- The paper demonstrates that integrating Semantic IDs with generative models significantly enhances recommendation system performance.
- GRID employs a tokenization-then-generation paradigm with various quantization algorithms and encoder-decoder architectures to enable modular prototyping.
- Practical insights include the removal of user tokens, effective data augmentation, and the benefits of an open-source benchmarking framework.
Generative Recommendation with Semantic IDs: A Practitioner's Handbook
Introduction to Generative Recommendation
Generative recommendation (GR) represents a significant shift in recommendation systems, primarily driven by advancements in generative models. A critical innovation within this domain is the concept of Semantic IDs (SIDs), which facilitate the encoding of semantic information into discrete ID sequences. This approach harmonizes semantic representations derived from LLMs with collaborative filtering signals, thereby retaining the merits of discrete decoding. However, the field suffers from inconsistencies in modeling techniques, hyperparameters, and experimental setups, making direct comparisons challenging. Moreover, the lack of a unified open-source framework impedes systematic benchmarking and model iteration, posing a significant barrier to research and implementation.
Architecture and Framework: GRID
To tackle the aforementioned challenges, this paper introduces GRID—an open-source framework designed for generative recommendation using SIDs. GRID is structured to enable modularity and facilitate rapid prototyping. The framework modularizes all intermediate steps in the generative recommendation workflow, as depicted in Figure 1, which displays the overarching architecture of GRID.
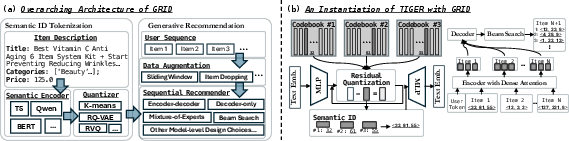
Figure 1: (a) The overarching architecture of GRID. GRID modularizes all intermediate steps in the workflow of GR with SIDs to accelerate the pace of innovation. (b) Instantiating TIGER is straightforward, offering practitioners a reliable reference implementation.
The architecture of GRID follows a tokenization-then-generation paradigm. During tokenization, item embeddings are mapped into SIDs using hierarchical clustering tokenizers. For next-item generation, GRID employs both encoder-decoder and decoder-only architectures to predict the most likely items a user might interact with, given the SID sequences of prior interactions. This flexibility allows for easy component swapping, supporting both standard and custom configurations.
Semantic ID Tokenization
The tokenization process in GRID is designed to be both flexible and robust. Three algorithms are supported for quantization: RK-Means, R-VQ, and RQ-VAE. In practice, RK-Means and R-VQ have been observed to provide superior performance compared to RQ-VAE, which, despite being popular in literature, complicates implementation. Moreover, the choice of semantic encoder size (ranging from Large to XXL in the case of Flan-T5) has a marginal impact on recommendation performance, indicating a need for more effective utilization of larger LLM's world knowledge capabilities.
Generative Modeling Insights
In the context of GRID, generative models benefit significantly from encoder-decoder architectures, which outperform decoder-only models. Encoder-decoder models capture richer sequential patterns due to their capacity to leverage the encoder’s dense attention for contextual understanding. Furthermore, data augmentation, specifically sliding window data augmentation, emerges as crucial for enhancing model robustness and performance.
The framework also addresses practical considerations such as the utility of user tokens. Interestingly, the removal of user tokens, which are typically intended for personalization, results in optimal performance. Additionally, strategies like SID de-duplication and beam search algorithm choice (constrained vs. unconstrained) are examined, with unconstrained beam search shown to be computationally more efficient without compromising recommendation quality.
Conclusion
The GRID framework constitutes a pivotal resource for advancing the field of generative recommendation with SIDs. Through comprehensive experimentation, this study highlights several surprising insights: simpler SID tokenization strategies can outperform complex ones, and specific architectural choices are essential for achieving state-of-the-art performance. The findings underscore the utility of an open-source platform like GRID in inching towards robust benchmarking and expediting research in generative recommendation systems. The paper posits that while current SID pipelines are relatively stable, substantial improvements can be made, especially in leveraging larger LLMs and optimizing architectural components.
The insights gained from GRID’s development and deployment set the stage for further exploration and refinement of generative recommendation strategies, ultimately contributing to more effective and efficient recommendation systems.