- The paper establishes a comprehensive, production-scale framework for measuring AI inference's environmental impact, including energy, emissions, and water use.
- It integrates energy data from AI accelerators, host components, idle capacity, and data center overhead, revealing a 2.4x underestimation in narrow measurements.
- Empirical findings demonstrate a 44x reduction in per-prompt emissions and 33x energy reduction through model, hardware, and software optimizations.
Comprehensive Environmental Impact Assessment of AI Inference at Google Scale
Introduction
The rapid proliferation of large-scale AI systems, particularly LLMs, has shifted the focus of environmental impact analysis from training to inference. As AI products serve billions of prompts globally, quantifying and mitigating the energy, carbon, and water footprint of inference is critical for both operational sustainability and policy development. This paper presents a rigorous, production-scale methodology for measuring the environmental impact of AI inference at Google, with a focus on the Gemini Apps product. The study introduces a comprehensive measurement boundary, empirically quantifies per-prompt energy, emissions, and water consumption, and demonstrates the substantial efficiency gains achieved through full-stack optimizations.
Measurement Boundaries and Methodological Advances
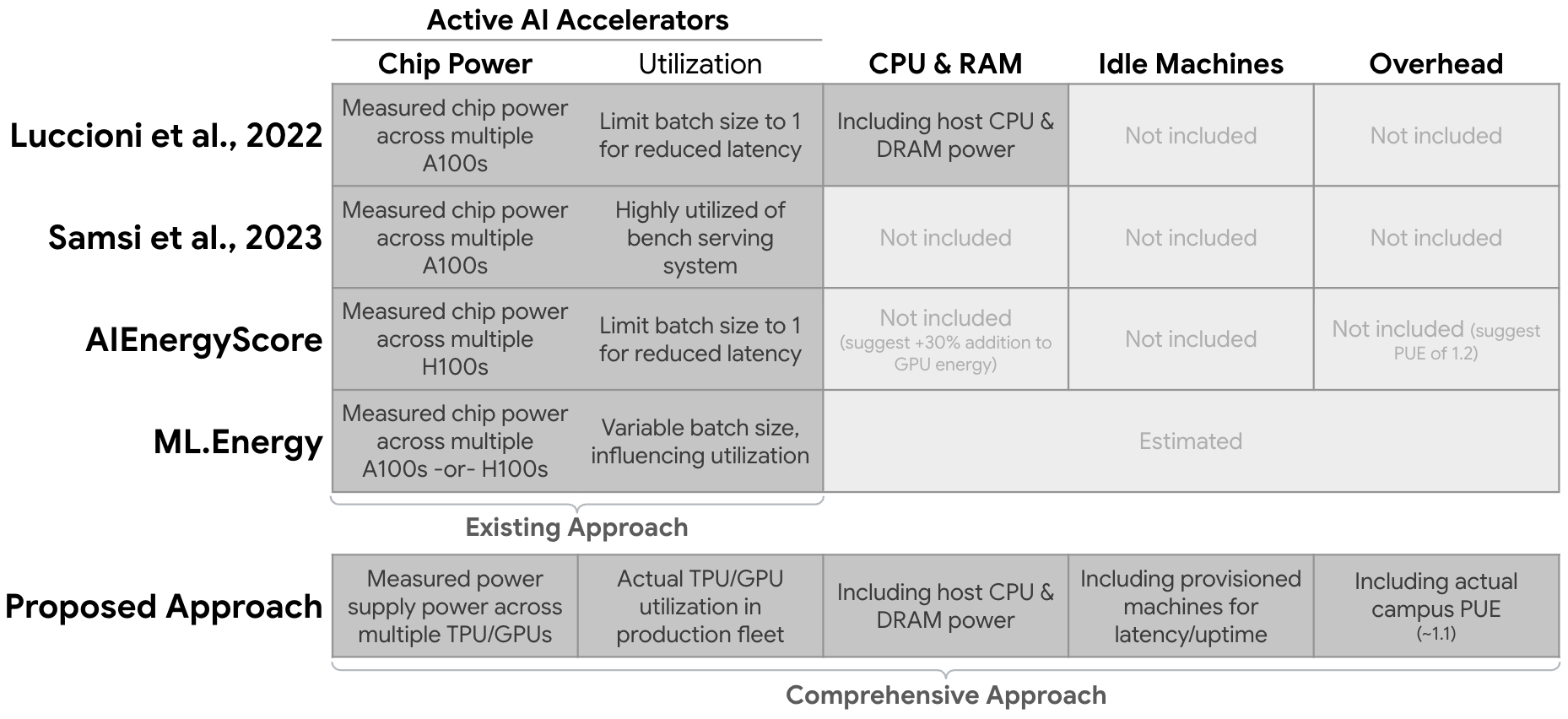
A central contribution of this work is the explicit definition and operationalization of a comprehensive measurement boundary for AI inference energy accounting. Prior studies have typically restricted measurement to the active AI accelerator, omitting host CPU/DRAM, idle capacity, and data center overhead. This narrow focus leads to significant underestimation and poor comparability across studies.
The proposed methodology expands the boundary to include:
This boundary is operationalized through internal telemetry, mapping LLM jobs to machine IDs and collecting PSU-level power data. The methodology also transparently excludes external networking, end-user devices, and training energy, focusing strictly on inference.
Empirical Results: Energy, Emissions, and Water Consumption
Applying the comprehensive methodology to Gemini Apps, the median text prompt in May 2025 consumed 0.24 Wh, generated 0.03 gCO₂e, and used 0.26 mL of water. Notably, the active AI accelerator accounts for only 58% of total energy; host CPU/DRAM, idle capacity, and overhead contribute the remainder.
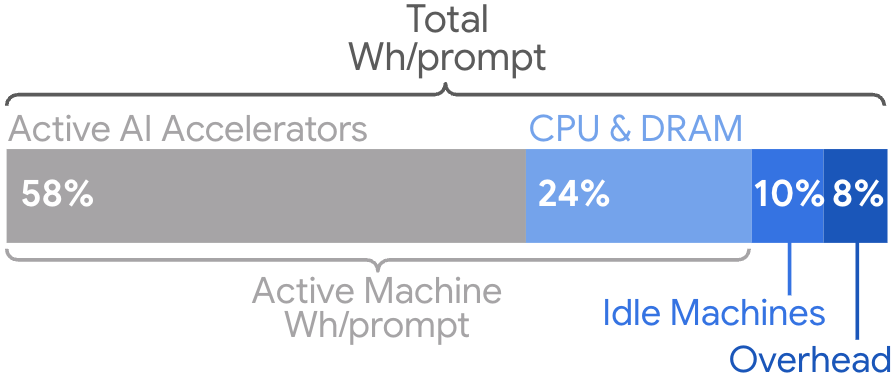
Figure 2: Components of the total LLM energy consumption per prompt across a production LLM serving stack, as measured for Gemini Apps.
Comparison with a narrower, accelerator-only approach yields a 2.4x underestimation (0.10 Wh/prompt), underscoring the necessity of comprehensive measurement for accurate environmental accounting.
When benchmarked against public estimates and measurements for comparable models, the Gemini Apps per-prompt energy is one to two orders of magnitude lower than many prior results. This discrepancy is attributed to three factors: (1) in-situ, production-scale measurement; (2) use of highly optimized, proprietary models and hardware; and (3) efficient batching and utilization in production environments.
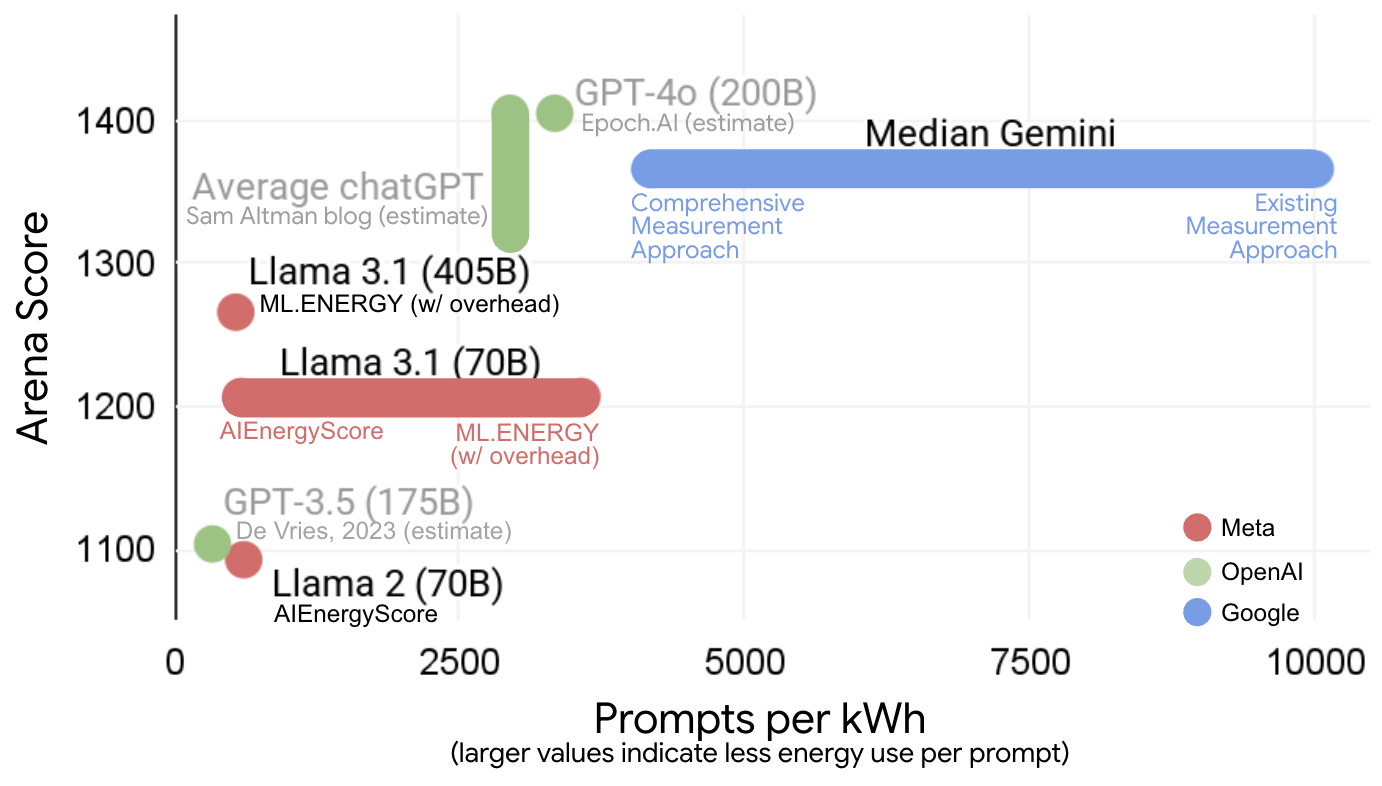
Figure 3: Energy per prompt for large production AI models versus LMArena score, illustrating the impact of measurement boundary and methodology.
Efficiency Gains and Environmental Trends
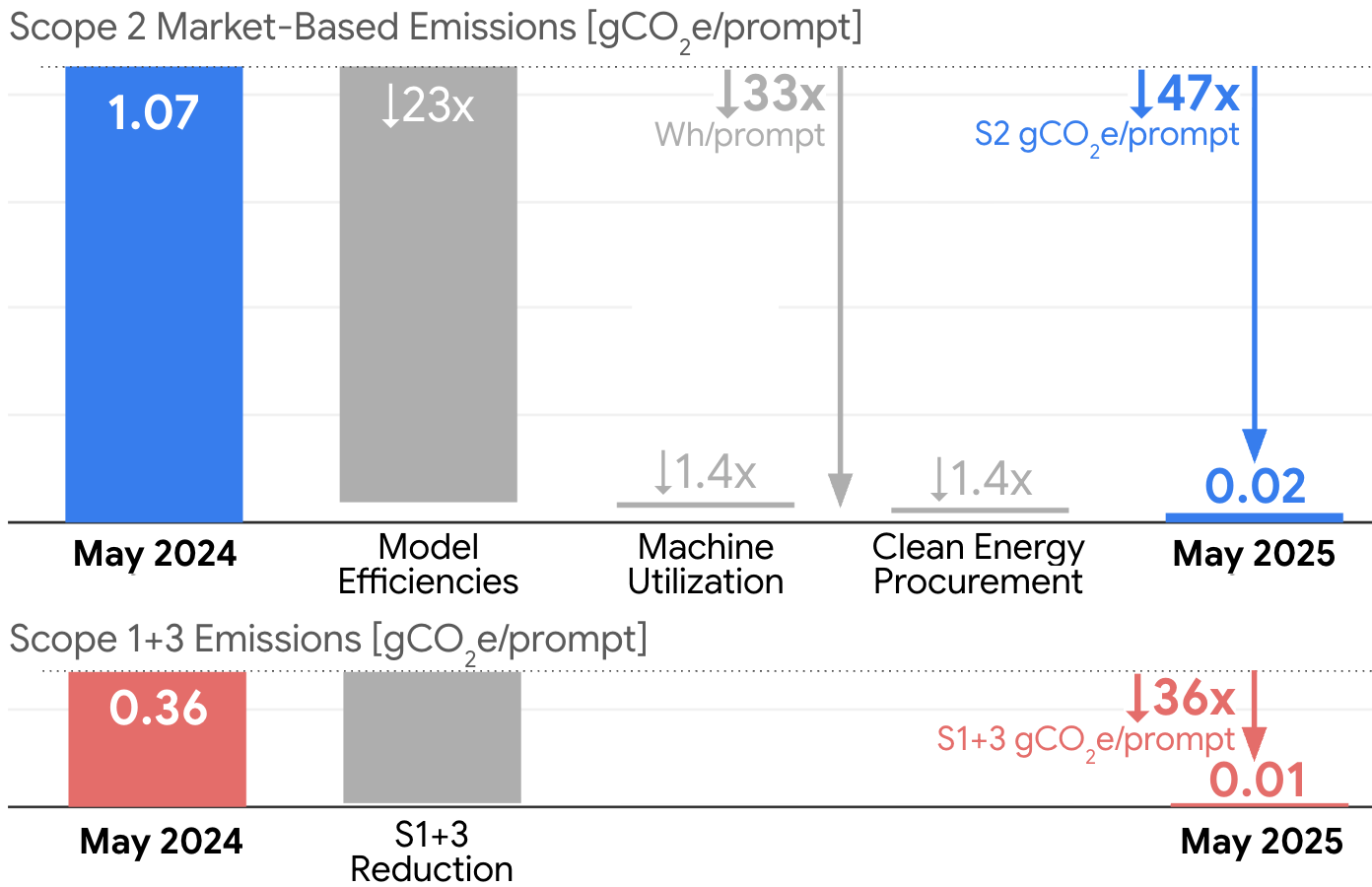
A longitudinal analysis reveals a 44x reduction in per-prompt emissions and a 33x reduction in per-prompt energy for Gemini Apps over a 12-month period. These gains are decomposed into:
Key drivers include architectural advances (e.g., MoE, quantization, speculative decoding), custom hardware (TPUs), optimized software stacks (XLA, Pallas, Pathways), dynamic resource allocation, and aggressive clean energy procurement. The study also highlights Google's water stewardship initiatives, with a trend toward air-cooled data centers in high-stress regions and a fleetwide WUE of 1.15 L/kWh.
Implications and Future Directions
The findings have several important implications:
- Standardization: The order-of-magnitude variability in published per-prompt energy and emissions metrics is primarily due to inconsistent measurement boundaries. Adoption of comprehensive, production-scale methodologies is essential for meaningful cross-model and cross-provider comparisons.
- Optimization Incentives: Full-stack measurement exposes new levers for efficiency, incentivizing optimizations beyond the accelerator (e.g., host utilization, idle management, data center operations).
- Policy and Reporting: Accurate, comprehensive metrics are necessary for regulatory compliance, sustainability reporting, and public transparency.
- Scalability: While per-prompt impacts are low relative to other activities, the aggregate effect at global scale remains significant, justifying continued focus on efficiency and decarbonization.
Future work should extend comprehensive measurement to training, incorporate end-to-end lifecycle analysis, and develop open standards for environmental reporting in AI.
Conclusion
This study establishes a rigorous, production-scale methodology for measuring the environmental impact of AI inference, demonstrating that existing, narrow approaches substantially underestimate true costs. For Gemini Apps, the median prompt's energy, emissions, and water footprint are lower than most public estimates, due to both methodological comprehensiveness and operational efficiency. The demonstrated 44x reduction in per-prompt emissions over one year highlights the potential for rapid, compounding gains when full-stack metrics are used to guide optimization. Widespread adoption of such comprehensive frameworks is critical for ensuring that AI's environmental efficiency keeps pace with its growing capabilities and societal impact.