- The paper introduces the Uniform framework, which unifies knowledge from diverse pre-trained models via innovative feature and logits voting mechanisms.
- It employs feature alignment with reconstruction losses and pseudo-label-based distillation to reconcile conflicts among teacher predictions.
- Experimental results across 11 benchmark datasets demonstrate superior scalability and performance improvements over traditional knowledge distillation methods.
The technical advancement in deep learning has led to a proliferation of publicly available pre-trained models, each offering unique insights into the real world. The paper "UNIFORM: Unifying Knowledge from Large-scale and Diverse Pre-trained Models" introduces a novel framework called Uniform, which effectively integrates knowledge from heterogeneous pre-trained models to enhance unsupervised object recognition.
Introduction
The rapid accumulation of pre-trained models available on platforms like HuggingFace has opened avenues for harnessing the diverse expertise embedded within these models. Despite the wealth of knowledge, challenges arise due to varying network architectures and the heterogeneity of data on which these models are trained. Traditional methods such as model merging, mixture-of-experts, and knowledge distillation impose constraints on architecture and data homogeneity, often resulting in biases.
Uniform addresses these limitations by proposing a framework that enables knowledge transfer from both homogeneous models—those sharing architecture and label space—and heterogeneous models with distinct architectures or data classes.
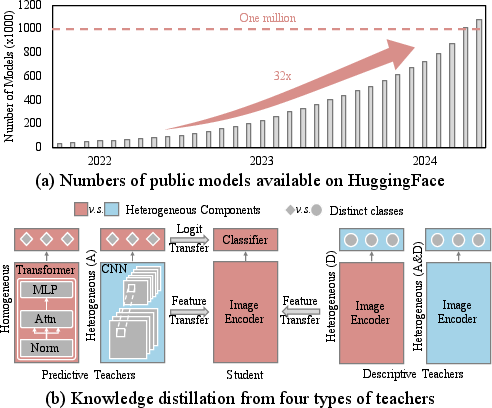
Figure 1: The dramatic increase in publicly available models and an introduction to Uniform’s approach in knowledge transfer.
Methodology
Uniform's methodology hinges on two innovative voting mechanisms designed to extract consensus knowledge from a range of teacher models at both the feature and logit levels.
Features Voting and Transfer
The feature-level knowledge integration involves unifying the latent feature spaces of diverse teachers into a common space with the student model. This is achieved using encoders that project teacher features into an aligned space, which is regularized using reconstruction losses to prevent degeneration. The challenge of sign conflicts, where averaging teacher features could result in misleading zero vectors, is mitigated through a voting-based mechanism that aligns feature directions before aggregation.
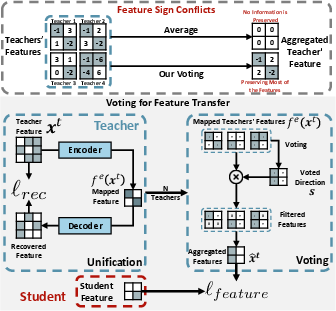
Figure 2: Mitigating sign conflicts through a two-stage framework involving voting and feature transfer.
Logits Voting and Transfer
At the logits level, discrepancies in prediction distributions among teachers are tackled by focusing on class votes. Pseudo-labels are derived by identifying the most frequent class prediction among teachers, thus emphasizing the most likely classes in the transfer process. This selective knowledge distillation reduces student confusion stemming from conflicting teacher outputs.
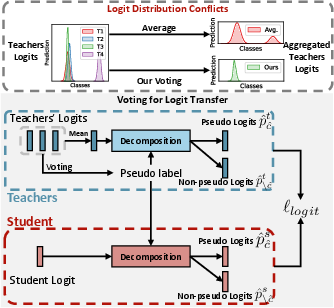
Figure 3: Decomposing knowledge transfer into pseudo and non-pseudo logits to handle distribution conflicts.
Experimental Results
The efficacy of Uniform was evaluated across 11 benchmark datasets, including CUB200, Stanford Dogs, and various others, with students displaying significant performance improvements. Uniform consistently outperformed traditional KD methods like CFL and OFA, particularly demonstrating superior scalability by managing knowledge from over one hundred pre-trained teachers without saturation.
The comparison of varying descriptive and predictive teacher numbers showed that Uniform's voting mechanisms allowed it to leverage a broader range of teacher models efficiently, maximizing the benefit drawn from freely available public knowledge.
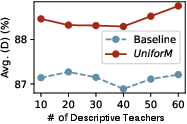
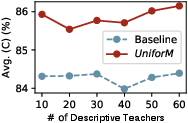
Figure 4: Performance of Uniform scaling up with an increasing number of public descriptive teachers under a multidataset configuration.
Conclusion
Uniform presents a step forward in utilizing the collective wisdom of publicly accessible pre-trained models for unsupervised tasks. By prioritizing consensus through novel voting strategies, the framework adeptly navigates the complexities associated with heterogeneous model architectures and label spaces. Its scalable performance across various datasets highlights its potential in broadening the applicability and generalizability of vision models in diverse scenarios.
This framework paves the way for future explorations into integrating knowledge from even larger model repositories and extending these methodologies to other domains beyond visual recognition.