- The paper reveals that induction heads, enabled by self-attention and feed-forward networks, efficiently retrieve tokens to drive in-context learning.
- It demonstrates that multi-head architectures reduce approximation errors by distinctly leveraging first-layer attention and later-stage FFNs.
- The dynamics analysis uncovers a phased learning process—from fast n-gram learning to a plateau and eventual induction head convergence—shedding light on parameter transitions.
Introduction
This essay explores a paper that analyzes the mechanisms through which Transformers implement induction heads, focusing on both approximation and optimization dynamics. Transformers have demonstrated remarkable in-context learning (ICL) capabilities, yet a comprehensive theoretical understanding of these mechanisms remains incomplete. The paper formalizes different types of induction heads and examines how they facilitate ICL in Transformers.
Approximation Analysis of Induction Heads
The approximation analysis centers on how Transformers express induction head mechanisms. Induction heads enable ICL by predicting subsequent tokens based on prior occurrences in the sequence. Three types of induction heads are formalized, varying in complexity:
- Vanilla Induction Head: Defined by simple in-context bi-gram retrieval using a single head without feed-forward networks (FFNs). It retrieves and copies tokens based on dot-product similarity, showing efficient approximation with a two-layer single-head transformer.

Figure 1: An illustrative example of the induction head.
- Generalized Induction Head with In-context n-gram: Leverages a richer context by incorporating multiple tokens. A two-layer multi-head transformer efficiently approximates this mechanism, with approximation error decreasing as the number of heads increases.
- Generalized Induction Head with Generic Similarity: Extends the dot-product similarity to a broader function space. This requires the use of FFNs to approximate the general similarity function, showcasing the importance of multiple transformer components in complex approximation tasks.
The approximation analysis reveals distinct roles for each transformer component: first-layer attention heads extract preceding tokens, while FFNs approximate complex similarity functions.
Dynamics of Learning Induction Heads
The optimization analysis explores the dynamics of learning induction heads in transformers. By examining a mixed target function combining a 4-gram component with a vanilla induction head, a clear learning transition is observed:
- Partial Learning Phase: The model initially learns the 4-gram component faster due to lower complexity, leading to an initial reduction in loss.
- Plateau Phase: Learning of the induction head component stagnates temporarily. This phase is characterized by slow parameter dynamics due to distinct time-scale separations in self-attention mechanisms.
- Emergent Learning Phase: An abrupt transition to learning the induction head occurs, driven by self-attention's parameter dependencies and component proportion differences in the target function.
- Convergence Phase: The model achieves convergence through gradual parameter adjustments, with the 4-gram component fully learned and induction head dynamics resolving over time.
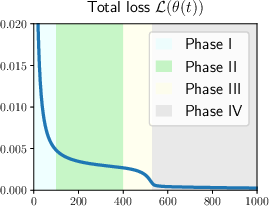
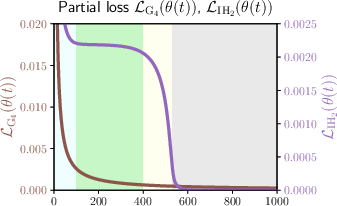
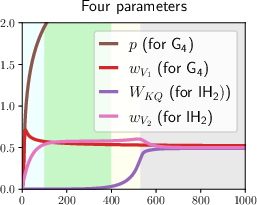
Figure 2: Visualization of the total loss, partial loss, and the parameter dynamics in our setting with α⋆=1,w⋆=0.49,σinit=0.01,L=1000.
The dynamics analysis utilizes Lyapunov functions for convergence characterization, providing a precise description of parameter trajectories and phase transitions.
Conclusion
This paper contributes to our understanding of how Transformers implement induction heads, offering insights into both approximation and optimization dynamics. The approximation results highlight the efficiency of multi-head self-attention and FFNs in complex in-context learning tasks. Meanwhile, the dynamics analysis elucidates the transition from lazy n-gram models to rich induction head mechanisms. These findings shed light on the potential for enhanced in-context learning capabilities in future Transformer architectures. Future research could explore learning dynamics for more generalized induction heads, crucial for advancing in-context learning capabilities.