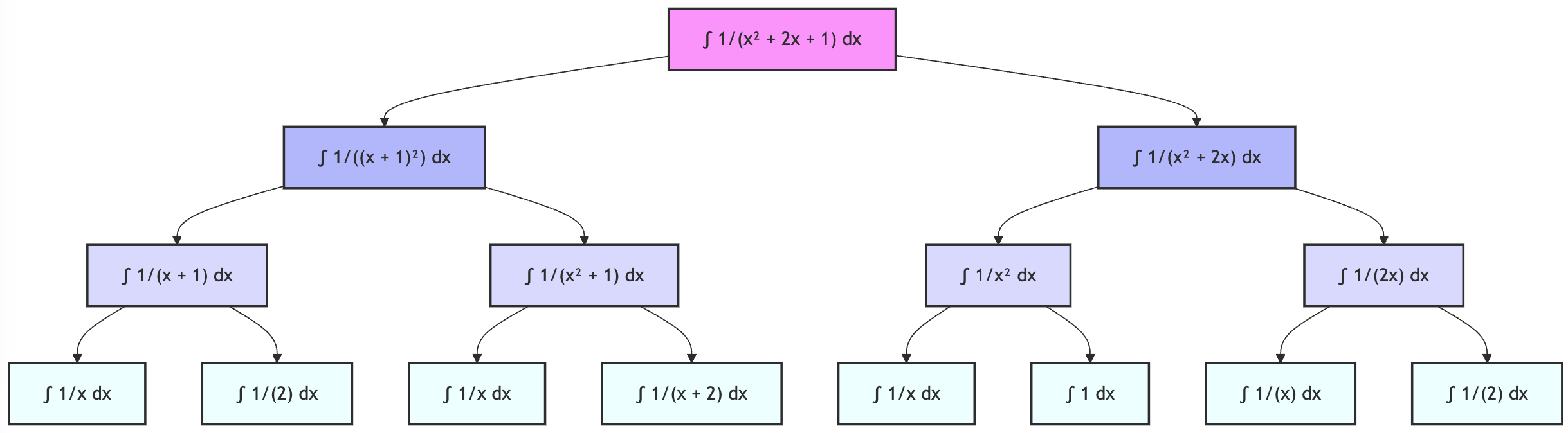
Figure 1: Example of variant generation for an integration problem. Each level represents progressively simpler variants of the original problem. The tree structure ensures each variant has exactly one parent, maintaining a clear progression of difficulty.
Test-Time Reinforcement Learning (TTRL)
Conceptual Expansion
Building upon the LADDER framework, Test-Time Reinforcement Learning (TTRL) extends these principles to inference time. The approach involves dynamically generating problem variants during testing, enabling micro-learning sessions tailored to each instance. Through focused reinforcement learning protocols applied to these variants, TTRL allows models to refine their problem-solving strategies directly at test time.
Implementation Strategy
TTRL comprises:
- Dynamic Variant Generation: Generating a reduced depth tree of variants specific to each test problem. Variants are generated recursively up to two levels.
- On-the-fly Learning: Applying brief reinforcement learning cycles to refine problem-specific strategies, leveraging previously learned patterns and verification methods.
By harnessing compute resources strategically, TTRL transforms test-time complexities into training data, dramatically enhancing model performance on challenging benchmarks.
Methodology
LADDER Algorithm
The LADDER algorithm involves two primary phases: the generation of variant trees and subsequent reinforcement learning. Variant generation requires crafting a tree of progressively simpler integrals, facilitating a smooth difficulty gradient ideal for incremental learning. Solution verification depends on adaptive quadrature for numerical comparison, ensuring reliable assessment even for complex functions.
Self-Guided Improvement Mechanism
The model autonomously adjusts its learning path through recursive decomposition, generating and practicing easier variants. Testing under LADDER yields significant improvements, as seen with a Llama 3.2 3B model advancing from 1% to 82% accuracy in solving undergraduate-level integrals.
Empirical Results
LADDER applied to mathematical reasoning tasks achieved remarkable results, surpassing typical human performance on the MIT Integration Bee by adapting difficulty dynamically during both training and inference phases.
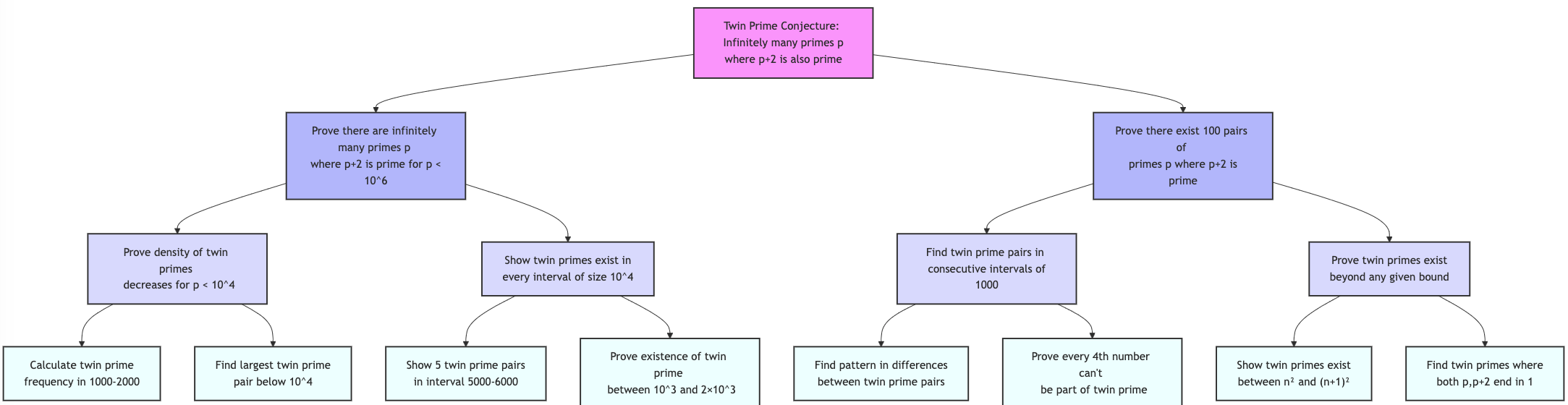
Figure 2: Example of variant generation for twin prime conjecture problem.
Discussion and Implications
Test-Time Compute Scaling
Test-time compute scaling, as demonstrated through TTRL, offers a profound shift from traditional architectural scaling methods. Instead of merely increasing parameters or sampling length, TTRL utilizes compute to dynamically enhance models' expertise during inference, presenting new opportunities for solving complex, out-of-distribution tasks efficiently.
Extension to Other Domains
The LADDER framework's principles potentially extend to other formally verifiable domains, such as competitive programming and formal theorem proving. As long as a domain features a generator-verifier gap, LADDER's recursive decomposition and self-verification methods could facilitate substantial improvements.
Conclusion
The introduction of LADDER, alongside TTRL enhancements, emphasizes the capacity for autonomous learning in LLMs, demonstrating potential scalability beyond architectural expansions. This approach shows promise for advancing AI systems towards increased autonomy, enabling them to self-improve across more complex scenarios and domains, guided solely by formal verification mechanisms.