- The paper introduces a two-stage training strategy that extracts and optimally weighs discrete tokens from SSL models to improve multilingual ASR performance.
- The methodology leverages a weighted summation of layer contributions, resulting in a 44% decrease in Character Error Rate on the ML-SUPERB dataset.
- Fine-tuning shifts weight distribution in SSL models, narrowing the performance gap between discrete and continuous speech representations.
Multilingual Speech Recognition Using Discrete Tokens with a Two-step Training Strategy
Introduction
The paper explores a novel approach to multilingual Automatic Speech Recognition (ASR) by leveraging discrete tokens within a two-stage training framework. Aimed at bridging the performance gap between discrete and continuous speech representations, this research primarily employs pre-trained Self-Supervised Learning (SSL) models such as XLS-R. The authors emphasize the challenge posed by varying language representation contributions across different layers of these models, highlighting the necessity to optimize discrete unit utilization in multilingual contexts.
Two-Stage Training Strategy
The authors propose a two-stage training strategy designed to enhance the quality of discrete tokens extracted from SSL models. Initially, continuous representations are used to gauge the contribution weight of each model layer to ASR tasks. Specifically, a weighted summation, termed weighted_sum, is utilized to derive these representations, effectively capturing the distinct information embedded across different layers.
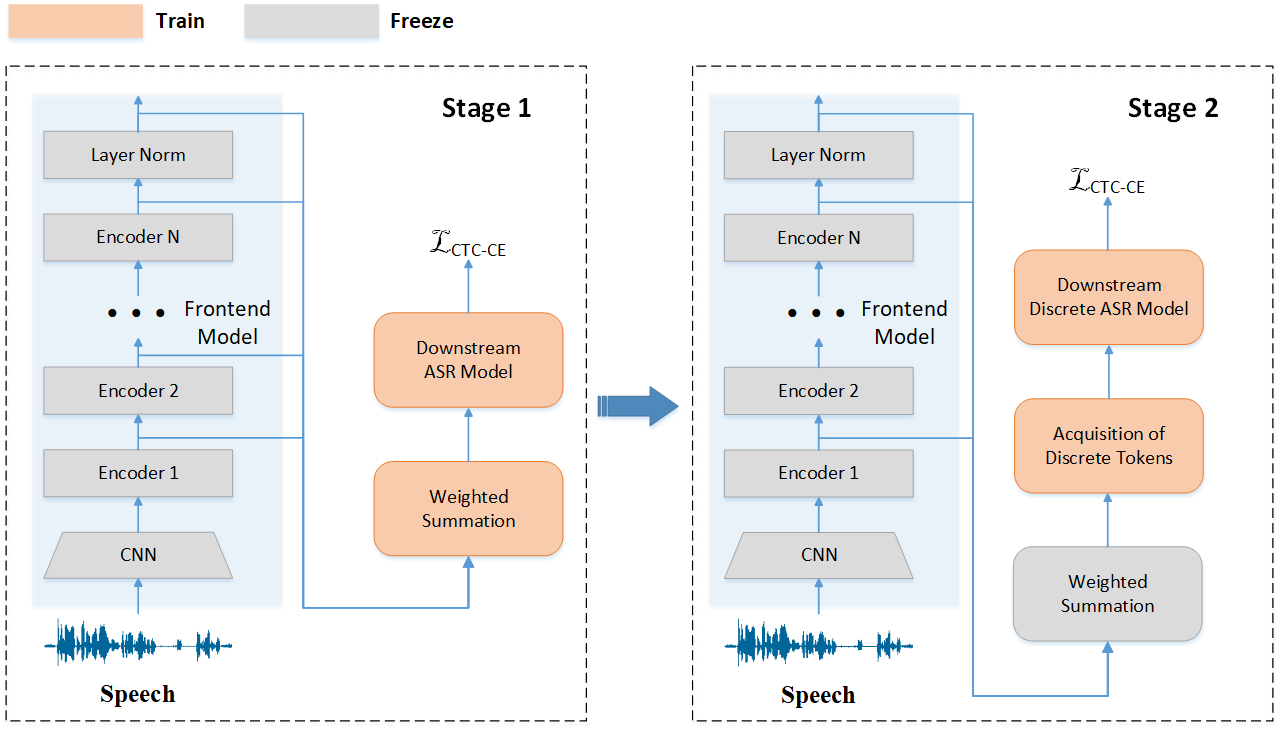
Figure 1: Two-stage discrete speech unit ASR system architecture.
In the second stage, these determined weights are fixed, facilitating the extraction of discrete tokens for training an ASR model that leverages these tokens as primary inputs. Notably, a fine-tuning step precedes this two-stage process, where pre-existing SSL models are refined with a limited dataset to improve their handling of word identities.
Experimental Results
The implementation of this methodology demonstrates a substantial improvement, with a 44% relative decrease in Character Error Rate (CER) over the XLS-R baseline on the ML-SUPERB dataset. This marks a significant advancement over previous methods, such as the WavLM model, which reported a 26% reduction. Additionally, the proposed strategy closes the performance gap between discrete tokens and continuous representations, with discrete token CER lagging by only 8% in optimal scenarios.
Model Architecture and Layer Contributions
The paper pays particular attention to how model architecture impacts the performance of discrete token systems. Utilizing the XLS-R model as a case study, the authors illustrate that fine-tuning significantly shifts weight distribution toward final model layers, where language identity is more prominent.
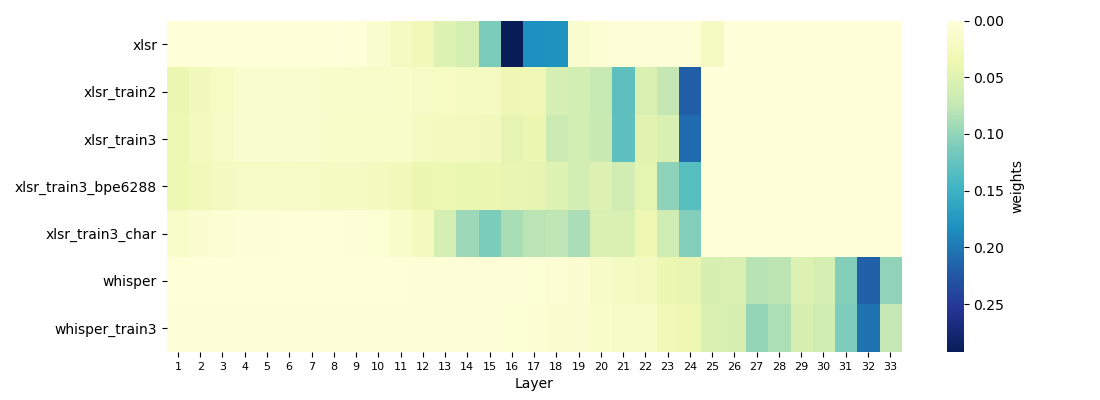
Figure 2: Weight distribution of different models on train_2. The XLSR pre-trained model has 25 layers of weights, whereas its fine-tuned version has 24 layers. To ensure alignment in the plot with the weights of the Whisper model (33 layers), we set the weights of the remaining layers in the XLSR-based models to 0.
This shift indicates that the effectiveness of discrete tokens is intrinsically linked to the quality of fine-tuning applied to the SSL models, suggesting a uniform approach to multilingual ASR models.
Conclusions
The two-stage training strategy introduced in this paper marks a notable progress in enhancing multilingual ASR performance using discrete tokens. By effectively utilizing layer-specific contributions in SSL models, the proposed method achieves competitive results, underscoring its potential in practical multilingual applications. These findings pave the way for further exploration into discrete token optimization, aiming to fully harness their advantages over continuous representations in diverse ASR environments. Future research could extend this work by exploring more refined methods of discrete token generation that retain comprehensive linguistic information necessary for downstream tasks.