What One Cannot, Two Can: Two-Layer Transformers Provably Represent Induction Heads on Any-Order Markov Chains
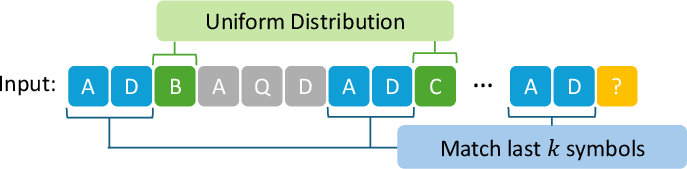
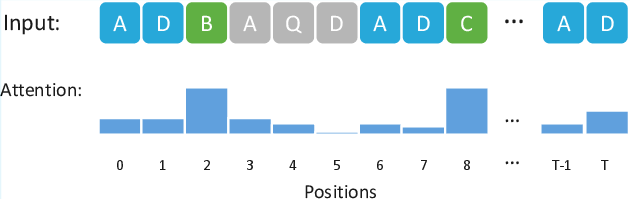
Abstract: In-context learning (ICL) is a hallmark capability of transformers, through which trained models learn to adapt to new tasks by leveraging information from the input context. Prior work has shown that ICL emerges in transformers due to the presence of special circuits called induction heads. Given the equivalence between induction heads and conditional k-grams, a recent line of work modeling sequential inputs as Markov processes has revealed the fundamental impact of model depth on its ICL capabilities: while a two-layer transformer can efficiently represent a conditional 1-gram model, its single-layer counterpart cannot solve the task unless it is exponentially large. However, for higher order Markov sources, the best known constructions require at least three layers (each with a single attention head) - leaving open the question: can a two-layer single-head transformer represent any kth-order Markov process? In this paper, we precisely address this and theoretically show that a two-layer transformer with one head per layer can indeed represent any conditional k-gram. Thus, our result provides the tightest known characterization of the interplay between transformer depth and Markov order for ICL. Building on this, we further analyze the learning dynamics of our two-layer construction, focusing on a simplified variant for first-order Markov chains, illustrating how effective in-context representations emerge during training. Together, these results deepen our current understanding of transformer-based ICL and illustrate how even shallow architectures can surprisingly exhibit strong ICL capabilities on structured sequence modeling tasks.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

