- The paper presents InSQuAD's novel use of submodular mutual information to balance quality and diversity during exemplar selection in LLM in-context learning.
- It introduces two components, InSQuAD-RETRIEVE and InSQuAD-LEARN, that employ greedy optimization and likelihood-based training to optimize exemplar relevance and diversity.
- Experiments demonstrate significant performance gains and faster inference across benchmarks, highlighting the framework’s practical benefits for scalable ICL.
InSQuaD: Submodular Mutual Information for Quality and Diversity in In-Context Learning
Introduction
The paper presents InSQuaD, a unified combinatorial framework for exemplar selection and retrieval in In-Context Learning (ICL) with LLMs. InSQuaD leverages Submodular Mutual Information (SMI) functions to enforce quality, diversity, and order among in-context exemplars, addressing key limitations in prior ICL retrieval strategies that typically focus on query relevance while neglecting diversity. The framework consists of two principal components: InSQuaD-RETRIEVE, which models annotation and retrieval as a targeted selection problem, and InSQuaD-LEARN, which introduces a novel likelihood-based training objective for retrieval models to encode both quality and diversity.
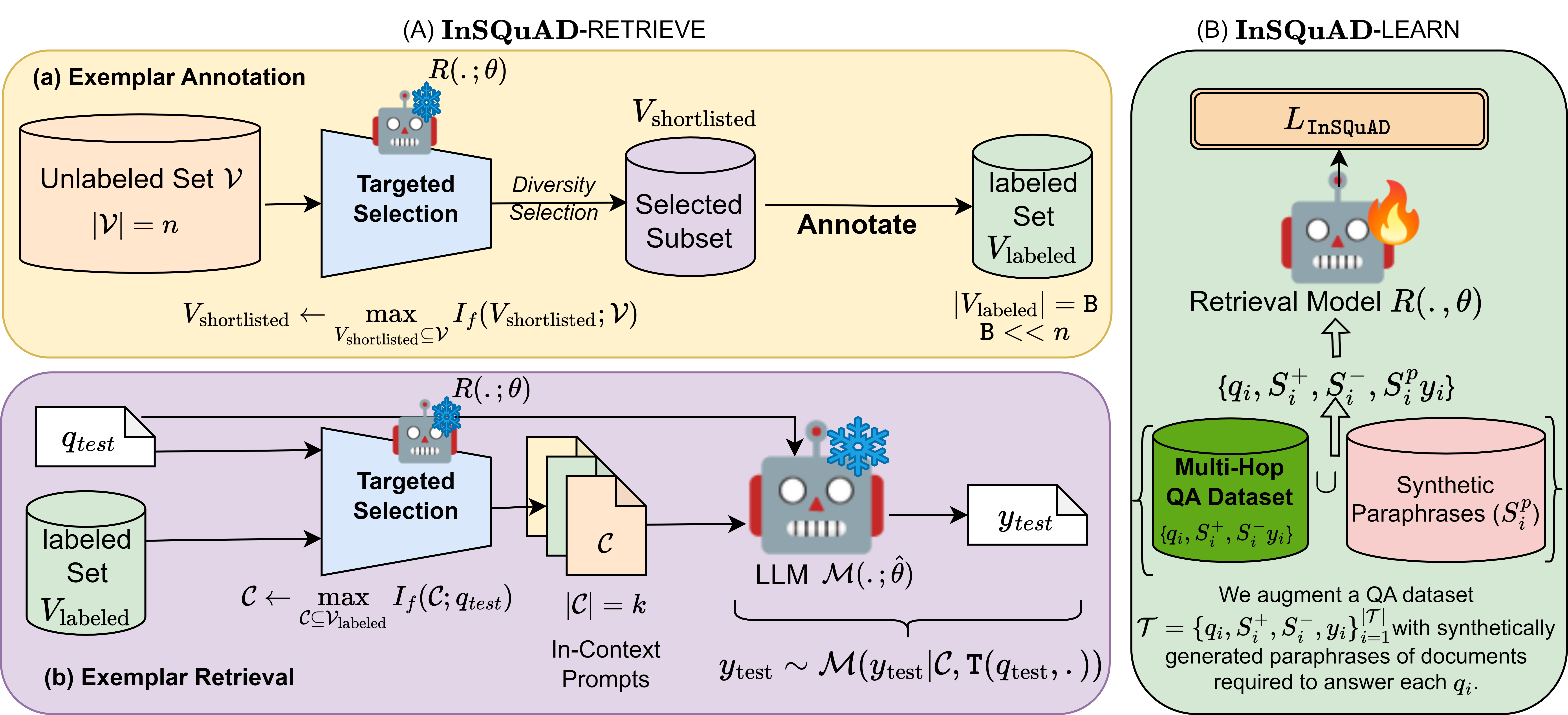
Figure 1: Overview of InSQuaD comprising two principal components—RETRIEVE for targeted selection and LEARN for enforcing quality and diversity in the retrieval model.
Methodology
InSQuaD-RETRIEVE formulates both exemplar annotation and retrieval as a targeted selection problem using SMI functions. During annotation, the method maximizes SMI over the unlabeled pool to select a diverse subset for human labeling. For retrieval, SMI is maximized between the test query and labeled exemplars, ensuring the selected in-context examples are both relevant and diverse. Greedy optimization is employed, which implicitly orders exemplars by incremental information gain, aligning with the requirements of ICL.
Likelihood-Based Training for Quality and Diversity
InSQuaD-LEARN introduces a family of likelihood-based loss functions derived from Submodular Point Processes (SPPs). The training objective maximizes the likelihood of selecting relevant exemplars while minimizing the likelihood of selecting distractors and paraphrases, thus enforcing both quality and diversity in the learned retrieval model. The loss is defined as:
L=−log(αQθ)=log(If(S−;Q))−log(If(S+;Q))
where If is the SMI function, S+ are relevant exemplars, and S− are distractors. The joint loss combines quality and diversity terms, controlled by a hyperparameter λ.
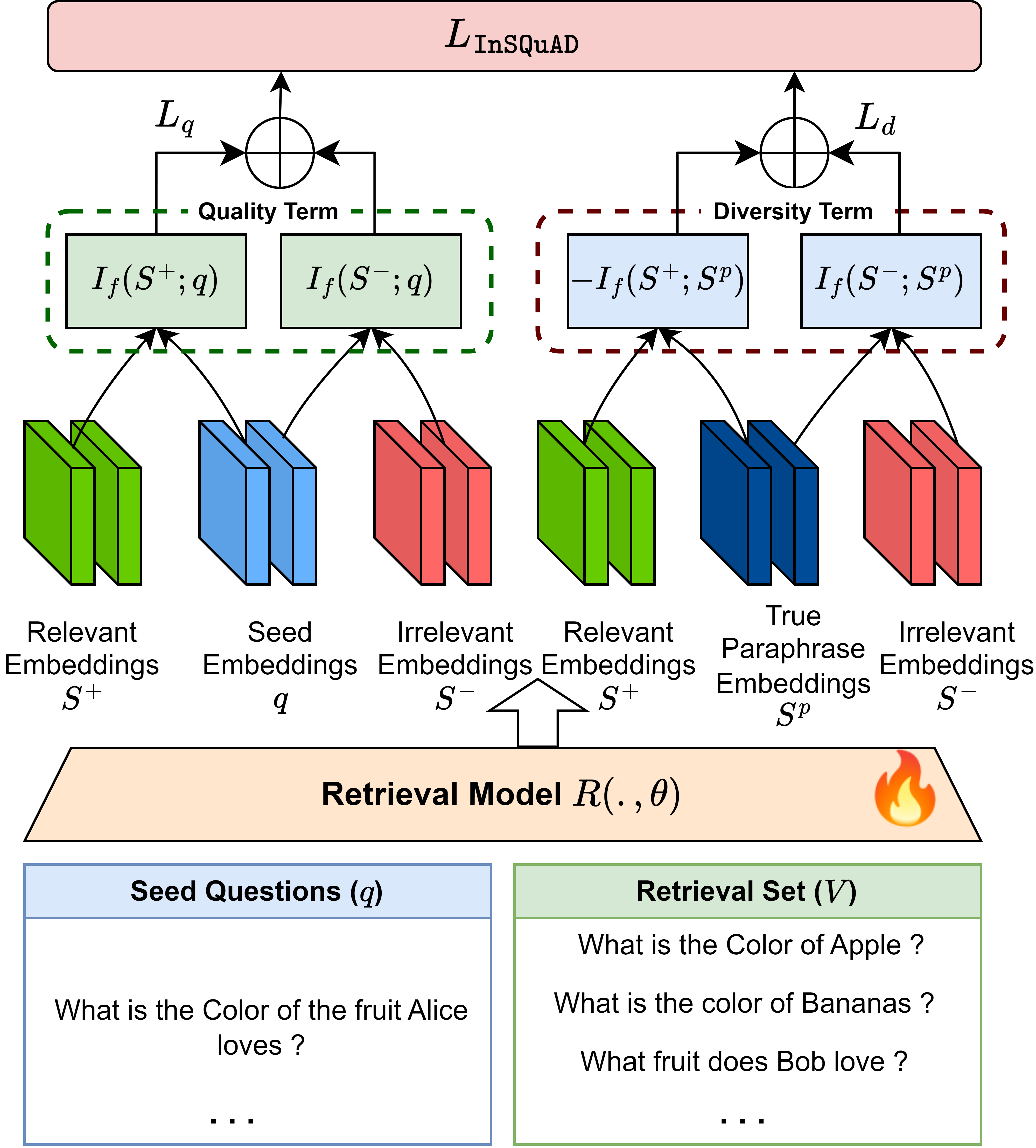
Figure 2: Training workflow of InSQuaD-LEARN, updating retrieval model parameters via a likelihood-based SMI objective.
Instantiations and Training Data
Three instantiations of the SMI function are explored: Facility-Location (FL), Graph-Cut (GC), and Log-Determinant (LD), each yielding different trade-offs in quality and diversity. To facilitate training, the authors augment the HotpotQA multi-hop question answering dataset with synthetic paraphrases generated via GPT-3.5 Turbo, enabling explicit modeling of diversity.
Experimental Results
InSQuaD is evaluated on nine ICL benchmarks spanning classification, multi-choice, dialogue, and generation tasks. The framework consistently outperforms baselines such as Zero-shot, Random, Vote-K, and IDEAL, with improvements up to 21.6% on classification, 16.4% on multi-choice, and 7% on generation tasks. Notably, the Graph-Cut instantiation (InSQuaD-GC) achieves the best average performance and rank across tasks.
Inference Efficiency
The combinatorial approach of InSQuaD significantly reduces inference time compared to iterative selection methods, making it suitable for practical ICL deployments.
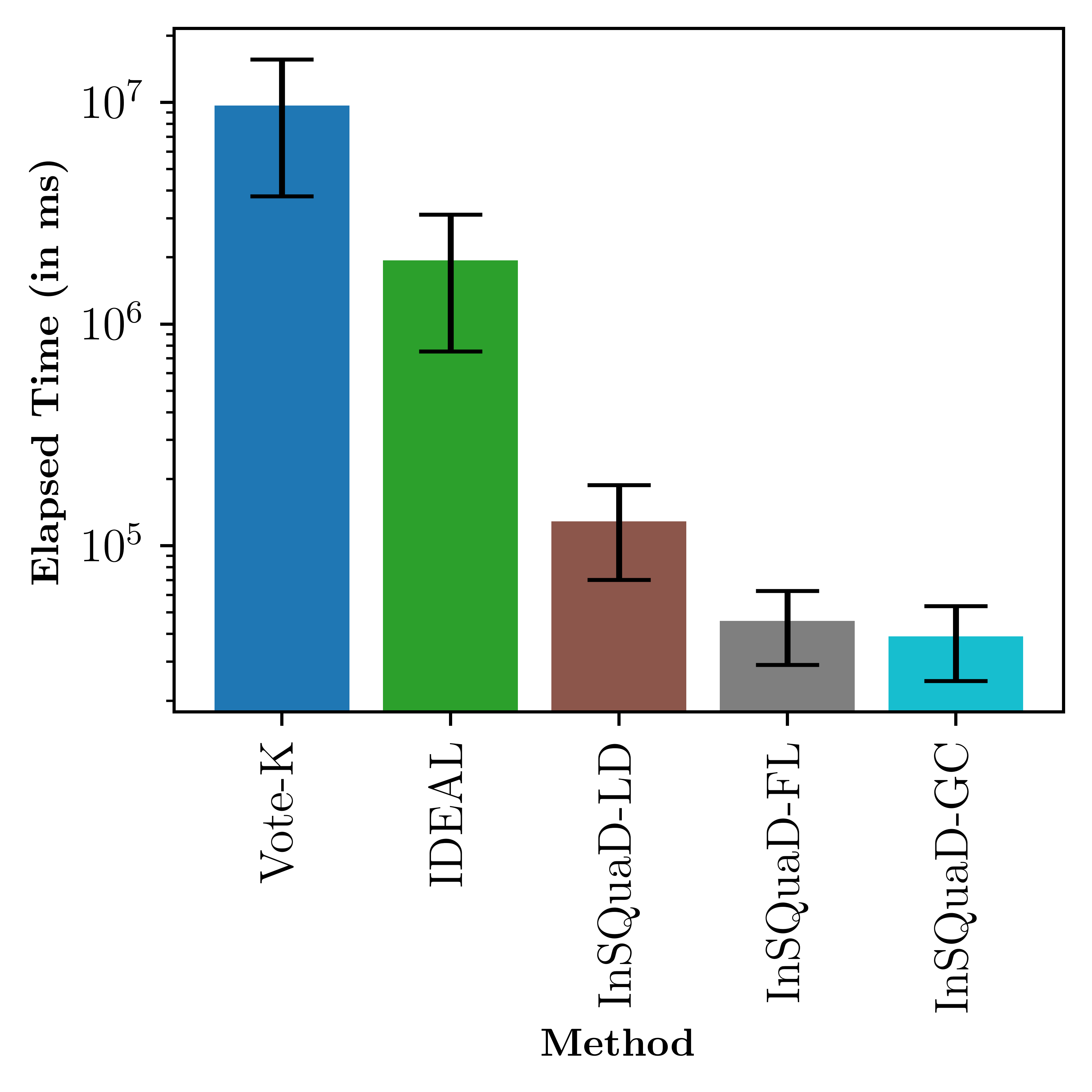
Figure 3: Comparison of inference time (log scale) across methods; combinatorial selection in InSQuaD yields substantial speedups.
Ablation Studies
Ablations reveal that:
Practical and Theoretical Implications
InSQuaD demonstrates that joint modeling of quality, diversity, and order via SMI functions is critical for effective ICL. The likelihood-based training paradigm for retrieval models enables direct optimization for downstream ICL objectives, moving beyond query relevance. The combinatorial selection strategy not only improves accuracy but also enhances computational efficiency, which is essential for scaling ICL in production environments.
The framework's reliance on synthetic paraphrase augmentation highlights the importance of data curation for diversity modeling. The results suggest that further exploration of multi-hop QA datasets and mitigation of selection biases could yield additional gains.
Conclusion
InSQuaD provides a principled, efficient, and empirically validated approach for exemplar selection and retrieval in ICL, leveraging submodular mutual information to enforce quality, diversity, and order. The framework achieves strong numerical improvements over baselines and offers practical advantages in inference speed and generalizability. Future work should address selection bias, extend to other QA datasets, and improve interpretability of the selection process.