- The paper presents an autoregressive framework that leverages cuboid abstractions to generate intersection-free, physically plausible indoor scenes.
- It integrates rejection sampling and curated datasets, achieving a 90.6% non-intersection rate in bedrooms compared to state-of-the-art methods.
- CasaGPT employs a modified Llama-3 Transformer to sequence cuboid tokens, enabling realistic scene completion and re-arrangement.
CasaGPT: Cuboid Arrangement and Scene Assembly for Intersection-Free Indoor Scene Synthesis
Introduction and Motivation
CasaGPT introduces a novel autoregressive framework for indoor scene synthesis, focusing on intersection-free arrangement of 3D objects by decomposing them into cuboid primitives. The method addresses two major limitations in prior work: (1) the prevalence of object intersections in training data and generated scenes due to coarse bounding box representations, and (2) the inability of generative models to enforce physical plausibility during synthesis. By leveraging fine-grained cuboid abstractions and integrating rejection sampling into the training pipeline, CasaGPT achieves compact, realistic, and physically plausible scene layouts.
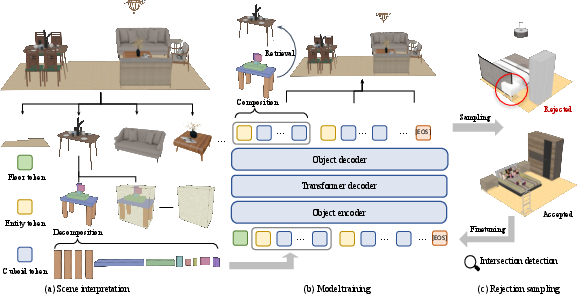
Figure 1: Overview of the CasaGPT framework for indoor scene generation, illustrating model pre-training with cuboid tokens and iterative rejection sampling for collision-free scene refinement.
Cuboid-Based Scene Representation
CasaGPT replaces traditional bounding box representations with assemblies of cuboid primitives, derived via voxelization and coarse-graining of 3D meshes. The cuboid abstraction process merges contiguous occupied voxels along principal axes, followed by iterative merging based on a dynamic threshold that penalizes excessive volume inflation. This results in a compact, yet expressive, representation of object geometry that more accurately reflects mesh-level spatial relationships.
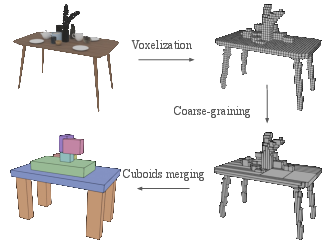
Figure 2: Workflow of voxelization, coarse-graining, and cuboid merging, yielding compact cuboid representations for 3D objects.
The scene is encoded as a sequence of tokens: each object is represented by an entity token (class, size, translation, rotation) followed by its constituent cuboid tokens, sorted by height. This tokenization enables the autoregressive model to capture both global and local spatial dependencies.
Autoregressive Modeling and Rejection Sampling
CasaGPT employs a Llama-3-based Transformer decoder, modified with RMSNorm, SwiGLU, and learned position encoding, to model the sequential arrangement of cuboid tokens. During training, teacher forcing is used to accelerate convergence and improve token prediction accuracy.
To mitigate the probabilistic generation of intersecting objects, CasaGPT integrates rejection sampling during fine-tuning. Candidate scenes are generated and filtered based on 3D IoU thresholds between cuboids; only intersection-free samples are retained for further training. This iterative process distills a policy that increasingly favors physically plausible layouts.
Dataset Curation: 3DFRONT-NC
Recognizing the limitations of the 3D-FRONT dataset, which contains numerous object intersections, the authors curate 3DFRONT-NC ("noise clean") by applying cuboid-based intersection avoidance. The process involves computing the IoU matrix for all cuboids, followed by gradient-based translation updates to eliminate intersections without perturbing non-intersecting arrangements.
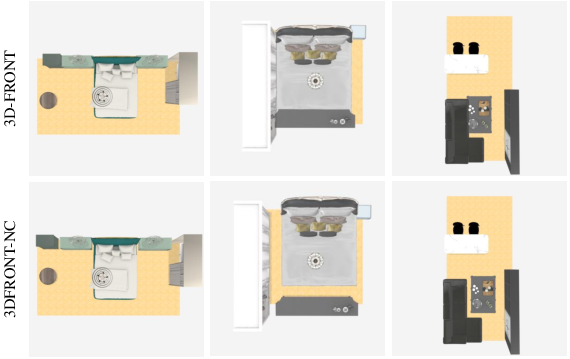
Figure 3: Dataset refinement via intersection avoidance, preserving plausible arrangements while eliminating collisions.
Quantitative analysis demonstrates that 3DFRONT-NC exhibits significantly higher non-intersection rates (NIRate) across all room types, especially bedrooms and libraries.
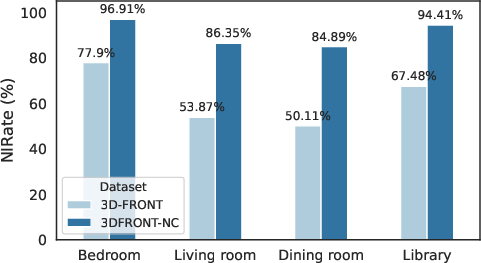
Figure 4: Non-intersection rate comparison between 3D-FRONT and 3DFRONT-NC, highlighting the effectiveness of dataset curation.
Object Retrieval and Scene Assembly
During inference, CasaGPT retrieves 3D models from the 3D-FUTURE database by matching generated cuboid assemblies to candidate objects via 3D IoU in voxel space. This fine-grained retrieval avoids the intersection issues inherent in bounding box-based nearest neighbor methods.
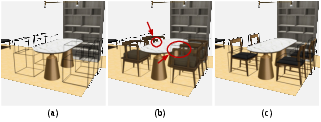
Figure 5: Comparison of object retrieval methods, demonstrating superior intersection avoidance with cuboid-based retrieval.
Experimental Results
CasaGPT is evaluated on both the original and curated datasets, outperforming state-of-the-art methods (ATISS, DiffuScene, LayoutGPT) in FID, CIoU, and NIRate metrics. On 3DFRONT-NC, CasaGPT achieves a 90.6% non-intersection rate for bedrooms, a 31% improvement over previous methods. The model also demonstrates strong generalization to complex floor plans and customized layouts.

Figure 6: Qualitative comparison of scene generation across methods, with CasaGPT exhibiting superior intersection avoidance and plausibility.
Ablation studies confirm the advantages of cuboid representation over bounding boxes for both dataset refinement and sequence modeling. Iterative rejection sampling further improves intersection metrics, with minimal impact on distributional fidelity (as measured by FID).
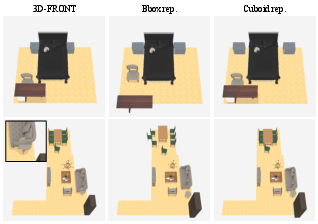
Figure 7: Visual comparison of object arrangement using cuboid vs. bounding box representations for dataset refinement.
Applications: Scene Completion and Re-Arrangement
CasaGPT supports scene completion by auto-regressively predicting missing objects, and scene re-arrangement by resampling low-probability objects. In both tasks, CasaGPT outperforms ATISS in maintaining coherence and avoiding intersections.
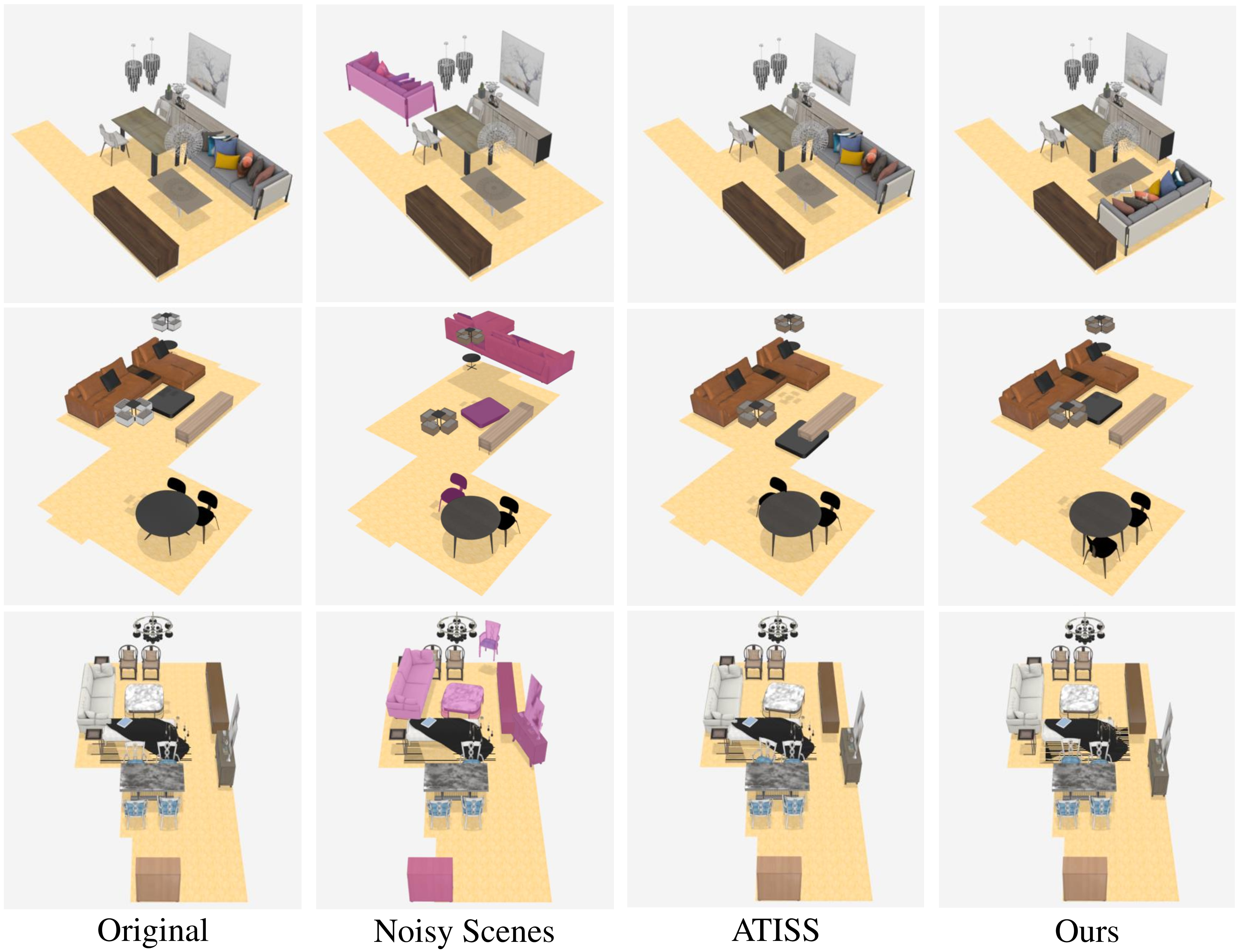
Figure 8: Scene re-arrangement results, with magenta indicating disrupted objects; CasaGPT achieves superior correction and plausibility.
Limitations and Future Directions
Despite substantial improvements, CasaGPT exhibits limitations in highly constrained scenes, occasionally placing objects outside floor boundaries or violating ergonomic principles. Failure cases include inaccessible regions and suboptimal object orientations.
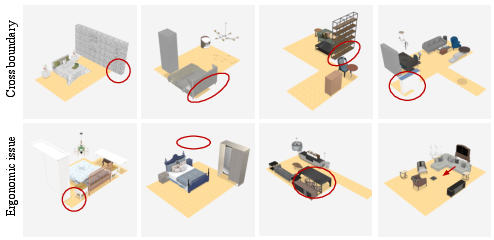
Figure 9: Failure cases including boundary crossing and ergonomic violations.
Future work may explore denoising diffusion models for cuboid generation and reinforcement learning approaches that directly optimize intersection volumes as reward signals.
Computational Considerations
CasaGPT's model size (27.4M parameters) and inference time (29.63ms per forward pass) are competitive, with only modest overhead in object retrieval compared to ATISS and DiffuScene. Training with rejection sampling increases GPU hours but yields substantial gains in scene quality.
Conclusion
CasaGPT advances the state of indoor scene synthesis by introducing a cuboid-based autoregressive framework with integrated rejection sampling and dataset curation. The approach achieves intersection-free, compact, and realistic scene layouts, validated by strong quantitative and qualitative results. The framework sets a new standard for physically plausible scene generation and opens avenues for further research in generative 3D modeling, dataset refinement, and reinforcement learning-based layout optimization.

