- The paper presents eLLM, a framework that unifies GPU memory pools to dynamically allocate resources between activation and KV caches, thereby mitigating up to a 20% throughput drop.
- The paper employs a novel eTensor abstraction and OS-level memory ballooning techniques to achieve up to 2.32× higher decoding throughput and support three times larger batch sizes.
- The paper demonstrates that adaptive intra/inter-GPU resource sharing significantly reduces idle memory and TTFT by up to 295×, enabling scalable long-context inference.
Elastic Memory Management for Scalable LLM Serving: An Analysis of eLLM
Motivation and Problem Characterization
Efficient memory management has surfaced as a principal bottleneck in contemporary LLM-serving systems, especially as context lengths and parameter counts reach unprecedented scales. Conventional architectures, such as vLLM, partition GPU memory into isolated pools for static weights, activation tensors, and KV cache. This discrete allocation approach causes severe underutilization, particularly in dynamic workloads, resulting in substantial throughput degradation—quantitatively, up to a 20% drop (Figure 1).
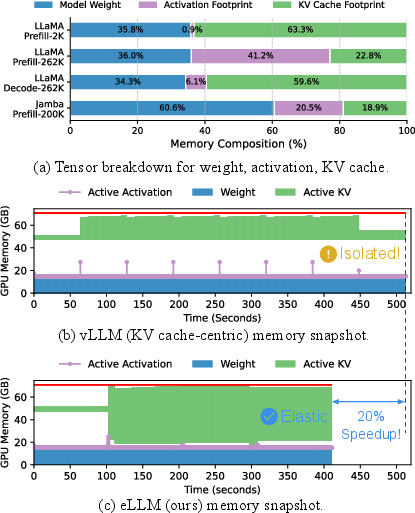
Figure 1: Architectural differences between vLLM and eLLM, where eLLM’s elastic allocation achieves 1.2× speedup via dynamic resource sharing.
Memory composition shifts are further intensified by advancements in LLM architectures and context lengths. As models like LLaMA3 and Jamba-Mini integrate highly compressed KV caches, activation memory increasingly dominates resource profiles (Figure 2). Fragmentation, persistent idle memory, and inability to flexibly repurpose physical memory exacerbate queueing delays and restrict maximum batch sizes, especially during long-context inference.
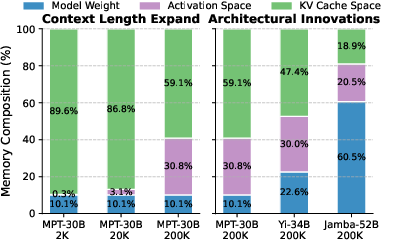
Figure 2: Dynamic fluctuation in memory composition as architectural innovations shift the activation/KV cache ratio for LLM workloads with varying context lengths.
eLLM: Unified Elastic Memory Management
The eLLM framework addresses the limitations of legacy systems by unifying the physical GPU memory pool across activation and KV cache tensors, dynamically allocating resources in response to workload demands. This paradigm is informed by OS-level memory ballooning techniques, enabling logical separation of tensor abstractions while removing physical isolation.
A key innovation is the virtual tensor abstraction (eTensor), which decouples the virtual address space of tensor objects from their underlying physical GPU chunks (Figure 3). For KV cache, eLLM pre-allocates virtual address segments at maximum concurrency and maps physical memory on-demand, whereas activation tensors leverage non-uniform allocations and frequent remapping, strictly aligning virtual segments with physical chunk granularity.
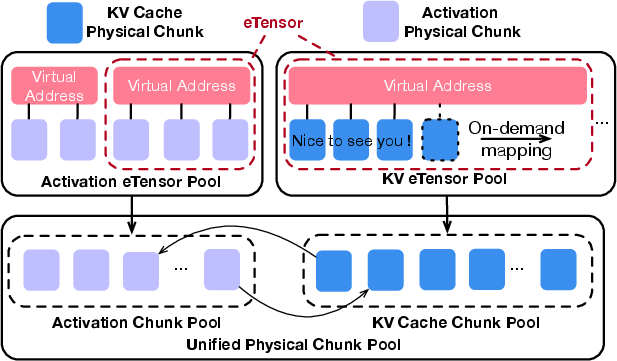
Figure 3: The eTensor abstraction permits identical physical chunks to be transferred between activation and KV cache spaces with zero overhead.
eLLM’s elastic memory mechanism employs intra-GPU inflation/deflation and GPU-CPU memory offloading. Memory inflation opportunistically borrows idle physical chunks from activation pools for KV cache expansion, reclaiming memory via lightweight garbage collection. CPU DRAM is utilized as an elastic buffer for KV caches during memory-intensive prefill stages, effectively reducing TTFT and enabling larger batch sizes without increasing decoding latency. The lightweight scheduling strategy orchestrates both resource transitions and buffer scaling in accordance with SLO constraints, dynamically tuning buffer size and resource assignments (Figure 4).
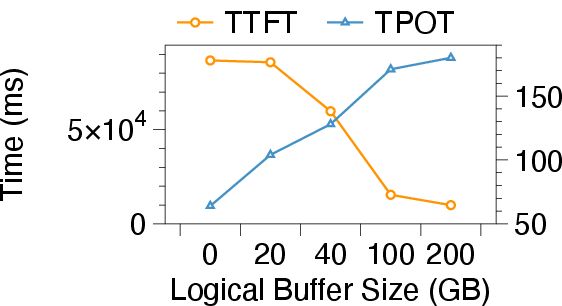
Figure 4: SLO metrics under variable CPU buffer sizes, highlighting the trade-off between TTFT and TPOT for adaptive memory management.
Empirical Results and Numerical Analysis
Comprehensive evaluations illustrate the substantial efficacy of eLLM. When serving LLaMA3-8B-262K on a single A100 (80GB), eLLM achieves up to 2.32× higher decoding throughput and supports batch sizes three times larger than vLLM under 128K-token inputs. TTFT is reduced by up to 295×, and goodput attains 2.5× improvement as queueing delays vanish due to elastic intra/inter-GPU resource allocation (Figure 5).
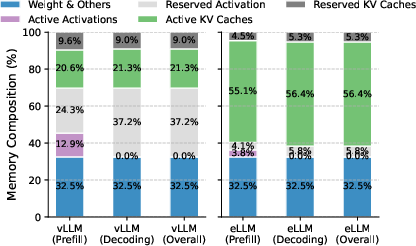
Figure 5: Comparative memory utilization patterns between vLLM and eLLM, substantiating superior dynamic allocation and reduced idle memory in the latter.
Offline inference scenarios further validate eLLM’s scalability: decode throughput and total throughput accelerate by factors of 2.32 and 1.82, respectively, across data distributions with long context. As input sequence lengths increase, vLLM’s throughput plummets due to rigid memory allocation, while eLLM maintains robust batch sizes and decoding rates (Figure 6).
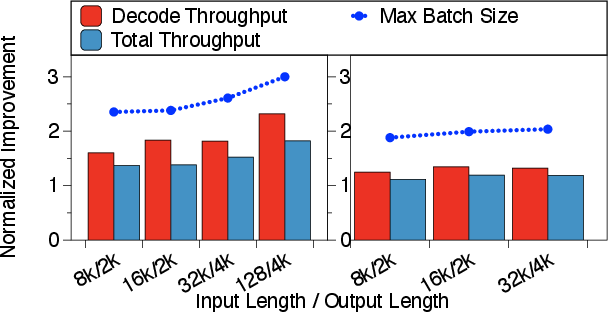
Figure 6: Throughput metrics for Jamba-Mini and Llama3-8B-262K as input/output sizes vary, demonstrating eLLM’s efficiency in batch scaling and memory allocation.
Ablation studies confirm the effectiveness of both intra-GPU and inter-GPU elasticity features; their combination is essential to maximize goodput and throughput without compromising SLO compliance.
Practical and Theoretical Implications
eLLM’s unified elastic memory paradigm enables practical deployment of LLMs with extreme context lengths and heterogeneous workloads on commodity GPUs. The approach obviates static pre-allocation, mitigates fragmentation, and permits adaptive resource sharing—critical as models exhibit greater architectural variability and inference demand scales. Practically, this can reduce infrastructure costs, improve real-time serving latency, and unlock deployment scenarios constrained by legacy memory architectures.
Theoretically, eLLM’s abstraction harmonizes tensor management across activation/KV/parameter spaces, laying groundwork for future memory management schemes that treat parameters as dynamic entities. This evolution aligns with trends in model adaptation, continual learning, and modular architectures where parameter updates occur during serving, requiring dynamic memory reallocation.
Future Outlook
The eLLM design is orthogonal to attention optimization, quantization, and compression techniques. Its abstraction can accommodate further memory-bound innovations—including parameter dynamism, orchestrated multi-GPU paging, and hybrid in-memory/network offloading. Extensions of eLLM will likely be necessary as LLMs reach multi-billion context lengths or integrate continuous learning strategies. The elastic memory orchestration—accompanied by SLO-aware scheduling—paves the way for efficient, responsive, and adaptive AI-serving infrastructure.
Conclusion
The eLLM framework establishes a robust elastic memory management paradigm for modern LLM serving, achieving substantial gains in throughput, batch scalability, and latency reduction by unifying and dynamically orchestrating GPU memory pools. Its architectural flexibility and empirical efficacy mark it as a potent direction for future AI infrastructure, poised to handle the increasing dynamism and heterogeneity of LLM workloads (2506.15155).

