- The paper introduces the TIGER framework that uses Semantic IDs generated via RQ-VAE and a T5X-based sequence-to-sequence model for sequential recommendations.
- The paper demonstrates significant improvements in Recall and NDCG metrics across datasets and effectively addresses the cold-start problem with content-derived representations.
- The paper highlights the model’s capability to balance recommendation focus and diversity using temperature-based decoding for broader item suggestions.
Recommender Systems with Generative Retrieval
The paper "Recommender Systems with Generative Retrieval" (2305.05065) introduces a novel approach to recommender systems that employs a generative retrieval model. The authors propose the Transformer Index for GEnerative Recommenders (TIGER) framework, which utilizes Semantic IDs for representing items and trains a model to predict these IDs for sequential recommendation tasks. This essay provides an in-depth examination of the paper's contributions, focusing on the implementation and implications of the proposed method.
Framework Overview
The proposed framework consists of two main stages: (1) the generation of Semantic IDs using content features of items and (2) training a generative retrieval model using these Semantic IDs. The Semantic ID generation involves encoding the item's content using pre-trained text encoders like Sentence-T5, followed by quantization of these embeddings into tuples of semantic codewords via techniques such as Residual-Quantized Variational AutoEncoders (RQ-VAE).
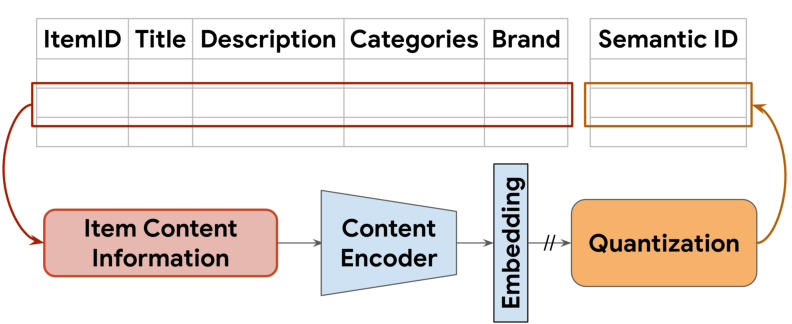
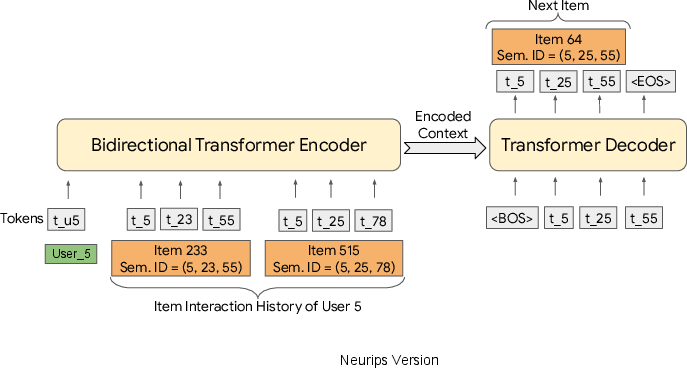
Figure 1: Semantic ID generation for items using quantization of content embeddings.
The generative retrieval model leverages a sequence-to-sequence transformer to predict the Semantic IDs of next items in a user interaction sequence. This approach allows the model to leverage the transformer memory as an end-to-end index for retrieval, thus bypassing the need for separate large-scale indexing often used in traditional recommender systems.
Implementation Details
The RQ-VAE is used to approximate the item's content embedding from a coarse-to-fine granularity, capturing hierarchical relationships between items. For each item, a Semantic ID is generated as a sequence of codewords derived from quantized content embeddings. Using this structured representation, the sequence-to-sequence model is trained on item sequences to predict the Semantic ID of the next item.
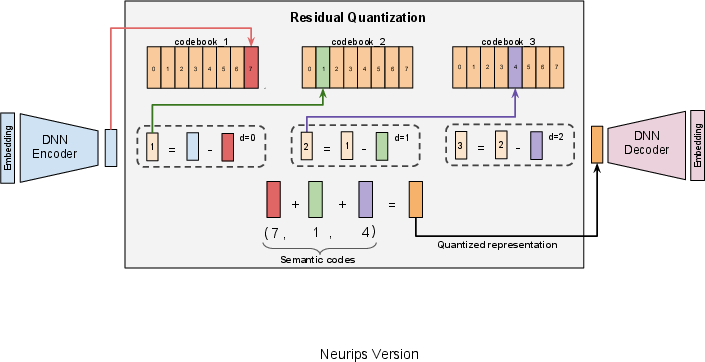
Figure 2: RQ-VAE: In the figure, the vector output by the DNN Encoder, say _0 (represented by the blue bar), is fed to the quantizer, which works iteratively.
The sequence-to-sequence model is implemented using T5X, with a vocabulary that includes tokens for each codeword in the Semantic ID and user ID tokens to personalize recommendations. Training involves constructing sequences of user interactions, augmented with Semantic ID tokens, to predict the subsequent Semantic ID, employing techniques like beam search for generating predictions.
The innovative use of Semantic IDs and generative retrieval in TIGER has shown significant improvements over state-of-the-art baselines in sequential recommendation tasks. The framework displays superior Recall and NDCG metrics across several datasets, such as Beauty, Sports and Outdoors, and Toys and Games.
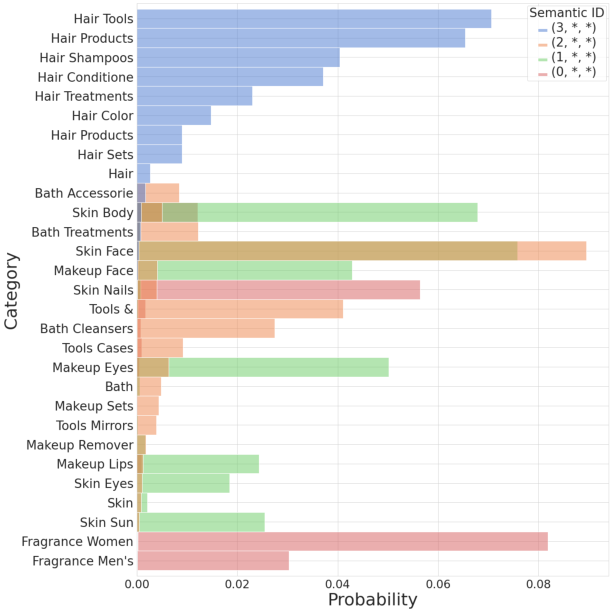
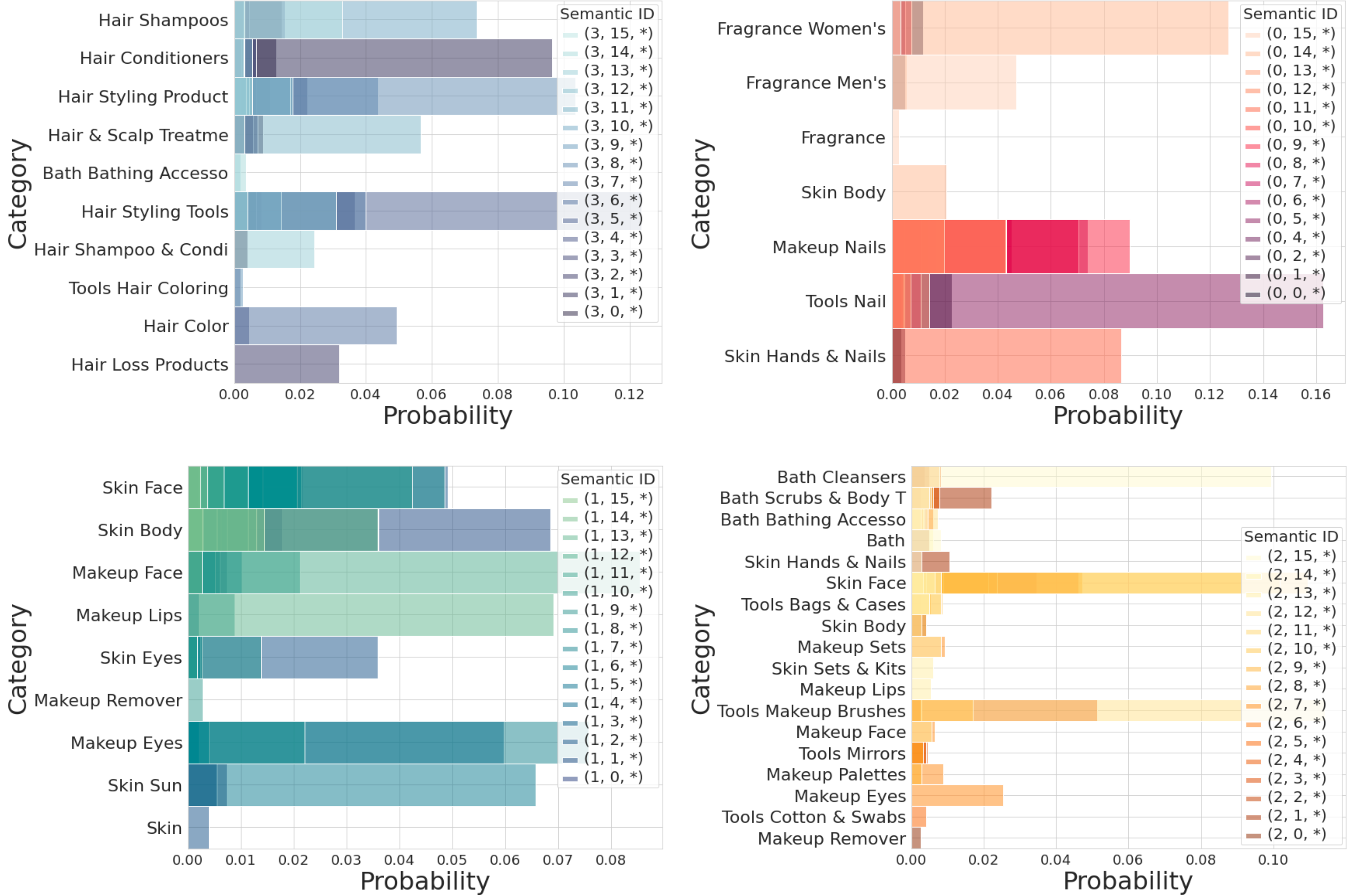
Figure 3: The ground-truth category distribution for all the items in the dataset colored by the value of the first codeword c_1.
An important feature of TIGER is its ability to handle items with no prior interaction history, commonly referred to as the cold-start problem. By using content-derived Semantic IDs, the model can generalize and recommend even newly introduced items, a feature not sufficiently addressed by traditional methods that rely heavily on historical interaction data.
Furthermore, TIGER enables recommendation diversity, allowing users to adjust parameters to receive a broader range of item types within predictions. The model supports this by utilizing temperature-based decoding strategies to balance focus and exploration within item suggestions.
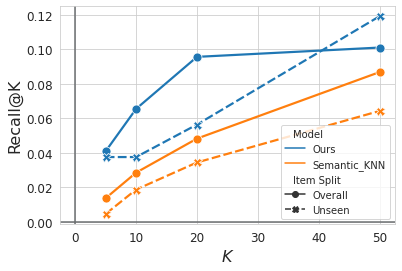
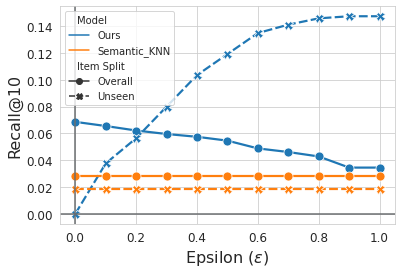
Figure 4: Recall@K vs. K, (ϵ=0.1).
Conclusion
The introduction of generative retrieval techniques to recommender systems via the TIGER framework represents a significant methodological innovation with promising implications for system scalability and flexibility. The implementation details, including semantic embedding quantization and transformer-based sequence-to-sequence modeling, highlight a pathway for overcoming limitations of traditional recommender system practices, notably in handling new items and promoting recommendation diversity. Future research could explore optimizing computational efficiency and further refining the generative retrieval model to enhance applicability across various recommendation domains.