- The paper introduces GUI-Actor, a novel framework that bypasses coordinate-based methods by using an attention-based action head and a dedicated <ACTOR> token for direct GUI element identification.
- It applies spatial-aware multi-patch supervision and a grounding verifier to enhance robustness and sample efficiency in detecting GUI elements.
- Experimental results demonstrate state-of-the-art performance across multiple benchmarks, with improved generalization over varying screen layouts and resolutions.
GUI-Actor: Coordinate-Free Visual Grounding for GUI Agents
Introduction
The paper "GUI-Actor: Coordinate-Free Visual Grounding for GUI Agents" proposes a novel visual grounding framework that addresses the limitations of existing coordinate-based approaches for graphical user interface (GUI) agents. This work introduces GUI-Actor, a vision-LLM (VLM) leveraging an attention-based action head to achieve coordinate-free grounding. Unlike traditional methods that rely on generating numeric coordinates to interact with GUI elements, GUI-Actor directly identifies target regions using a dedicated <ACTOR> token, enhancing spatial-semantic alignment and generalization across varying screen layouts and resolutions.
Methodology
Overview of GUI-Actor
The GUI-Actor framework is built upon a VLM equipped with an attention-based action head, enabling the direct mapping of instructions to GUI elements without the need for coordinate generation.
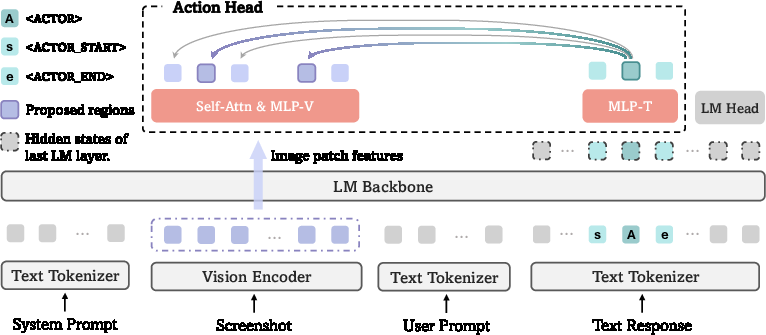
Figure 1: Overview of GUI-Actor. (a) Illustration of how the action head works with a VLM for coordinate-free GUI grounding. (b) Illustration of the spatial-aware multi-patch supervision for model training, labeling image patches as positive or negative based on ground-truth bounding boxes.
<ACTOR> Token as a Contextual Anchor
In lieu of calculating precise screen coordinates, GUI-Actor introduces a <ACTOR> token that processes visual and textual inputs simultaneously. This token serves as a contextual anchor within the model, facilitating the alignment of visual patch features with the target element.
Attention-Based Action Head
The action head computes attention scores over visual patch tokens derived from the screenshot, establishing a spatial activation map to highlight the most relevant regions for interaction. Through multi-patch supervision, the model accommodates the natural ambiguity present in GUI interactions, allowing for more robust target identification.
Grounding Verifier
A grounding verifier refines action decisions by evaluating multiple candidate regions. By scoring these candidates, the verifier enhances the model's grounding accuracy, ensuring the selected region aligns with the user's intent.
Experimental Results
GUI-Actor demonstrates state-of-the-art performance across multiple GUI grounding benchmarks, including ScreenSpot, ScreenSpot-v2, and the challenging ScreenSpot-Pro, which features high-resolution interfaces and significant domain shifts.
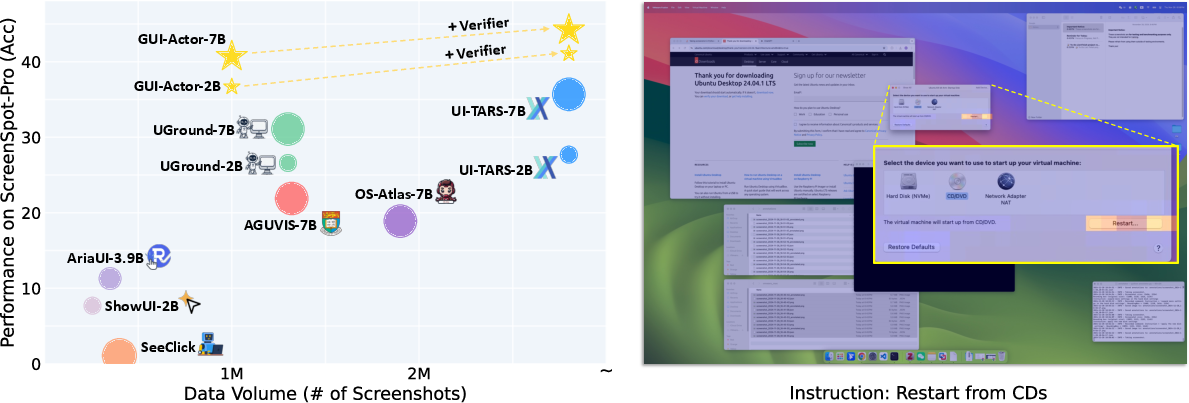
Figure 2: Left: Model performance vs. training data scale on the ScreenSpot-Pro benchmark. Right: Illustration of action attention. GUI-Actor grounds target elements by attending to the most relevant visual regions.
GUI-Actor outperforms previously established methods, especially under conditions that demand high generalization capabilities. The coordinate-free approach allows GUI-Actor to maintain competitive accuracy even with models that possess significantly fewer parameters and training data.
Robustness and Efficiency
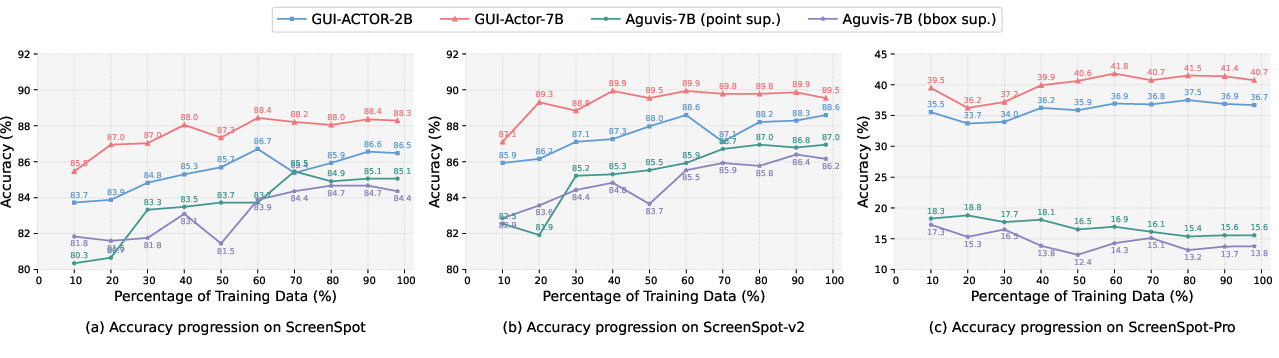
Figure 3: Accuracy Progression Over Training Steps.
GUI-Actor achieves enhanced sample efficiency, requiring less training data compared to coordinate-based approaches to reach similar or superior levels of accuracy. This efficiency is attributed to the model's explicit use of spatial-semantic alignment through its novel attention mechanism.
Discussion on Practical Implications
GUI-Actor exemplifies how VLMs can be tailored for GUI interaction without compromising their general-purpose capabilities. By fine-tuning only the newly introduced action head, the model equips the underlying VLM with effective visual grounding features, preserving its broad utility. The integration of a verifier further exemplifies the model's ability to refine action decisions efficiently, highlighting its potential for real-world applications across diverse user interfaces.
Conclusion
The GUI-Actor framework represents a significant advancement in the development of GUI agents, effectively circumventing the limitations of coordinate-based visual grounding methods. Its innovative use of attention-based mechanisms for direct region identification, coupled with a lightweight verifier, equips GUI agents with robust grounding capabilities adaptable to various screen configurations. The experimental results underscore its potential to set new standards in the field of GUI interactions, paving the path for future research on enhanced VLM integration for user interface tasks.