- The paper presents a Shared-Prefix Forward strategy that eliminates redundant encoding of shared prefixes, significantly enhancing GRPO training efficiency.
- It restructures self-attention into prefix self-attention and suffix attention, maintaining gradient equivalence while reducing FLOPs and GPU memory usage.
- Empirical evidence demonstrates that the approach scales well with large group sizes and long contexts, offering practical benefits for reinforcement learning tasks.
Prefix Grouper: Efficient GRPO Training
The paper "Prefix Grouper: Efficient GRPO Training through Shared-Prefix Forward" introduces an innovative approach to improve the efficiency of Group Relative Policy Optimization (GRPO) by addressing computational overhead associated with processing shared input prefixes. The Prefix Grouper algorithm is designed to eliminate redundant encoding of shared prefixes, which enhances computational efficiency and scalability in long-context learning scenarios.
Introduction to GRPO and Its Limitations
Group Relative Policy Optimization (GRPO) is a method used in optimizing LLMs for reinforcement learning that focuses on relative comparisons rather than explicit value function estimation. It stabilizes training by reducing gradient variance, beneficial for tasks like instruction following. However, GRPO implementations face challenges when handling long shared input prefixes, as each group member redundantly encodes the same prefix, resulting in scalability bottlenecks due to increased computational overhead.
Prefix Grouper Algorithm
The Prefix Grouper algorithm introduces a Shared-Prefix Forward strategy, facilitating the encoding of shared prefixes only once. This is achieved by restructuring self-attention computations into two parts:
- Prefix Self-Attention: This performs self-attention over shared prefix tokens, updating their contextual representations.
- Suffix Attention: This computes query embeddings from suffix tokens while using the full sequence (prefix + suffix) to compute keys and values. The suffix tokens attend to both prefix and suffix to obtain updated representations.
This approach preserves differentiability and is compatible with end-to-end training. It maintains equivalence to standard GRPO in optimization dynamics and performance, serving as a plug-and-play improvement without structural modifications.
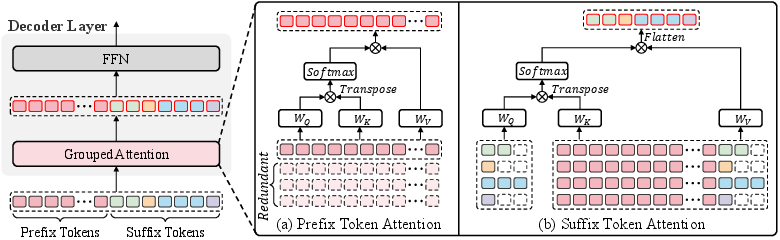
Figure 1: Method illustration of Grouped Attention in Prefix Grouper.
Implementation
The implementation involves restructuring the input sequence and decomposing attention computation as described. Pseudocode is provided to guide the integration into existing systems using a PyTorch-like syntax. The technique is compatible with current GRPO architectures and requires minimal changes to input construction and attention computation.
Gradient Equivalence and Computational Efficiency
The paper theoretically establishes the gradient equivalence between Prefix Grouper and standard GRPO. This ensures optimization dynamics remain unchanged while achieving computational efficiency gains. The Shared-Prefix Forward method reduces FLOPs substantially compared to the Repeated-Prefix Forward approach, particularly under scenarios with long prefixes and large group sizes.
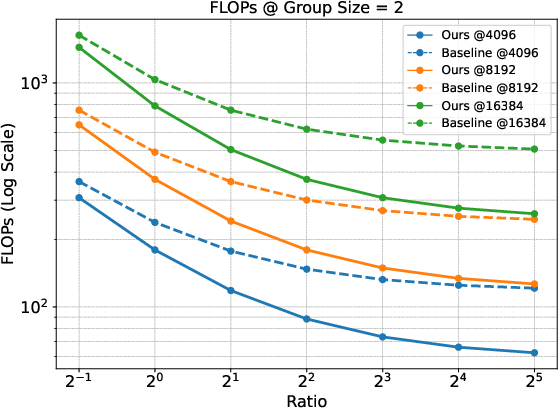
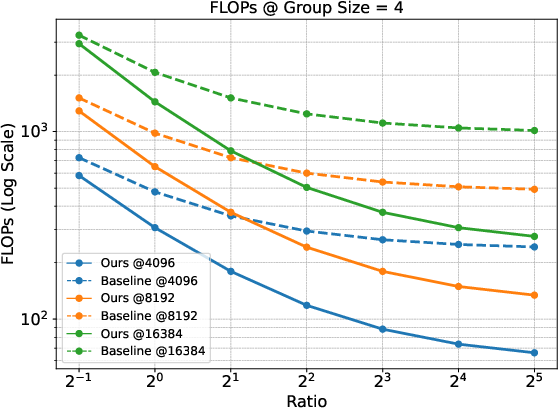
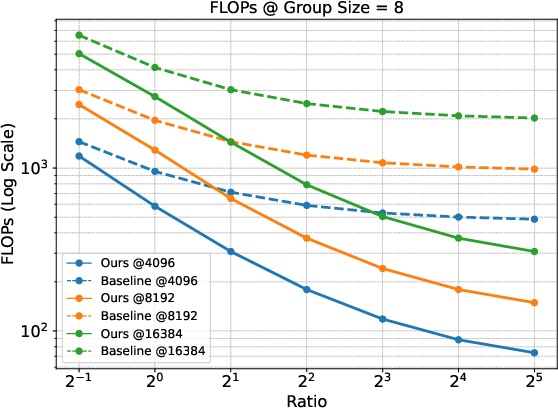
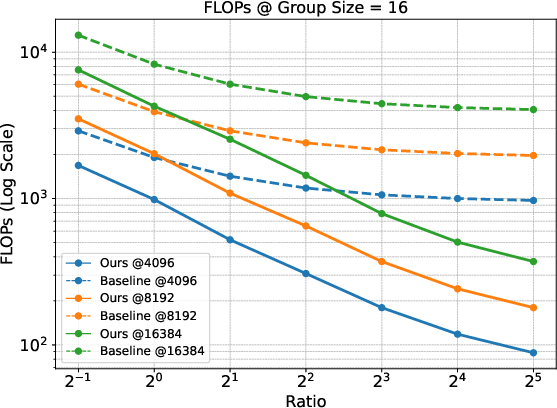
Figure 2: Comparison of FLOPs under different group sizes. The figure displays results at fixed prefix lengths (4096, 8192, and 16384) across different Ratios (prefix length / suffix length).
Memory Usage
Empirical results indicate a marked reduction in GPU memory usage when employing the Prefix Grouper method compared to traditional approaches. This efficiency is achieved across various group sizes and configurations, highlighting the practicality of the proposed method in resource-constrained environments.
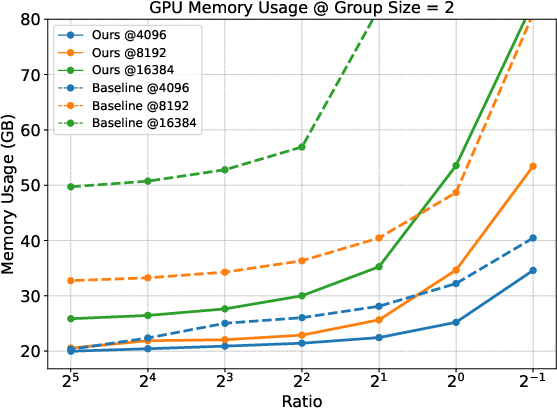
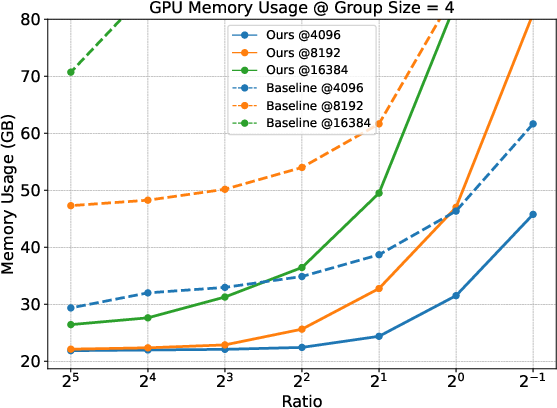
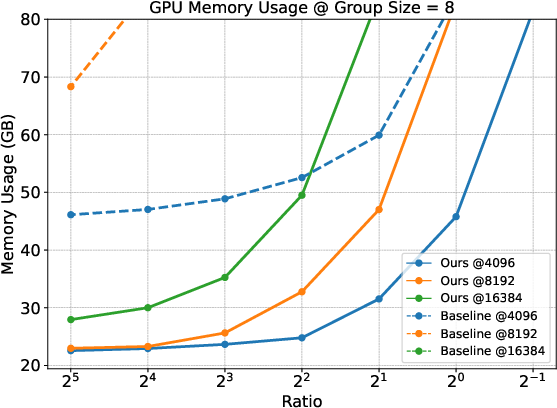
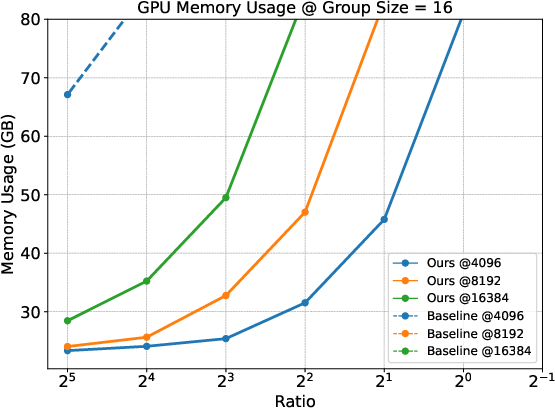
Figure 3: Comparison of memeory usage under different group sizes. The figure displays results at fixed prefix lengths (4096, 8192, and 16384) across different Ratios (prefix length / suffix length).
Conclusion
The Prefix Grouper offers a significant advancement in the training efficiency of GRPO by eliminating redundant computations of shared prefixes. It demonstrates substantial benefits in computational and memory usage, particularly in scenarios requiring long-context processing. This method enhances the scalability of GRPO, allowing for the exploration of more complex tasks and larger models without compromising performance. The paper provides theoretical guarantees and empirical evidence that make Prefix Grouper a valuable addition to the domain of reinforcement learning optimization.

