- The paper demonstrates that increasing inference compute through hedged sampling and advanced selection strategies significantly boosts multilingual LLM performance.
- It introduces novel selection methods such as CHOPS and X-MBR that outperform traditional Best-of-N approaches, improving win-rates in diverse tasks.
- Experimental results show that inference-time compute scaling democratizes AI performance across underrepresented languages without necessitating costly retraining.
"When Life Gives You Samples": A Summary of Multilingual LLM Inference Scaling
Introduction
The paper "When Life Gives You Samples: The Benefits of Scaling up Inference Compute for Multilingual LLMs" explores the strategies for enhancing performance of LLMs by scaling inference-time compute rather than the usual method of model retraining or increasing model size. The research focuses on multilingual, multi-task scenarios where inference compute is strategically increased through sampling and selection methods, aiming to improve performance across diverse languages and open-ended tasks.
Inference-Time Compute Strategies
Sampling Strategies
The research distinguishes itself by investigating diverse temperature sampling strategies to create a robust pool of language outputs. Temperature sampling manipulates the diversity and quality of model predictions by adjusting the probability distribution of token predictions. Key insights from Figure 1 reveal significant variance in sample quality across languages and tasks at different temperatures. The study observes that non-English languages tend to experience a higher variance in sample quality at increased temperature settings, necessitating careful strategizing to maintain sample quality.
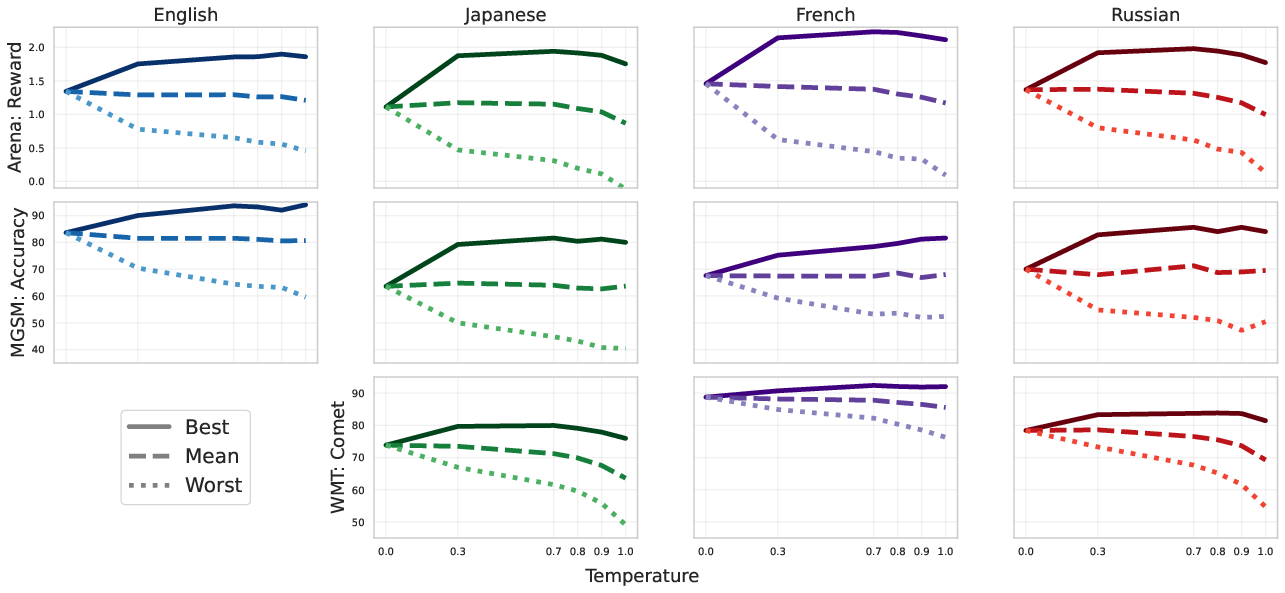
Figure 1: Quality under single temperature sampling for various tasks and languages, illustrating increased variance with higher temperatures.
To mitigate the risks of high variance, the paper introduces hedged sampling, combining stochastic generation with deterministic greedy outputs. This approach provides a safety net, improving average win-rates for multilingual tasks.
Selection Strategies
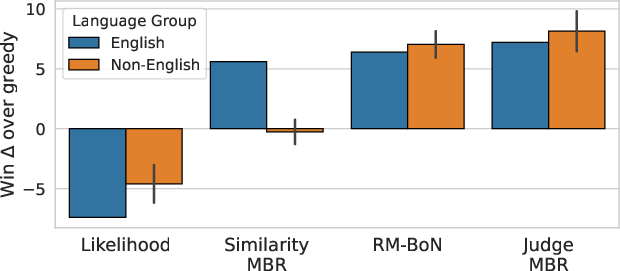
The selection of high-quality samples from the collected pool is critical. The paper contrasts traditional methods like Maximum Likelihood and Best-of-N (BoN) with innovative approaches such as Minimum Bayes Risk (MBR) and proposes novel methods:
Experimental Evaluations
The experiments conducted cover a range of benchmarks including open-ended generation, mathematical reasoning, and machine translation. The results confirm substantial performance gains using the proposed sampling and selection methodologies, under both intrinsic comparison against greedy outputs and extrinsic comparison against more powerful models like Gemini 2.0 Flash.
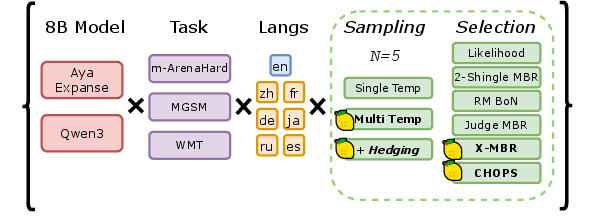
Figure 3: Overview of the multilingual multi-task experimental scope with annotated new methods.
- Hedged Sampling and Min-p Integration: The study's results highlight the effectiveness of integrating token-level truncation (min-p) with hedged sampling, further securing sample quality.
- Cross-Lingual Evidence: By adding cross-lingual samples, X-MBR provides a consistent edge, particularly in non-English language settings, demonstrating the strength of multilingual capabilities in LLMs.
- Practical Implications: The findings advocate for inference-time strategies that significantly democratize AI performance across underrepresented languages, without the need for costly model training.
Conclusion
This research presents valuable strategies for scaling LLM performance at inference time across multilingual tasks. By introducing novel sampling and selection methods such as CHOPS and X-MBR, the study emphasizes efficient compute utilization that leads to robust multilingual generalizations. The implications extend beyond current generative model capabilities, suggesting pathways for future explorations in self-improvement frameworks and broader multilingual applications in AI systems.
The paper encourages continued exploration of inference scaling strategies to further leverage the latent capabilities of multilingual models in diverse and compute-sensitive settings.
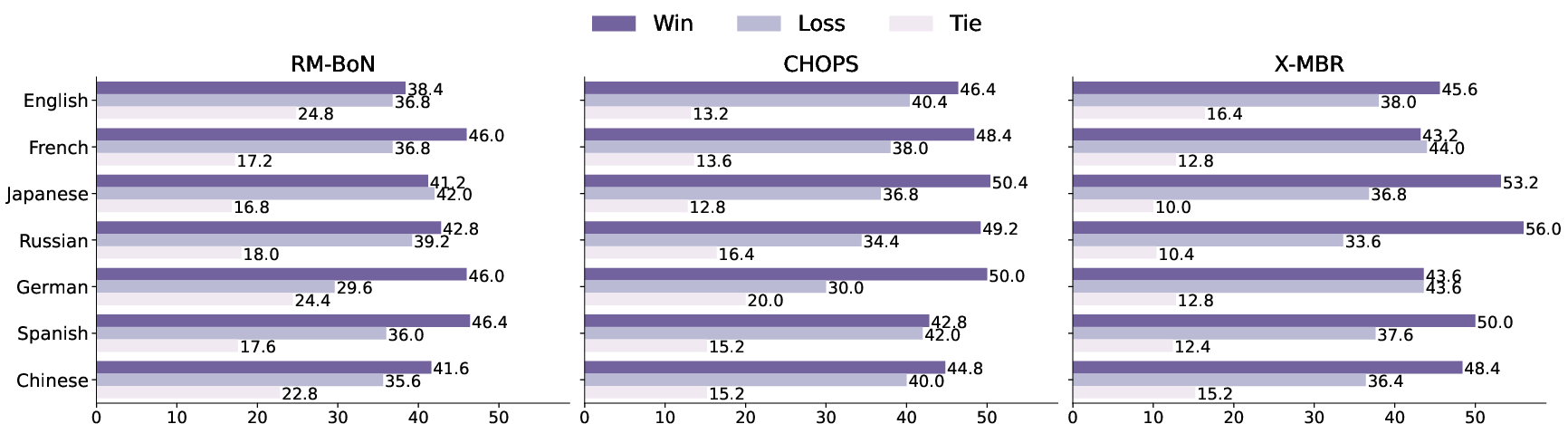
Figure 4: Self-improvement with parallel scaling: Command A win rates showing dominance of proposed methods over baselines.