- The paper presents VPD, a framework that leverages a pre-trained text-to-image diffusion model to guide visual perception tasks.
- The methodology uses cross-attention maps and textual prompts to align and refine semantic guidance for downstream tasks.
- Experimental results show VPD outperforms state-of-the-art approaches, achieving benchmarks like 0.254 RMSE on NYUv2 and 73.3% oIoU on RefCOCO-val.
Unleashing Text-to-Image Diffusion Models for Visual Perception
Introduction to VPD Framework
The paper, "Unleashing Text-to-Image Diffusion Models for Visual Perception" (2303.02153), introduces a novel framework named Visual Perception with a pre-trained Diffusion model (VPD). This framework seeks to exploit the powerful generative capabilities of text-to-image diffusion models, specifically leveraging the semantic information encoded during the vision-language pre-training. Unlike traditional generative models focusing on low-level image attributes, text-to-image models encapsulate a richer semantic understanding due to the conditional synthesis on large-scale datasets like LAION-5B. By using a pre-trained diffusion model as a backbone, VPD aims to transfer high-level knowledge efficiently to various visual perception tasks.
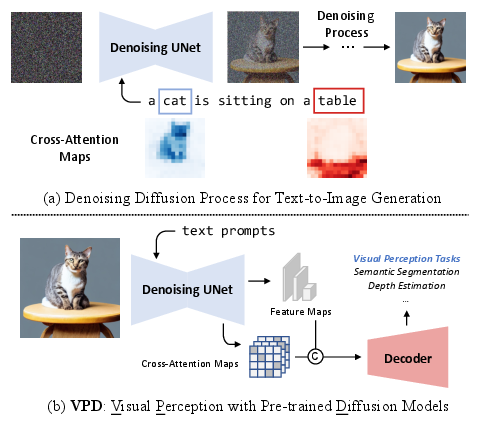
Figure 1: The main idea of the proposed VPD framework. Motivated by the compelling generative semantic of a text-to-image diffusion model, we proposed a new framework named VPD to exploit the pre-trained knowledge in the denoising UNet to provide semantic guidance for downstream visual perception tasks.
Methodology: Semantic Guidance through Diffusion Models
The methodology centers around using the denoising UNet of a pre-trained text-to-image diffusion model to prompt visual tasks. VPD employs textual prompts to align text features with visual inputs, refining these text features with an adapter to improve alignment with the pre-trained text-to-image model. Furthermore, VPD utilizes cross-attention maps between visual and text features to provide explicit semantic guidance, reinforcing both implicit and explicit strategies for knowledge extraction.
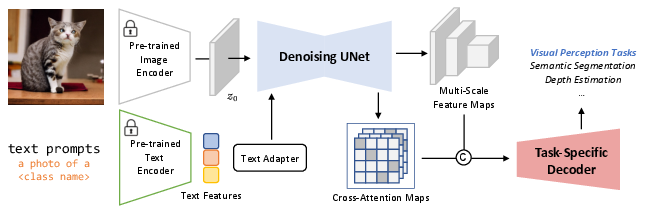
Figure 2: The overall framework of VPD. To better exploit the semantic knowledge learned from text-to-image generation pre-training, we prompt the denoising UNet with properly designed text prompts and employ the cross-attention maps to provide both implicit and explicit guidance to downstream visual perception tasks. Our framework can fully leverage both the low-level and high-level pre-trained knowledge and can be applied in a variety of visual perception tasks.
Experimental Evaluation and Results
The VPD framework was evaluated on multiple visual perception tasks, including semantic segmentation, referring image segmentation, and depth estimation. The results demonstrate that VPD outperforms existing state-of-the-art methods across these tasks, especially when leveraging its ability to quickly adapt to downstream tasks. For instance, VPD set new benchmarks with 0.254 RMSE on NYUv2 depth estimation and 73.3% oIoU on RefCOCO-val referring image segmentation. Notably, VPD also excelled in semantic segmentation on ADE20K, achieving superior results with fewer training iterations. This indicates the potential for diffusion models to accelerate convergence while maintaining performance.
Analysis of Pre-training and Cross-Attention Impact
An in-depth analysis revealed that the performance of VPD scales positively with longer pre-training cycles of the text-to-image diffusion models. This suggests that stronger alignment and richer semantic understanding accrue with extended pre-training, which can be crucial for enhancing downstream task performance. Cross-attention maps used within VPD show that combining guidance from various model levels significantly improves performance by effectively utilizing low-level and high-level features.
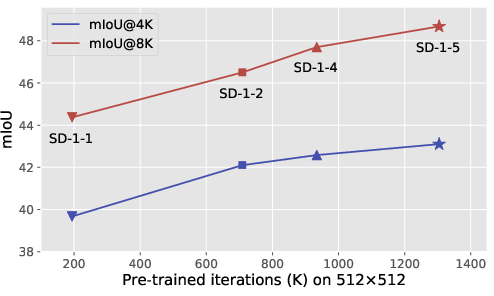
Figure 3: Longer pre-training yields better performance on downstream tasks. We train VPD with different versions of Stable-Diffusion (indicated by SD-1-x) on ADE20K and investigate how the pre-training iteration would affect the performance. The upward trend demonstrates that our VPD can benefit from a stronger text-to-image diffusion model.
Conclusion
The proposed VPD framework leverages the strengths of text-to-image diffusion models for visual perception tasks, achieving state-of-the-art results across multiple benchmarks. The research highlights a promising avenue for future work in integrating generative and recognition tasks, potentially unifying visual generation and perception in novel ways. As diffusion models continue to evolve, they may offer increasingly efficient and versatile solutions for diverse AI applications beyond image synthesis.