- The paper introduces a novel evaluation benchmark (UQ) that tests LLMs on unsolved and naturally challenging questions.
- It employs a three-stage filtering process—rule-based, LLM-based, and human review—to ensure high-quality and diverse problem selection.
- The study reveals a generator-validator gap where models are better at validating answers than generating them, underscoring intrinsic evaluation challenges.
UQ: Assessing LLMs on Unsolved Questions
Introduction and Motivation
The paper introduces a new evaluation paradigm for LLMs by constructing a benchmark, UQ (-0.2em), composed exclusively of unsolved questions—problems for which no known solution exists in public human knowledge bases. This approach is motivated by the saturation of existing benchmarks, which either become trivial for frontier models or are artificially difficult but lack real-world relevance. UQ aims to resolve the tension between difficulty and realism by focusing on open-ended, naturally-arising questions that are both challenging and valuable to solve.
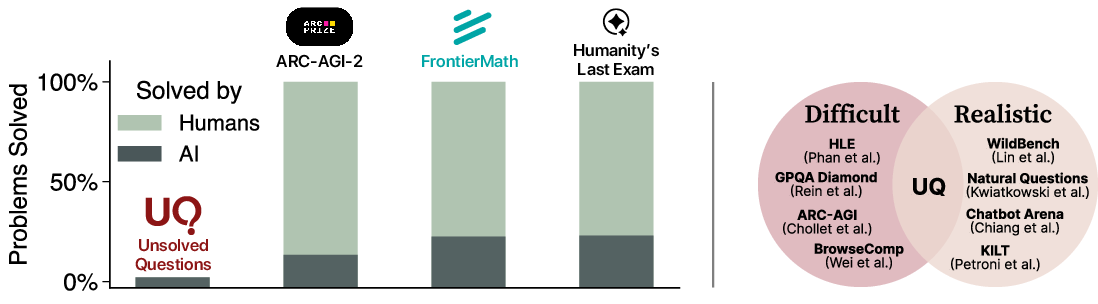
Figure 1: UQ targets hard, open-ended problems not already solved by humans, addressing the difficulty-realism tradeoff in prior benchmarks.
Dataset Construction and Analysis
The UQ dataset comprises 500 unsolved questions curated from over 3 million unanswered posts across 80 Stack Exchange sites. The curation pipeline is a three-stage process:
- Rule-Based Filtering: Heuristic rules select for age, engagement (views, upvotes), and lack of answers, reducing the pool by 99%.
- LLM-Based Filtering: Dual-model LLMs assess well-definedness, difficulty (by both model and expert solvability), approachability, and objectivity. Only questions with low model/expert solvability and high quality are retained.
- Human Review: PhD-level annotators further filter for clarity, difficulty, and domain relevance, resulting in a final set of 500 high-quality, diverse, and challenging questions.
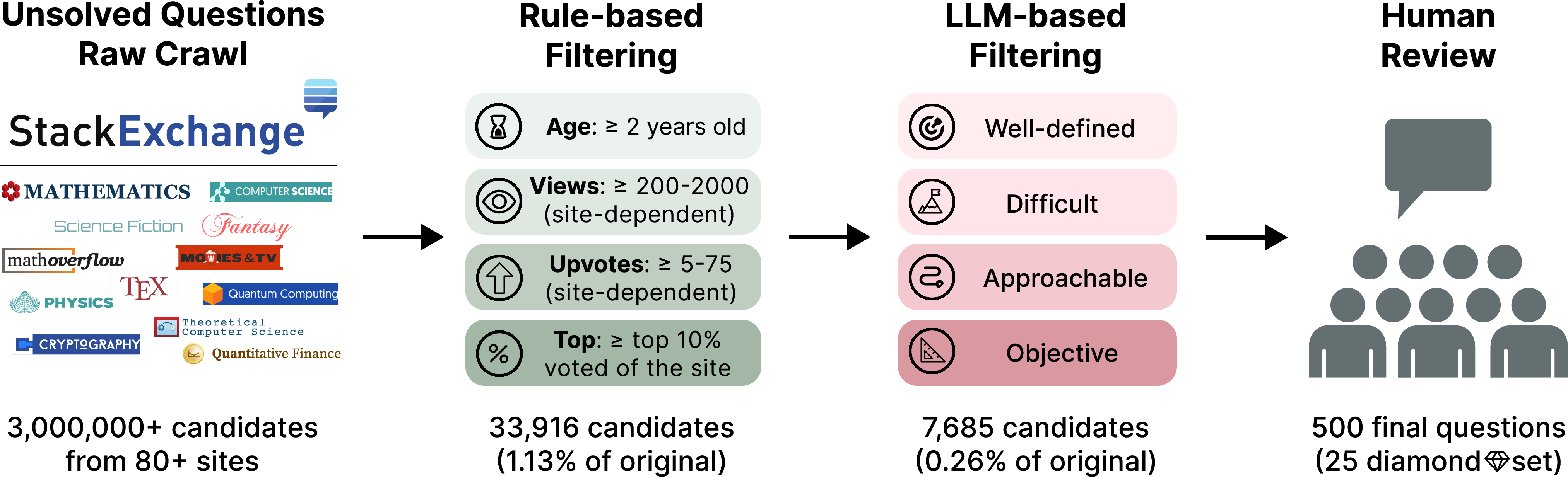
Figure 2: The dataset creation pipeline combines rule-based, LLM, and human filtering to ensure high-quality, unsolved questions.
LLM-based filtering is shown to significantly increase question difficulty and quality, as measured by both model answer correctness and expert solvability estimates.
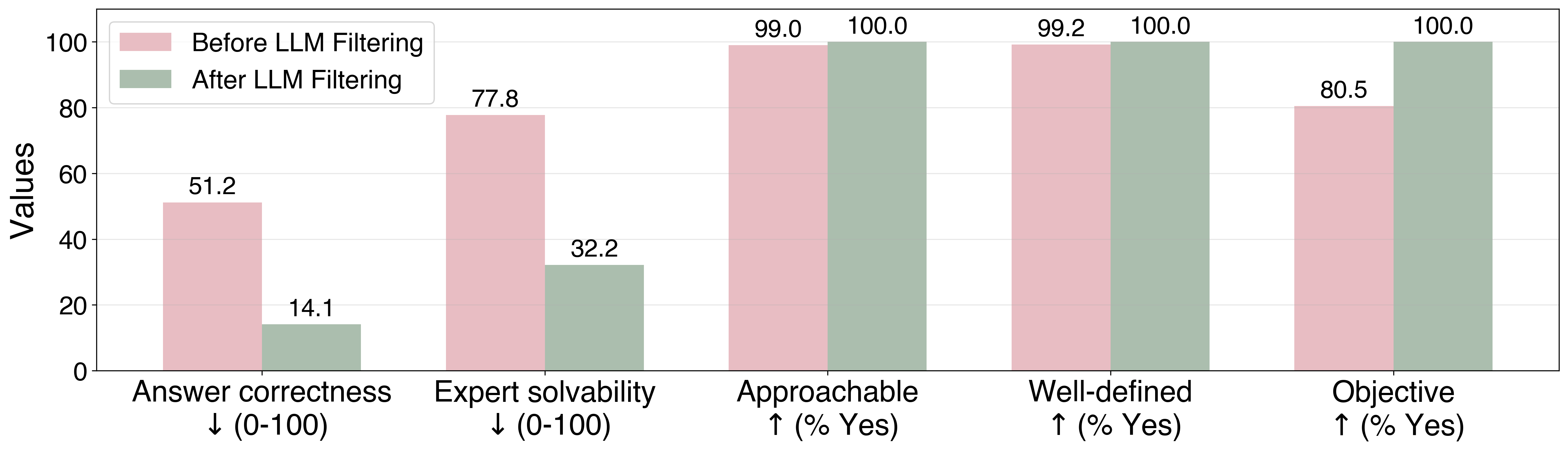
Figure 3: LLM-based filters reduce candidate questions and increase difficulty and quality metrics, saturating quality at 100%.
The dataset spans a wide range of domains, with a majority in science and technology, but also includes history, linguistics, and science fiction.
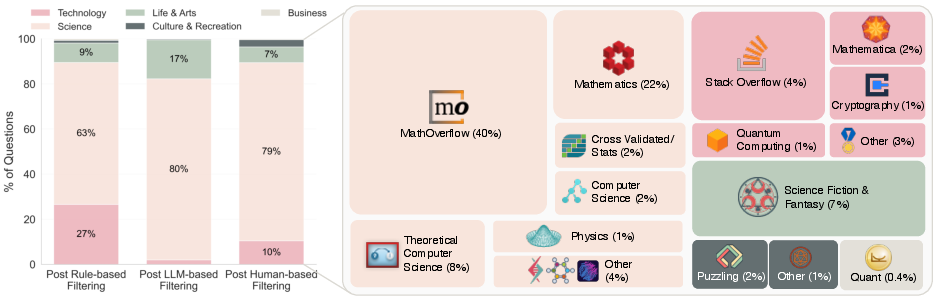
Figure 4: The dataset composition by domain and Stack Exchange site after each filtering stage.
Oracle-Free Validation: Generator-Validator Gap
A central challenge in evaluating answers to unsolved questions is the absence of ground-truth labels. The paper introduces a suite of LLM-based "validators"—strategies for triaging candidate answers without oracles. The key empirical finding is the generator-validator gap: models are substantially better at validating answers than generating them, and this gap widens with model capability.
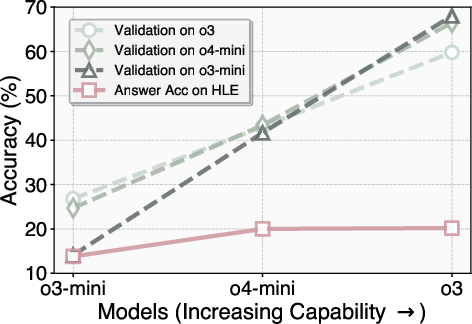
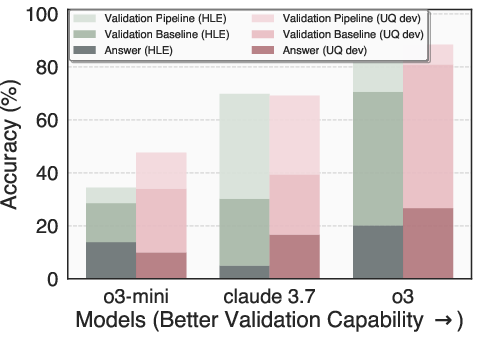
Figure 5: Models' validation accuracy on hard questions grows faster than their answer accuracy, demonstrating the generator-validator gap.
This property is robust and transfers across datasets, supporting the use of surrogate data (e.g., Humanity's Last Exam) for validator development.
Validator Design and Empirical Findings
Validators are constructed hierarchically:
- Low-level: Correctness, fact/logic check, and cycle consistency prompts.
- Mid-level: Repeated sampling and iterated reflection.
- High-level: Majority/unanimous voting and sequential pipeline verification.
The default performant pipeline combines all three levels, using a 3-stage process with unanimous voting and iterative reflection.

Figure 6: The default, performant validator pipeline used in experiments.
Key empirical findings:
- Compound strategies outperform simple baselines: Multi-stage, multi-model, and ensemble validators achieve higher precision and accuracy, though often at the expense of recall.
- High precision is difficult: Even the best validators have limited precision (max 40%), with a sharp tradeoff between precision and recall. Validator strictness is not easily tunable.
- LLMs exhibit self-bias: Simple validators overrate answers from themselves or sibling models, but compound strategies mitigate this bias.
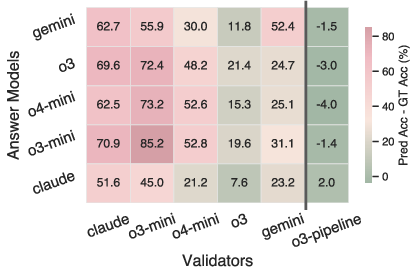
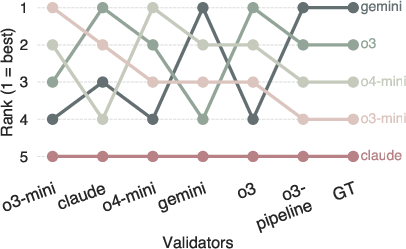
Figure 7: Left—LLM validators overrate self and sibling answers; right—model ranking is unstable across validator performance, with only the strongest validator agreeing with ground truth.
- Model ranking instability: Validator strength significantly affects model rankings, making automated leaderboards unreliable without human verification.
- Better answer generators are not always better validators: Validation and generation capabilities are not perfectly correlated across models.
Scaling and Failure Analysis
Validator performance scales with inference cost: deeper pipelines and model ensembles yield higher accuracy, but with diminishing returns and increased API cost.
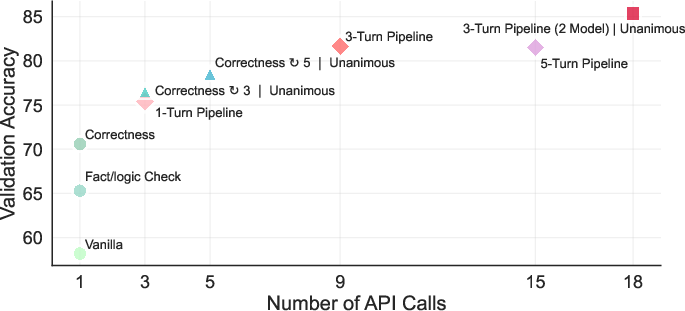
Figure 8: Validation accuracy improves with more API calls and deeper pipelines, but with diminishing returns.
Stronger models are more robust to multi-stage validation, failing less often in early pipeline stages.
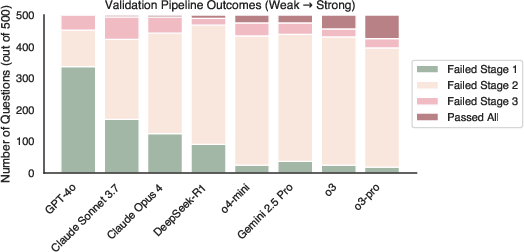
Figure 9: Stronger models pass more validation stages, while weaker models are filtered out early.
The UQ platform (https://uq.stanford.edu) operationalizes the evaluation paradigm by hosting the dataset, candidate model answers, validator results, and human reviews. It supports:
- Browsing and sorting questions by domain, site, and resolution status.
- Submission of new answers and models, with full prompt transparency.
- Human expert reviews and community comments.
- Ongoing, asynchronous evaluation and leaderboard updates as questions are solved.
This design enables continuous, community-driven evaluation, with public attribution and educational incentives for expert participation.
Frontier models achieve low pass rates on the validator pipeline (e.g., o3-pro at 15%, Gemini 2.5 Pro at 5%), and only a small fraction of these are verified as correct by human experts. The majority of candidate answers that pass validation are still incorrect, often due to subtle errors or hallucinated references not caught by validators.
Strong claim: No model achieves more than 4/46 human-verified correct answers on the main set, and none on the diamond subset, highlighting the extreme difficulty of the benchmark.
Implications, Limitations, and Future Directions
Practical implications:
- UQ provides a dynamic, evolving benchmark that remains challenging as models improve, directly measuring progress on real-world, open-ended problems.
- The generator-validator gap enables scalable triage of candidate answers, reducing human verification cost.
- The platform's design supports transparent, reproducible, and community-driven evaluation.
Limitations:
- The dataset is biased toward Stack Exchange domains and may overrepresent STEM topics.
- Validator precision remains limited, and reference verification is weak for domains requiring citation accuracy.
- Early platform engagement may be skewed toward AI researchers rather than domain experts.
Future directions:
- Expanding the dataset to include more diverse sources and higher-difficulty questions.
- Developing more powerful, possibly domain-specific, oracle-free validators.
- Exploring generator-validator interaction and co-training.
- Studying the dynamics of community-based evaluation and incentives.
Conclusion
UQ establishes a new paradigm for LLM evaluation by focusing on unsolved, naturally-arising questions and leveraging oracle-free validation strategies. The benchmark exposes the limitations of current models, provides a scalable path for future evaluation, and offers a foundation for research on model capabilities in domains without ground-truth supervision. As models and validators improve, UQ will continue to evolve, serving as a persistent challenge and a measure of genuine progress in AI.