- The paper introduces DLC, a discrete latent code derived from Simplicial Embeddings that enhances the fidelity and compositionality of image diffusion models.
- It demonstrates that conditioning on DLCs significantly improves unconditional ImageNet generation, achieving a state-of-the-art FID of 1.59 and novel out-of-distribution samples.
- The work also proposes a text-to-image pipeline that leverages pretrained language models to generate DLC tokens, offering a unified approach to image and text generation.
Compositional Discrete Latent Code for High Fidelity, Productive Diffusion Models
This paper introduces Discrete Latent Code (DLC), a novel image representation designed to improve the fidelity, ease of generation, and compositionality of diffusion models. DLCs are derived from Simplicial Embeddings (SEMs) trained with a self-supervised learning objective, resulting in sequences of discrete tokens that offer advantages over standard continuous image embeddings. The paper demonstrates that diffusion models trained with DLCs achieve improved generation fidelity, establish a new state-of-the-art for unconditional image generation on ImageNet, and enable the generation of novel out-of-distribution (OOD) samples through DLC composition. Additionally, the paper showcases a text-to-image generation pipeline leveraging large-scale pretrained LLMs to generate DLCs from text prompts.
Addressing Limitations of Continuous Embeddings
The paper argues that the success of diffusion models is largely attributable to input conditioning. It identifies limitations in current diffusion models, such as low diversity and unrealistic reflections of complex input prompts, as stemming from the inability to fully model the data distribution. The authors posit that conditioning diffusion models on improved representations can alleviate these issues.


Figure 1: Selected samples generated from a DiT-XL/2 with DLC512 for both in-distribution and out-of-distribution (OOD). Model trained on ImageNet 256×256 conditioned on a Discrete Latent Code of $512$ tokens. Left: Samples from unconditional generation. Right: OOD samples of semantic compositional generation by conditioning on diverse compositions of two DLCs corresponding to (1) jellyfish and mushroom, (2) komodor and carbonara and (3) tabby cat and golden retriever.
Natural language is recognized as a flexible and compositional representation, yet text captions often fall short as image descriptors, capturing only a few concepts while excluding crucial details. While text-to-image models have advanced, they often struggle with semantic consistency. Self-supervised learning (SSL) image embeddings offer a structured and expressive alternative, but their continuous nature poses challenges in learning and sampling distributions, as well as in achieving flexible compositionality. DLC aims to bridge the gap between image and text representations by providing a sequence of discrete image tokens that are easy to generate and composable.
Discrete Latent Code (DLC) Methodology
The DLC framework leverages SEMs, which are sequences of distributions over a vocabulary of image tokens learned with an SSL method. The process involves inferring DLCs from SEM encoders trained via a distillation objective. Specifically, an encoded representation eθ(x) is projected onto a V-dimensional simplex using a learnable linear projection Wi, followed by a temperature-scaled softmax στ, resulting in simplicial embeddings Si=στ(eθ(x)⋅Wi). A discrete latent code c is then obtained by taking the argmax of each SEM: Ti=argmaxSi,i∈[L], c=(T1,T2,...,TL) where Ti is a token that takes a value in NV.



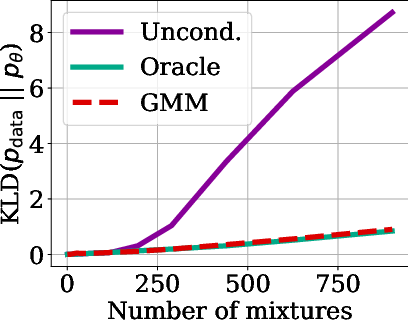
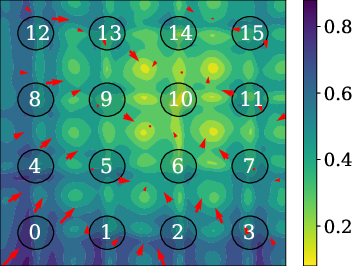
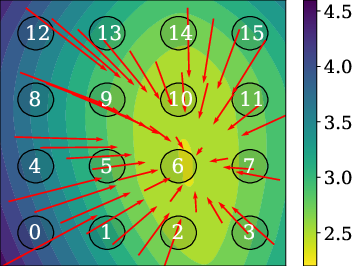
Figure 2: Training: 441 mixtures
To improve unconditional generation, the paper proposes modeling the data distribution p(x) as the product of two generative models that are easier to learn: p(x)=c∑p(x∣c)⋅p(c). Sampling from p(x) is achieved through ancestral sampling, first sampling from p(c) and then sampling the image p(x∣c) conditioned on the sampled code c. To model p(c), the paper employs a discrete diffusion model, SEDD-Absorb, which samples a discrete code by iteratively unmasking a fully masked sequence. The token to be unmasked is determined via a learned concrete score sθ′:C×R→RV which estimates a diffusion matrix that controls the mass transition from the mask token to the DLC token. A remasking strategy is also introduced to improve sampling, where tokens are remasked with a probability η during the reverse diffusion process.
Experimental Results and Analysis
The paper presents a series of experiments to evaluate the performance of DLCs in various image generation tasks. The results demonstrate that diffusion models conditioned on DLCs push the state-of-the-art on unconditional ImageNet generation, outperforming generative models conditioned with continuous SSL embeddings and exhibiting compositional generation capabilities. The experiments also show that increasing the sequence length of DLCs leads to increased image generation fidelity. Specifically, a DiT-XL/2 model with DLC considerably improves the FID compared to the same DiT-XL/2 with label-conditioning, achieving a state-of-the-art FID of 1.59 for unconditional generation. The paper also investigates the trade-off between the sequence length and vocabulary size in DLCs, finding that longer sequence lengths lead to better performance but are more computationally expensive.
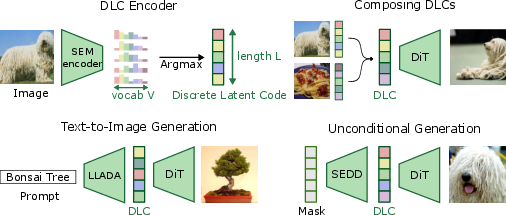
Figure 3: Discrete Latent Codes (DLCs) are Top Left: the output of a finetuned DINOv2 with SEM, followed by an argmax over the vocabulary. Top Right: we can generate semantically compositional images from a composition of two DLCs by selecting tokens from either code. Bottom Left: we enable text-to-image generation by finetuning a text diffusion model for text-to-DLC sampling. Bottom Right: we sample unconditionally by first sampling a DLC with SEDD then conditionally sampling an image with DiT.
In compositional generation experiments, DLC-based compositions successfully integrate visual features from multiple reference images, exhibiting greater sample diversity compared to continuous embeddings. The Vendi Score is used to quantify this diversity, with DLC compositions consistently outperforming continuous embeddings in generating diverse and semantically blended samples.
Finally, the paper explores text-conditioned DLC for image generation, leveraging large-scale pretrained LLMs. By treating DLCs as part of a LLM's vocabulary, the paper proposes a text-to-image generation pipeline that involves sampling a DLC from a text prompt using a LLM, followed by generating an image from the DLC via a pre-trained image diffusion model. This pipeline demonstrates the ability to generate novel images using text prompts OOD relative to the image diffusion model's ImageNet training.
Implications and Future Directions
The research presented in this paper has significant implications for the field of generative modeling, particularly in the context of diffusion models. The introduction of DLC as a compositional discrete representation offers a promising avenue for improving image generation fidelity and enabling productive generation capabilities. The finding that DLC improves on the state-of-the-art for unconditional image generation on ImageNet challenges the conventional wisdom that label or CLIP embeddings are necessary for high-quality results. Furthermore, the paper's demonstration of a novel text-to-image paradigm leveraging large-scale pretrained LLMs opens up new possibilities for unified text-image generation interfaces.
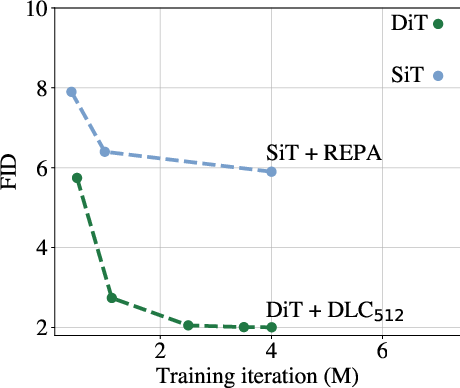
Figure 4: DLC greatly improves training efficiency for FID without CFG on ImageNet. Evaluating FID w/o CFG during intermediate steps, DLC is already improving on vanilla DiT performance at 1/4 of the steps. Baseline numbers taken from~\citet{yu_representation_2025}
Future research directions could explore the application of DLCs to other generative modeling tasks, such as video generation and 3D shape generation. Additionally, investigating methods for learning even more expressive and controllable DLCs could further enhance the capabilities of diffusion models. The development of more efficient algorithms for sampling from discrete diffusion models could also improve the scalability of the DLC framework.
Conclusion
This paper presents a compelling case for the use of Discrete Latent Codes as a means of improving the performance and capabilities of diffusion models. By leveraging a compositional discrete representation learned solely from images, the paper achieves state-of-the-art results on unconditional image generation, enables productive generation capabilities, and introduces a novel text-to-image paradigm. These findings highlight the importance of representation learning in the context of generative modeling and suggest promising avenues for future research.