- The paper presents IPBA, a novel backdoor attack that employs feature disentanglement, dual alignment loss, and sliced Wasserstein regularization to obscure triggers in FSSL.
- It achieves over 93% attack success rate with near-perfect imperceptibility metrics (SSIM ≈ 0.99, PSNR > 33 dB) across multiple image benchmarks.
- IPBA remains effective against conventional defenses, underscoring the need for advanced, context-aware security strategies in federated self-supervised systems.
Imperceptible Perturbation Backdoor Attacks in Federated Self-Supervised Learning
Introduction
Backdoor attacks on federated self-supervised learning (FSSL) present a pressing, under-explored threat vector for decentralized representation learning. While FSSL integrates the benefits of distributed optimization with representation learning from unlabeled data, its intrinsic aggregation protocol exposes it to model poisoning and backdoor vulnerabilities. Existing approaches for backdooring federated and self-supervised paradigms predominantly utilize visually perceptible triggers or rely on supervised attack protocols, both of which are poorly aligned with the operational properties and privacy requirements of FSSL. The work "IPBA: Imperceptible Perturbation Backdoor Attack in Federated Self-Supervised Learning" (2508.08031) addresses this gap, introducing a framework for imperceptible, robust backdoor attacks optimized for FSSL substrates.
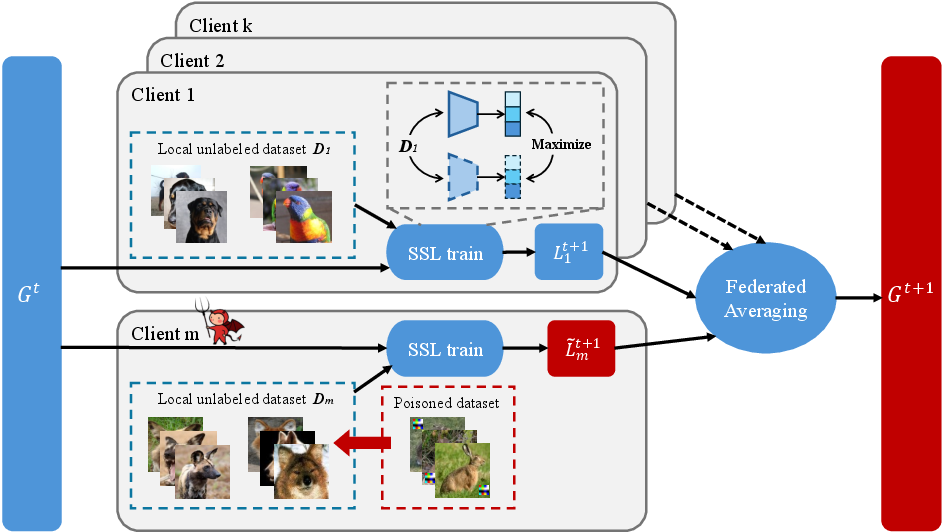
Figure 1: Backdoor injection process in federated self-supervised learning.
Methodological Innovations
The IPBA attack is developed with a deep understanding of the representation entanglement and augmentation mechanisms inherent to SSL under federated constraints. The paper critically observes that prior imperceptible triggers, such as warping- or filter-based perturbations, suffer from limited transferability and display entanglement with augmented samples when naively transplanted to FSSL. Furthermore, they exhibit pronounced out-of-distribution (OOD) properties in representation space, making them detectable and reducing their real-world efficacy.
To overcome these, IPBA introduces several orthogonal innovations:
- Feature Disentanglement: The optimization objective explicitly maximizes the representation gap (in HSV/HSL space) between poisoned (triggered) and augmented samples, discouraging SSL encoders from conflating backdoor cues with standard augmentations. This is realized via the Ldis term.
- Dual Alignment Loss: Attack effectiveness is further increased by aggressively aligning the representations of trigger-injected samples with those of a chosen target class, leveraging cosine similarity in embedding space as the alignment metric (Lalign).
- Sliced Wasserstein Distance (SWD) Regularization: To minimize OOD clustering of backdoor samples, the attack loss penalizes distributional discrepancies (via SWD) between clean and poisoned embeddings, thereby enforcing latent space indistinguishability (Lste).
- Utility Preservation: To avoid global model degradation, an auxiliary utility loss constrains the poisoned model’s representations on clean data to remain close to those of a clean reference encoder.
The poisoned data constructor module is parameterized as a trainable neural injector (U-Net), optimized with respect to a weighted combination of the above losses, producing nearly imperceptible but functionally robust backdoors.

Figure 2: Comparison of clean, backdoored samples created by Patch trigger, Instagram filter trigger, WaNet trigger, IBA trigger, CTRL trigger and ours. The ASR under the BADFSS threat model is shown next to each method name. Residuals are the difference between clean and backdoored images.
Empirical Evaluation
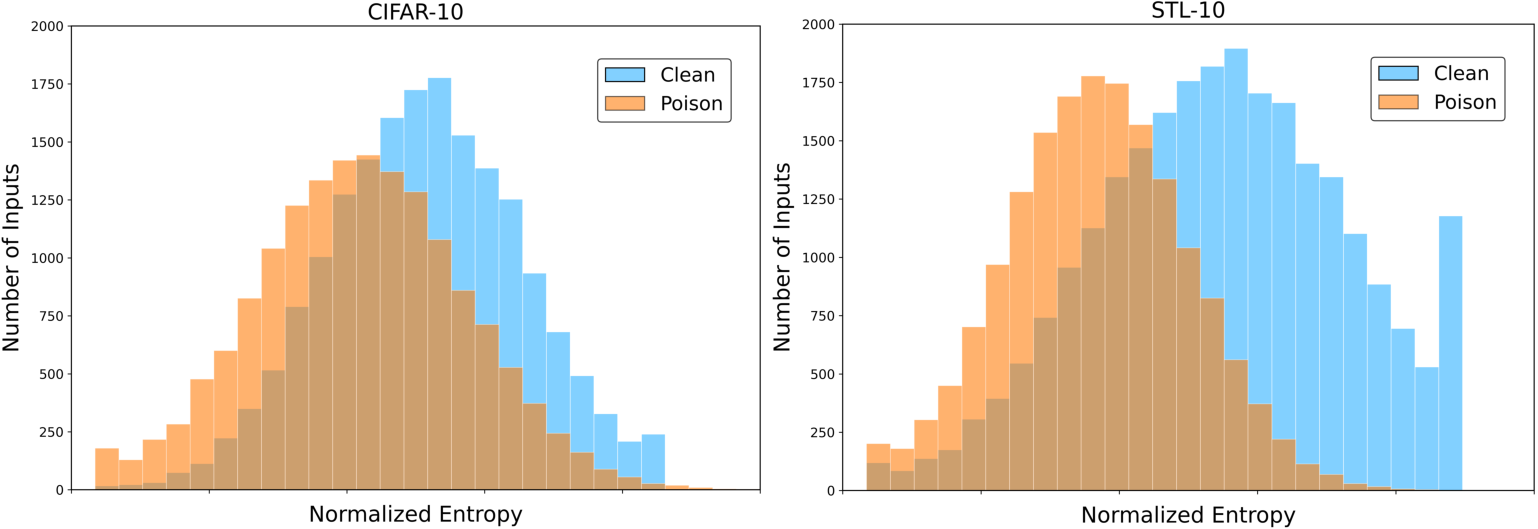
Evaluation is conducted across diverse image recognition benchmarks (CIFAR-10, STL-10, GTSRB, SVHN, Tiny-ImageNet), encompassing multiple SSL algorithms (SimCLR, MoCo, BYOL, SwAV) and encoder architectures (ResNet-18/50, ViT). Attack efficacy is measured via clean accuracy (CA), backdoored accuracy (BA), and attack success rate (ASR). Stealth is assessed by SSIM, PSNR, and LPIPS between poisoned/clean pairs.
Results demonstrate:
- Superiority in ASR and Stealth: IPBA consistently achieves ASR above 93% across distribution shifts, exceeding all existing baselines (WaNet, IBA, CTRL, BADFSS, etc.), with negligible degradation in CA/BA. For example, on the challenging CIFAR-10 → STL-10 setting, IPBA reaches 96.11% ASR, compared to <67% for all baselines.
- Imperceptibility: Triggered samples exhibit SSIM ≈ 0.99, PSNR > 33 dB, and LPIPS ≪ 0.01, confirming visual indistinguishability.
- Robust Generalization: Attack remains functional on non-ResNet architectures and under different SSL algorithms, highlighting strong transferability and model-agnosticity.
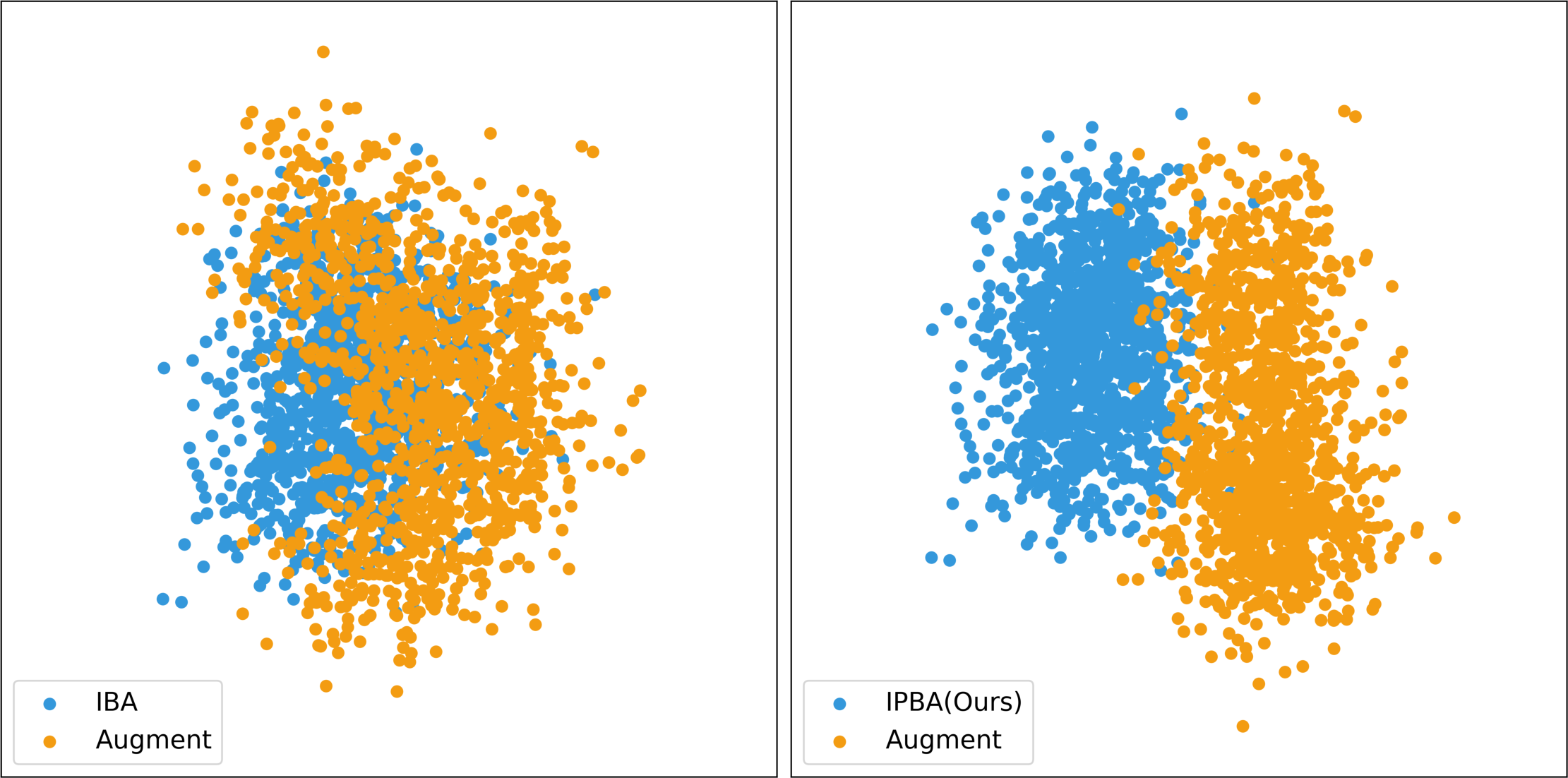
Figure 3: The t-SNE visualization of feature vectors in the latent space under different attacks.
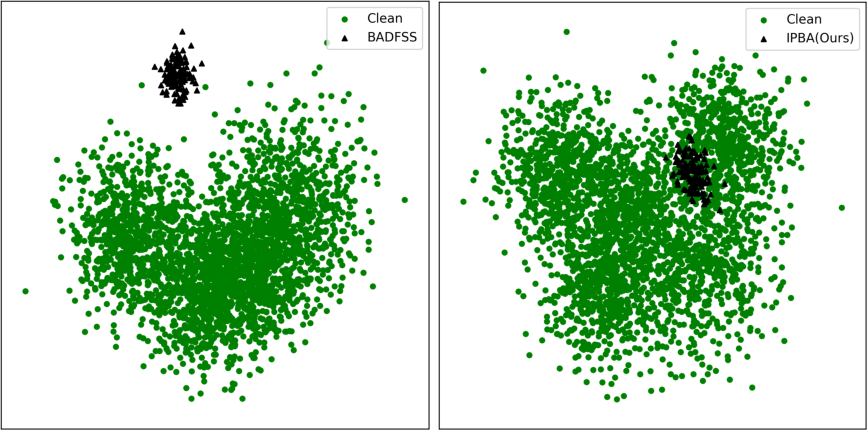
Figure 4: PCA visualization of clean and poisoned sample embeddings in backdoored models under different attacks.
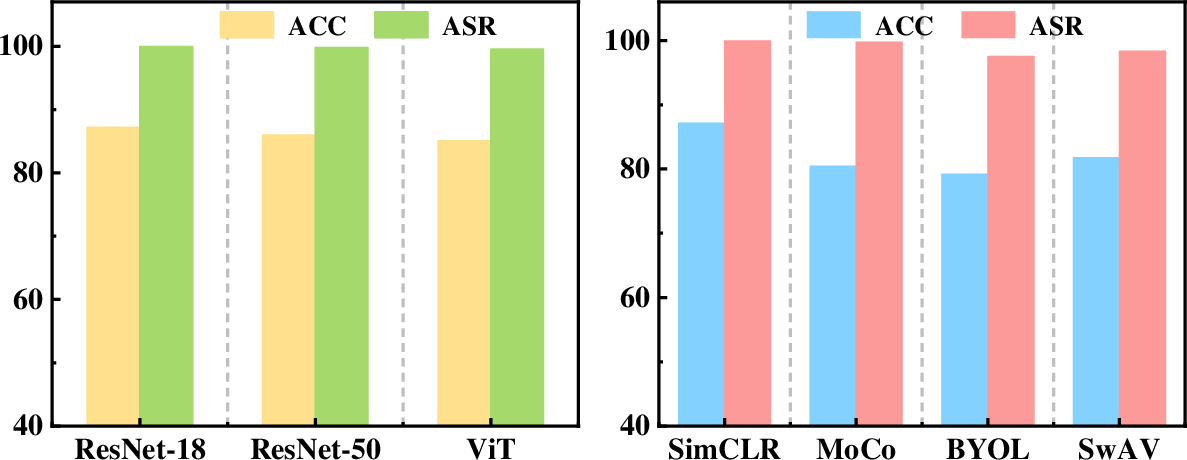
Figure 5: Experimental results for different encoder architectures and SSL algorithms.
Latent Space Analysis
Latent space visualizations (t-SNE, PCA) reveal:
- Prior Imperceptible Attacks: Induce pronounced OOD separation, with poisoned embeddings forming tight, easily identifiable clusters, thus violating stealth assumptions.
- IPBA: Achieves near-complete overlap between poisoned and clean features. Both t-SNE and PCA indicate that poisoned embeddings cannot be distinguished from benign ones, effectively circumventing methods that assume latent cluster separability for detection.
This design directly undermines the "cluster hypothesis" leveraged by prevailing cleansers, making hypothetical defense based on feature space anomaly detection ineffective.
Robustness Against Defenses
IPBA is systematically evaluated against canonical backdoor defense techniques—Neural Cleanse, DECREE, STRIP, GradCAM, Activation Clustering (AC), and federated aggregation-based defense baselines (Krum, Trimmed-Mean, FoolsGold, FLAME, FLARE, EmInspector):
Ablation and Sensitivity Analysis
Ablation studies directly quantify the contributions of disentanglement, alignment, and stealthiness losses:
- Removing Ldis or Lalign induces catastrophic decay in ASR (to 42.32% and 9.68%, respectively).
- Neglecting Lste causes SSIM to collapse to 0.1937 and LPIPS to spike to 0.65, making triggers highly perceptible.
- Model utility is preserved only when all components are active, reflecting robust loss design.
Theoretical Implications and Future Directions
IPBA highlights multiple theoretical and practical consequences for FSSL security:
- Latent Space Stealth: The work challenges the applicability of defense paradigms that depend on OOD or clustering-based outlier detection in high-dimensional SSL embedding spaces.
- Data Augmentation Entanglement: Conventional data augmentations—intended to improve robustness and invariance—can paradoxically impede defense by enhancing backdoor stealth.
- Constraint-aware Attack Construction: The attack’s success under utility-preserving constraints indicates that model convergence and utility guarantees are inadequate as security certifiers in FSSL, motivating the development of novel, representation- or protocol-level defense criteria.
- Transferability: The consistent effectiveness of IPBA across non-IID distributions, infrequent attack intervals, and shifting client populations underscores a nontrivial challenge for future defense research.
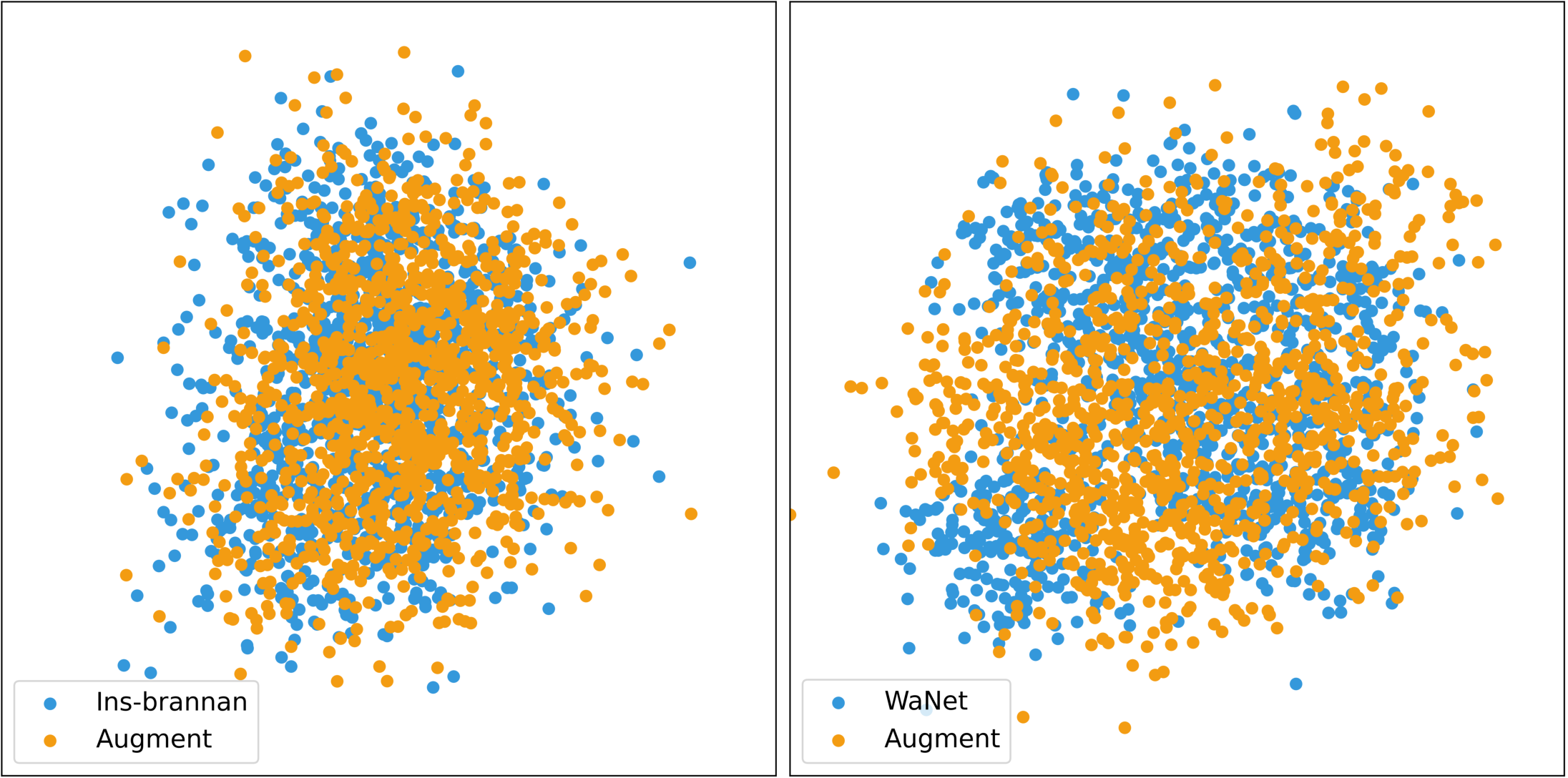
Figure 8: The t-SNE Visualization of feature vectors in the latent space under different attacks.
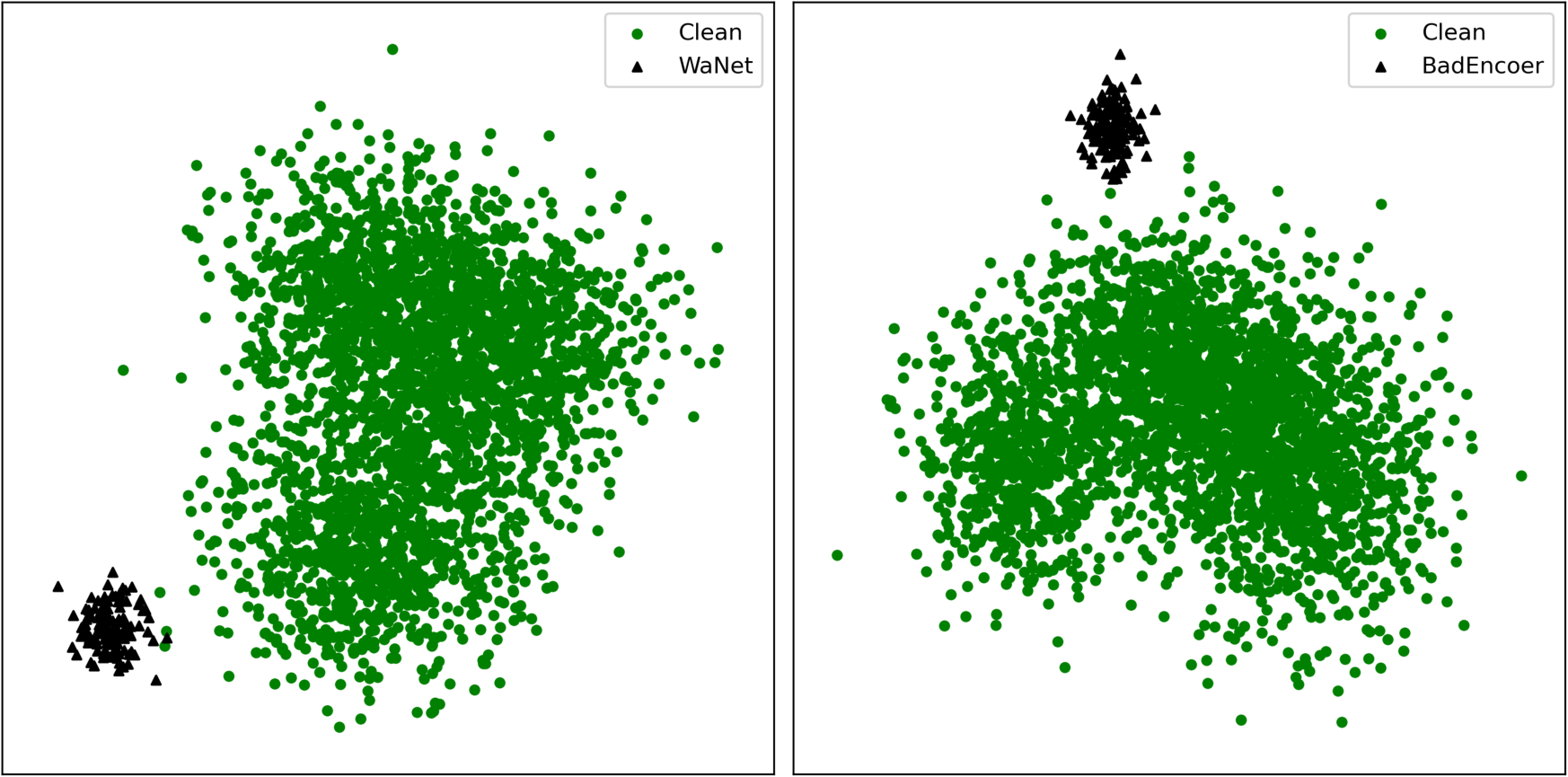
Figure 9: PCA visualization of clean and poisoned sample embeddings in backdoored models under different attacks.
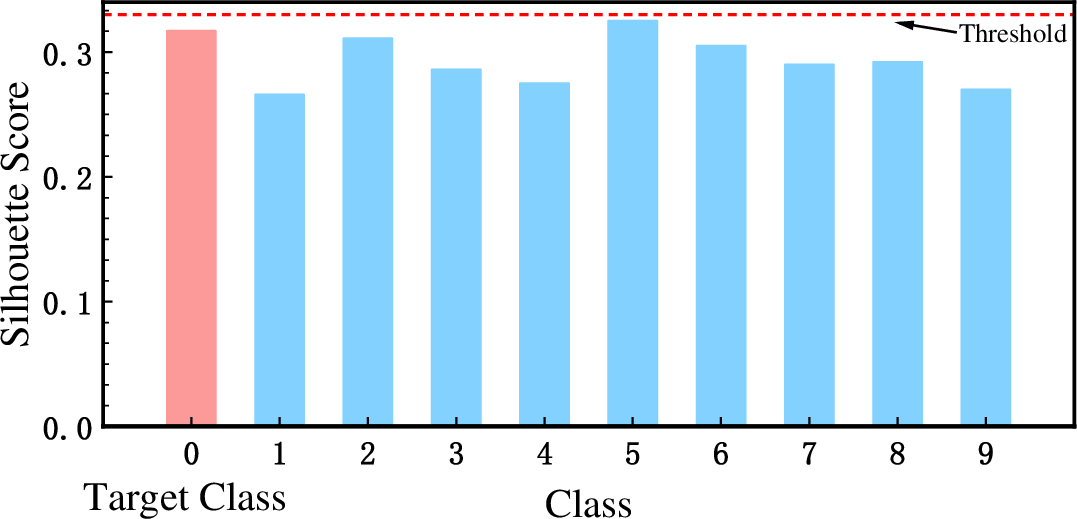
Figure 10: Experimental results of AC.
Conclusion
IPBA establishes a new adversarial baseline for backdoor attacks in federated self-supervised environments, achieving both high attack success rates and unprecedented stealth. By decoupling backdoor triggers from augmentations at the representation level and enforcing distributional indistinguishability, IPBA nullifies the underlying assumptions of existing detection and cleansing strategies. The paper exposes systematic limitations of both prevailing attack and defense techniques within FSSL, highlighting the need for novel, context-aware security analysis and mitigation. The nuanced interplay between augmentations, feature disentanglement, and latent space regularization brought forward by IPBA is likely to guide future exploration in robust federated representation learning.