Differentiable Entropy Regularization for Geometry and Neural Networks
Published 3 Sep 2025 in cs.LG and cs.AI | (2509.03733v1)
Abstract: We introduce a differentiable estimator of range-partition entropy, a recent concept from computational geometry that enables algorithms to adapt to the "sortedness" of their input. While range-partition entropy provides strong guarantees in algorithm design, it has not yet been made accessible to deep learning. In this work, we (i) propose the first differentiable approximation of range-partition entropy, enabling its use as a trainable loss or regularizer; (ii) design EntropyNet, a neural module that restructures data into low-entropy forms to accelerate downstream instance-optimal algorithms; and (iii) extend this principle beyond geometry by applying entropy regularization directly to Transformer attention. Across tasks, we demonstrate that differentiable entropy improves efficiency without degrading correctness: in geometry, our method achieves up to $4.1\times$ runtime speedups with negligible error ($<0.2%$); in deep learning, it induces structured attention patterns that yield 6% higher accuracy at 80% sparsity compared to L1 baselines. Our theoretical analysis provides approximation bounds for the estimator, and extensive ablations validate design choices. These results suggest that entropy-bounded computation is not only theoretically elegant but also a practical mechanism for adaptive learning, efficiency, and structured representation.
The paper proposes a smooth surrogate for range-partition entropy that is differentiable and enables its integration as a loss or regularizer in neural architectures.
The method, exemplified by EntropyNet, restructures high-entropy point clouds into low-entropy outputs, achieving up to a 4.1× speedup in geometric computations with minimal error.
Entropy regularization applied to Transformer attention induces structured, semantic sparsity, resulting in a 6% accuracy gain at 80% sparsity over traditional methods.
Differentiable Entropy Regularization for Geometry and Neural Networks
Introduction and Motivation
The paper presents a differentiable estimator for range-partition entropy, a complexity measure from computational geometry that quantifies the "sortedness" or structural regularity of data. This measure has enabled instance-optimal algorithms with runtime guarantees sensitive to input structure, but has not previously been accessible to deep learning due to its combinatorial nature. The authors introduce a smooth, trainable surrogate for range-partition entropy, enabling its use as a loss or regularizer in neural architectures. They demonstrate its utility in two domains: geometric preprocessing for algorithm acceleration and structured sparsity induction in Transformer attention.
Differentiable Range-Partition Entropy Estimator
The core technical contribution is a differentiable surrogate for range-partition entropy. The estimator is constructed by assigning each data point to a set of learnable anchors (via soft k-means or soft halfspace indicators), computing assignment probabilities, and then calculating the entropy of the resulting soft partition. The estimator is smooth in both data and anchor parameters, scale-invariant, and permutation-invariant, making it suitable for unordered sets such as point clouds.
The authors further refine the estimator to be range-family–aware, replacing ball-based clustering with soft halfspace indicators for geometric tasks. Theoretical analysis provides data-dependent bounds on the approximation error between the differentiable surrogate and the true combinatorial entropy, with guarantees that depend on empirical margin and sample size.
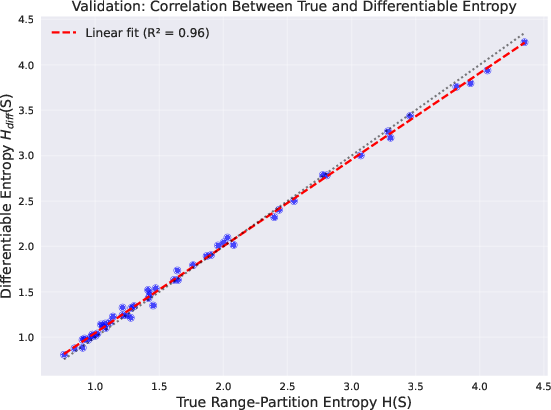
Figure 1: Strong linear correlation (R2=0.96) between the differentiable estimator and true range-partition entropy across training iterations validates the surrogate's fidelity.
EntropyNet: Geometric Preprocessing for Algorithmic Acceleration
EntropyNet is a neural module designed to restructure point clouds into low-entropy configurations, thereby accelerating downstream geometric algorithms such as convex hull and Delaunay triangulation. The architecture follows PointNet principles, with shared pointwise MLPs, global max-pooling, and residual coordinate adjustments. The training objective combines Chamfer distance for geometric fidelity, entropy regularization for structure induction, and a stability term to prevent excessive deformation.
Empirical results show that EntropyNet preprocessing yields up to 4.1× speedup for convex hull computation on high-entropy data, with negligible geometric error (<0.2%). The method generalizes to large-scale datasets (n=106) and other algorithms (Delaunay triangulation, 3D maxima), maintaining significant runtime improvements and improved F1 scores for maxima identification.
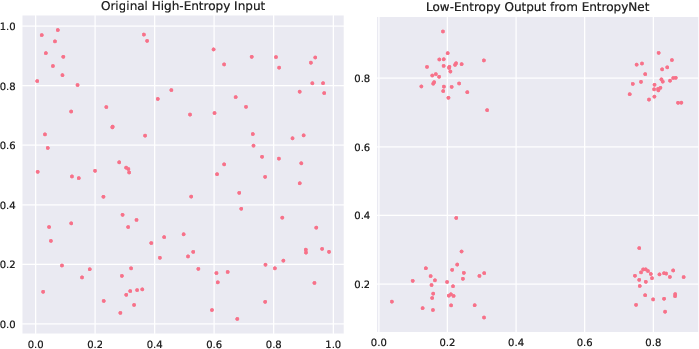
Figure 2: EntropyNet transforms high-entropy point sets into low-entropy outputs, preserving global structure while improving local ordering.
Entropy Regularization for Transformer Attention
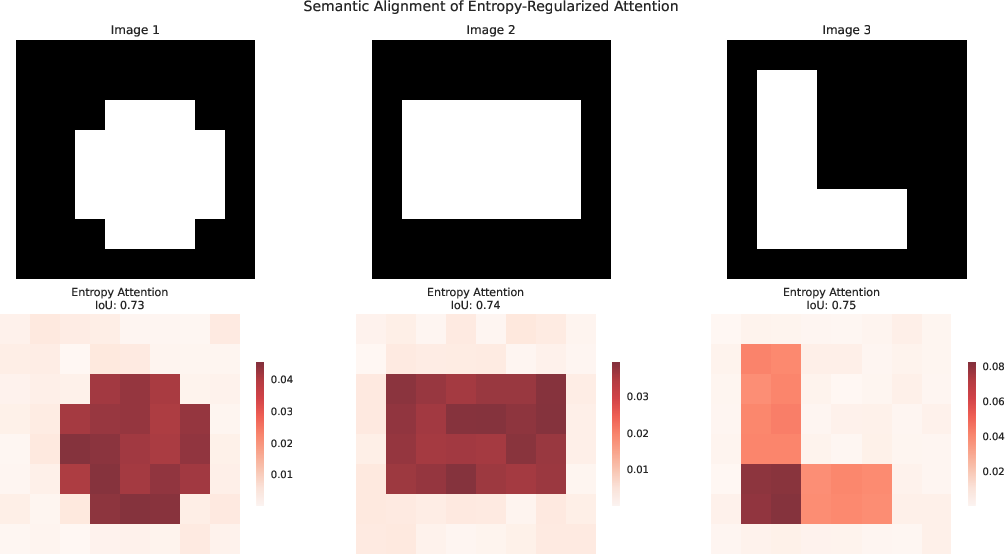
The differentiable entropy estimator is applied as a regularizer to Transformer attention matrices, encouraging each query to attend to a structured, low-entropy subset of keys. This induces semantic sparsity patterns that align with object boundaries and meaningful regions in both vision and language tasks.
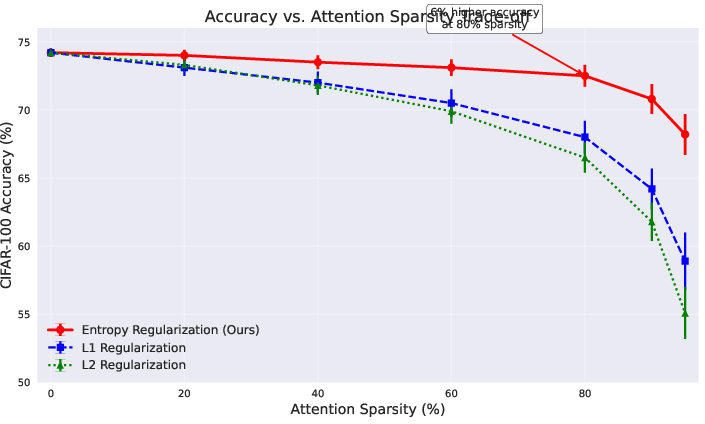
On ViT for CIFAR-100, entropy regularization achieves a superior accuracy-sparsity trade-off compared to L1/L2 and other sparsity-inducing baselines, with 6% higher accuracy at 80% sparsity. The method generalizes to large-scale ImageNet classification, long-sequence language modeling (WikiText-103), and BERT-based classification (GLUE SST-2), consistently outperforming standard regularization in accuracy at matched sparsity.
Figure 3: Entropy regularization yields a superior accuracy vs. sparsity trade-off for ViT on CIFAR-100 compared to L1/L2 and other baselines.
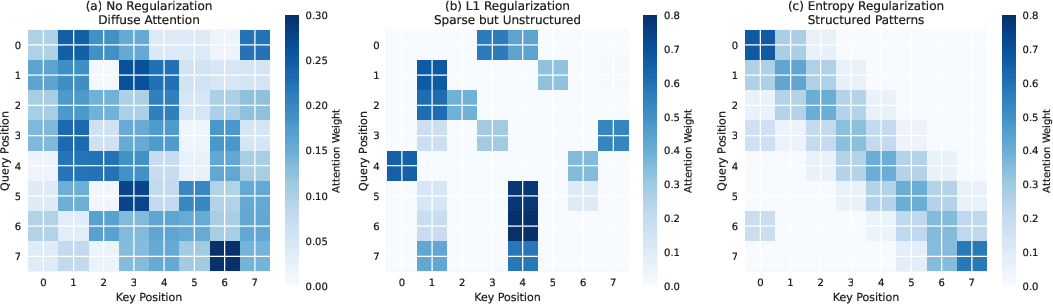
Figure 4: Entropy regularization produces structured, semantic attention patterns, in contrast to diffuse or unstructured patterns from other regularizers.
Figure 5: Attention maps from entropy-regularized models align with object boundaries, as measured by IoU scores.
Theoretical Guarantees and Ablation Analysis
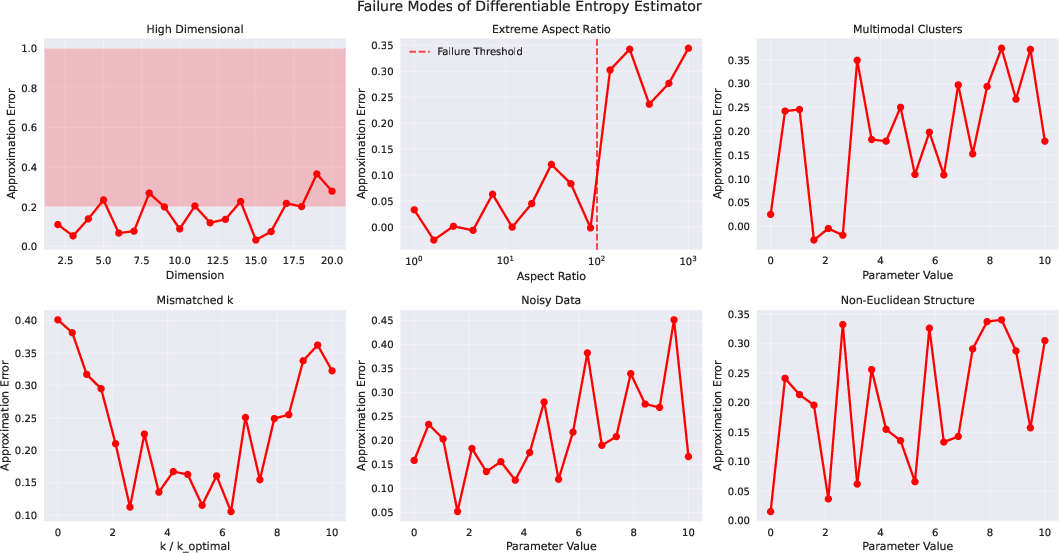
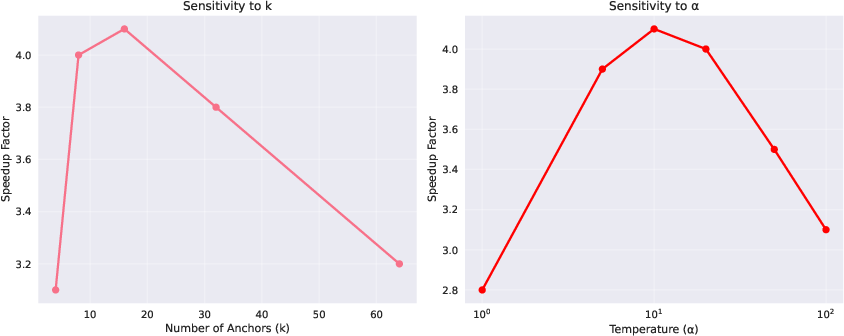
The paper provides formal bounds on the approximation error of the differentiable entropy estimator, showing exponential decay with empirical margin and O((logm)/n) statistical error. Ablation studies confirm the importance of learnable anchors, appropriate temperature (α), and range-family–aware surrogates for optimal performance. The estimator's correlation with true entropy is validated empirically, and failure modes are analyzed, including high-dimensionality, aspect ratio extremes, and mismatched anchor counts.
Figure 6: Failure modes of the differentiable entropy estimator, with red regions indicating parameter ranges where approximation quality degrades.
Figure 7: Heatmap of runtime speedup as a function of k and α, validating the robustness of the heuristic-based selection.
Computational Complexity and Implementation Considerations
The computational overhead of entropy regularization is O(nk) for geometric tasks and O(N2k) for attention with sequence length N. Empirically, training time overhead is up to 18.3% for large models, but can be reduced via approximate nearest-neighbor search (e.g., FAISS). The method is most effective when the underlying problem admits a low-entropy structure; in highly optimized or inherently high-entropy scenarios, the benefits are primarily interpretability and structured compression rather than raw throughput.
Implications and Future Directions
The work establishes a principled connection between deep learning and algorithmic efficiency, enabling neural networks to induce structures that are provably optimal for downstream algorithms. The entropy regularization framework is broadly applicable, with potential extensions to graph neural networks (entropy over neighborhood structures), reinforcement learning (entropy-guided exploration), and structured prediction. Future research may focus on margin-free guarantees, distribution-agnostic bounds, and scaling to industrial-scale models.
Conclusion
The paper introduces a differentiable approximation of range-partition entropy, bridging the gap between algorithmic complexity measures and deep learning. The method enables adaptive, efficient neural architectures that induce structured representations aligned with algorithmic guarantees. Empirical results demonstrate significant speedups and superior accuracy-sparsity trade-offs across geometry, vision, and language tasks. The approach opens new avenues for principled efficiency improvements and interpretable model design in AI.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.