- The paper demonstrates that unscripted spoken language shows a moderate, statistically significant increase in AI-associated word usage after ChatGPT's release.
- The study utilizes podcast transcripts, employing lemmatization, POS-tagging, and statistical tests to contrast pre-2022 and post-2022 speech patterns.
- Findings reveal the complexity of distinguishing LLM influence from organic language change, with broad implications for model alignment and ethical communication.
Model Misalignment and Language Change: Traces of AI-Associated Language in Unscripted Spoken English
Introduction and Motivation
The paper investigates the extent to which lexical patterns characteristic of LLMs have permeated genuinely human-produced, unscripted spoken English. The central research question is whether the observed post-2022 increase in AI-associated words in written and spoken language reflects mere tool usage (i.e., direct copying of LLM output) or signals a deeper influence on the human language system itself. This distinction is critical for understanding the broader societal and ethical implications of model misalignment, particularly as LLMs are increasingly integrated into communication workflows.
The authors situate their work within the context of rapid, technology-driven language change, drawing parallels to historical shifts induced by the printing press, telephony, and the internet. They note that while sudden spikes in word usage are often linked to real-world events, the recent proliferation of terms such as "delve," "intricate," and "underscore" in academic writing appears to be decoupled from such events and instead correlates with the widespread adoption of LLMs, especially ChatGPT.
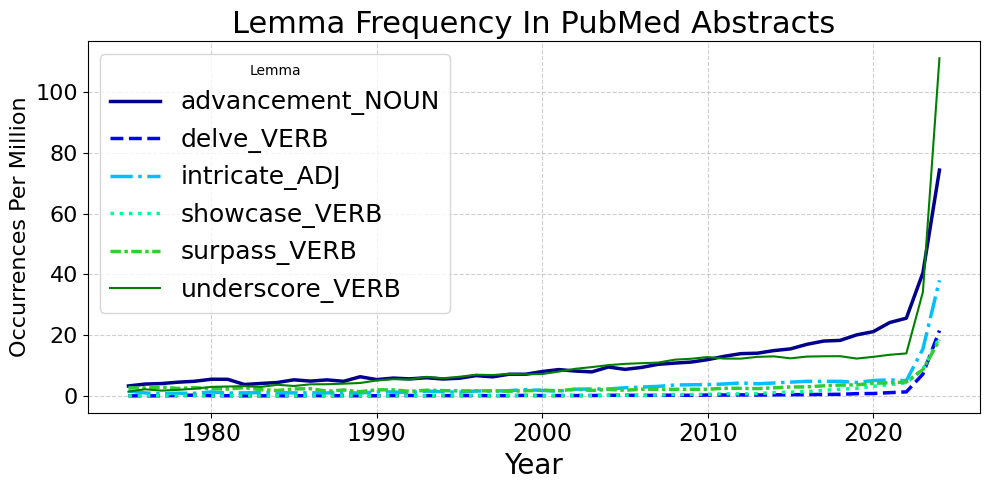
Figure 1: Whether the sharp post-2022 rise in AI-associated words reflects mere tool usage or a direct influence on the human language system remains an open question with broader societal relevance.
Methodology
To address the challenge of human-authorship indeterminacy in written texts, the study focuses on unscripted spoken language from conversational science and technology podcasts. The dataset comprises 22.1 million words, balanced across pre-2022 (2019–2021) and post-2022 (2023–2025) periods, with 1:1 episode ratios per podcast to control for regional and varietal differences. Transcripts were either sourced directly or generated using OpenAI Whisper, followed by lemmatization and POS-tagging via spaCy.
The analysis targets 20 AI-associated words previously identified in the literature as overused by LLMs, comparing their occurrences per million (OPM) before and after ChatGPT's release. Baseline synonym words serve as controls. Statistical inference is performed using weighted log-ratio means and z-tests for group-level effects, with chi-square contingency tests for individual lemmata.
Results
The weighted mean analysis reveals a moderate but statistically significant increase in the usage of AI-associated words post-2022 (weighted log-ratio mean=0.210, z=3.725, p<0.001). Of the 20 target words, 14 show increased usage, with 5 reaching statistical significance ("significant," "align," "strategically," "boast," "surpass"). Conversely, 6 words decrease in frequency, with "crucial" and "realm" showing significant declines. Notably, "delve"—a prototypical LLM-associated term—does not exhibit a significant increase, and "realm" decreases, contradicting expectations based on written language trends.
Baseline synonym words display only a negligible, non-significant overall change (weighted log-ratio mean=0.033, z=1.277, p>0.05), with increases and decreases roughly balanced.
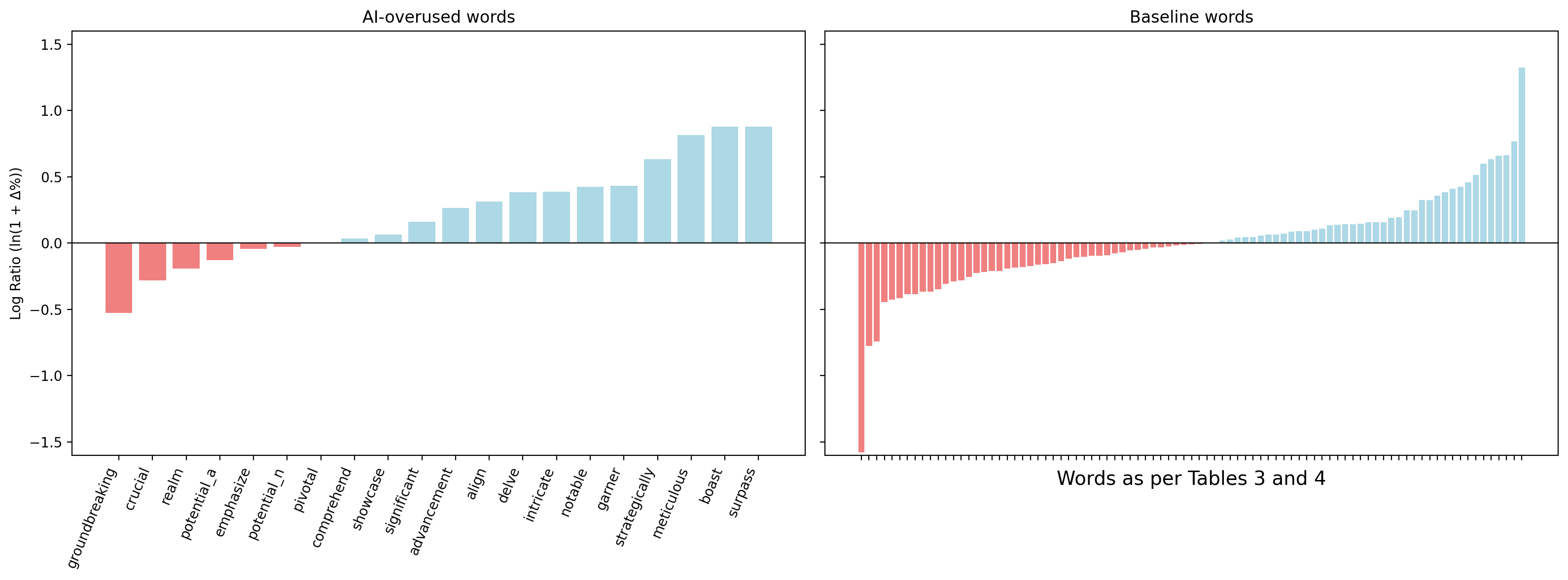
Figure 2: Pre- vs post-2022 logged proportional change for AI-associated words (left) vs baseline words (right).
Discussion
Interpretation of Lexical Shifts
The findings support a rejection of the null hypothesis, indicating a selective convergence of human lexical choices with LLM-associated patterns in unscripted spoken English. However, the magnitude of the effect is moderate, and the directionality is not uniform across all target words. The contrast between sharp spikes in written usage and more subdued changes in spoken language suggests that tool usage may be the primary driver in written domains, while spoken language reflects a slower, more selective adoption.
The lack of significant increase for "delve" and the decrease for "realm" highlight the complexity of attributing causality to LLM influence. The authors caution that many AI-associated words were already trending upward prior to 2022, raising the possibility that LLMs amplify existing language change rather than initiate it. Definitive causal attribution would require longitudinal tracking of individual speakers and their exposure to LLM-generated language.
Implications for Model Alignment and Societal Impact
The observed "seep-in" effect—where repeated exposure to AI-generated language subtly alters human lexical preferences—has direct relevance for model alignment debates. If LLMs encode stylistic or lexical biases not representative of the broader user base, these biases may propagate into human communication norms, raising ethical concerns analogous to those in value alignment, fairness, and bias amplification.
The study also foregrounds the problem of human-authorship indeterminacy, which complicates linguistic research and any scientific field relying on natural language as a proxy for human cognition. As AI-generated content becomes ubiquitous, distinguishing genuine human language production from tool-assisted output will require increasingly sophisticated methodologies.
Limitations and Future Directions
The dataset is restricted to tech- and science-focused podcasts, likely overrepresenting LLM exposure and not generalizable to the broader population. The authors acknowledge the need for larger, more diverse datasets and advocate for qualitative analyses to elucidate micro-level mechanisms underlying observed macro-level trends. The potential for a self-consuming training loop—where human language influenced by LLMs becomes future training data—warrants further investigation, particularly regarding its impact on linguistic diversity and model robustness.
Conclusion
This study provides empirical evidence of a moderate, statistically significant increase in the usage of AI-associated words in unscripted spoken English following the release of ChatGPT. While the results suggest a selective convergence of human language with LLM lexical patterns, the distinction between AI-induced and natural language change remains unresolved. The implications extend beyond linguistics to model alignment, ethics, and the methodology of language research itself. Future work should focus on expanding dataset diversity, refining causal inference, and developing robust frameworks for tracking the evolving interplay between human and machine language systems.