- The paper demonstrates a fundamental trade-off where models trained for adversarial robustness suffer a significant drop in standard accuracy, as shown by theoretical bounds and empirical metrics (e.g., ≤19% robust accuracy at 99% standard accuracy).
- It formalizes the distinction between robust and non-robust features, revealing that exploiting brittle, non-robust features boosts standard performance but increases vulnerability to adversarial attacks.
- Empirical studies on MNIST, CIFAR-10, and ImageNet confirm that robust training protocols enhance interpretability and semantic alignment at the cost of unperturbed test accuracy.
Robustness-Accuracy Trade-offs in Deep Learning: An Expert Analysis
Introduction
The paper "Robustness May Be at Odds with Accuracy" (1805.12152) presents a rigorous exposition of the inherent conflict between adversarial robustness and standard generalization in supervised learning tasks. It demonstrates, both theoretically and empirically, that models optimized for adversarial robustness often exhibit reduced standard test accuracy, and vice versa. The central claim is that this trade-off persists even with infinite data and is not merely an artifact of finite-sample optimization or current robust training algorithms, but reflects a fundamental property of the data-feature structure and learning objectives.
Theoretical Foundations of the Robustness-Accuracy Trade-off
The authors formalize the learning setting via a stylized data distribution where features differ in their robustness to adversarial perturbations. The core construction divides features into "robust" (highly correlated with the target, resistant to adversarial perturbation) and "non-robust" (weakly correlated with the target, highly sensitive to adversarial attacks) subsets. The analysis demonstrates that optimizing for standard accuracy leads a model to exploit all available signal—including non-robust, brittle features—yielding high accuracy in the absence of adversaries but catastrophic failure under norm-bounded adversarial perturbation.
In the theoretical model, increasing reliance on non-robust features enables standard accuracy to approach 100% as the ambient dimension increases, but renders adversarial accuracy arbitrarily poor. Theorem 1 formalizes this tension: achieving 1−δ standard accuracy bounds adversarial accuracy by 1−ppδ in the presence of an ℓ∞-constrained adversary. Notably, for plausible choices of p (e.g., p=0.95), any classifier with standard accuracy ≥99% is necessarily limited to robust accuracy ≤19%. This result is tight and persists even when the Bayes-optimal classifier is permitted.
Empirical Characterization on Benchmark Vision Tasks
Extensive experiments on MNIST, CIFAR-10, and a restricted ImageNet benchmark support and extend the theoretical analysis. Robust training protocols (e.g., projected gradient descent-based adversarial training) yield models whose standard (unperturbed) accuracy decreases monotonically as the magnitude of adversarial perturbations used in training increases.
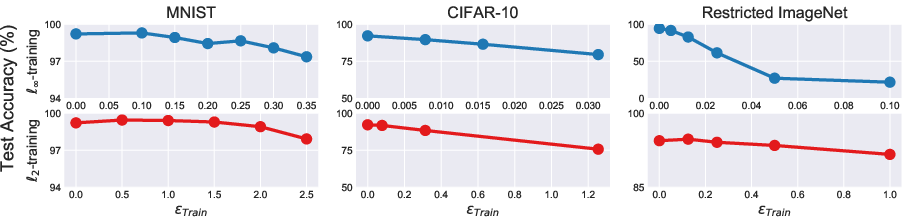
Figure 2: Standard test accuracy of adversarially trained classifiers consistently decreases as the adversarial threat model's ℓp-norm constraint radius increases.
This empirical degradation is robust across varying dataset scales and persists even in the limit of large training data, confirming that the phenomenon is not explained by data scarcity or underfitting.
The analysis of linear classifiers on binary MNIST further confirms the separation of robust and non-robust features at the level of learned model coefficients. Robust models only utilize features with high correlation to the label, whereas standard models exploit any weakly correlated feature, increasing test accuracy but also vulnerability to adversarial attacks.
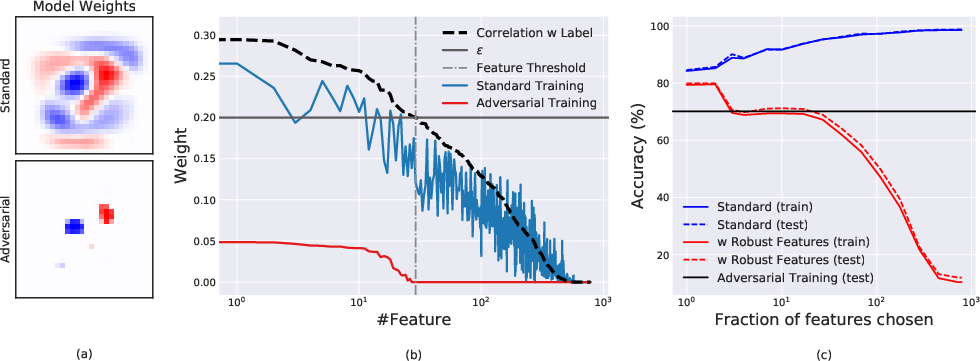
Figure 4: Linear classifier analysis: robust models (red) concentrate weight only on highly correlated pixels, while standard models (blue) spread weight over weakly correlated and noisy pixels.
Mechanistic Explanations: Feature Dependencies and Representation Geometry
A critical insight is that robust and standard models encode fundamentally distinct feature representations. Standard models, by leveraging all "useful" correlations, even if fragile, benefit from maximum separability under the natural data distribution. However, these features are readily flipped by adversarial perturbations. In contrast, adversarially robust models are forced by the training objective to restrict reliance to features exhibiting high signal-to-noise ratios under the chosen perturbation set. This hard thresholding naturally leads to the exclusion of much "useful" but non-robust information, hence the reduction in standard accuracy.
Adversarial examples in robust models are semantics-preserving, often causing perceptually plausible transformations towards the targeted class rather than high-frequency noise.

Figure 6: Interpolation between original image and large-adversarial example in robust models yields smooth, semantically meaningful transitions between classes.
Interpretability and Human Alignment
A non-trivial byproduct of robust training is the alignment between model sensitivities (i.e., input loss gradients) and human perception. The visualizations show that, for adversarially trained models, input gradients highlight semantically salient object structure (edges and class-specific motifs), whereas gradients for standard models appear noisy and uninterpretable.
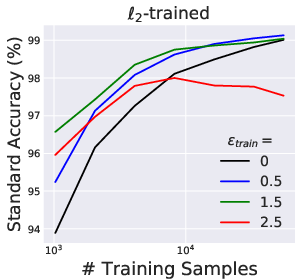
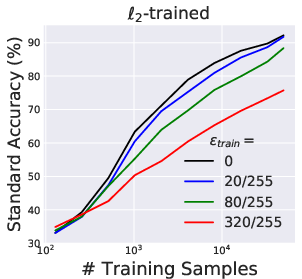
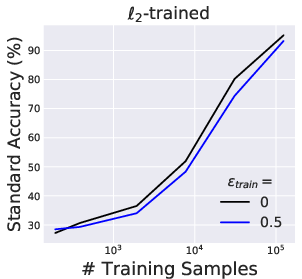
Figure 5: Loss gradients for adversarially trained models are tightly focused on human-perceptible features, facilitating interpretability.
Furthermore, large-norm adversarial examples for robust models resemble valid instances of alternate classes, as opposed to the incoherent, noise-like adversarial examples generated for standard models. Linear interpolations in pixel space between original and adversarial images for robust models yield plausible, perceptually smooth traversals between classes, paralleling effects previously only observed in generative models such as GANs.
Broader Implications and Future Directions
The identification of a fundamental robustness-accuracy trade-off has direct implications for both theoretical analysis and model deployment. It underscores that robustness must be explicit in the learning objective and cannot be trivially achieved by data scaling. The empirical alignment with human perception suggests robust models may offer improved interpretability and could be better suited for safety-critical applications, provided the decrease in standard accuracy is acceptable. It further suggests a possible connection between the geometry of robust classifier boundaries and the latent spaces of generative models, a direction meriting further formal analysis.
Conclusion
"Robustness May Be at Odds with Accuracy" provides compelling theoretical and empirical evidence that adversarial robustness and standard accuracy are in inherent tension for a broad class of classification tasks (1805.12152). This observation calls for recalibration of conventional machine learning wisdom, emphasizing the necessity of explicitly considering the robustness objective, especially in high-stakes or adversarially exposed environments. Additionally, the demonstrated emergent properties, such as enhanced interpretability and semantic alignment of robust models, present fertile avenues for further research, including the design of architectures and training regimes that optimize the joint trade-off envelope, and investigating relationships with generative modeling paradigms.

