- The paper introduces a novel two-stage zoom-in technique that refines coarse bounding box predictions for more accurate GUI element localization.
- It employs an IoU-aware weighted cross-entropy loss to dynamically prioritize high-quality predictions, enhancing overall model performance.
- Experimental results reveal up to a 13% improvement in grounding accuracy, validating the approach's effectiveness in complex and cluttered interfaces.
"R-VLM: Region-Aware Vision LLM for Precise GUI Grounding"
Introduction
The paper introduces R-VLM, a Region-Aware Vision LLM specifically designed for GUI element grounding tasks. The model addresses the challenges of accurately grounding GUI elements in diverse and cluttered environments. Traditional methods suffer from limited grounding precision due to processing entire GUI screenshots and using basic cross-entropy loss functions. R-VLM significantly enhances grounding accuracy by combining a novel two-stage zoom-in approach with an IoU-aware weighted cross-entropy loss function to emphasize predictions with high Intersection-over-Union (IoU) scores.

Figure 1: Illustration of the Region-Aware Vision LLM (R-VLM), highlighting the two-stage zoom-in grounding process and the IoU-aware weighted cross-entropy loss.
Two-Stage Zoom-In Grounding
R-VLM introduces a two-stage zoom-in grounding technique that refines initial predictions by focusing on zoomed-in regions. Initially, a coarse bounding box prediction is generated, followed by a zoomed-in view around this region to refine the prediction. This process mimics region proposal networks used in object detection, allowing for precise focus on areas of interest and reducing the influence of irrelevant context. The Zoom-in scale adapts dynamically based on the estimated size of the GUI element, which helps address inaccurate localization in cluttered interfaces.
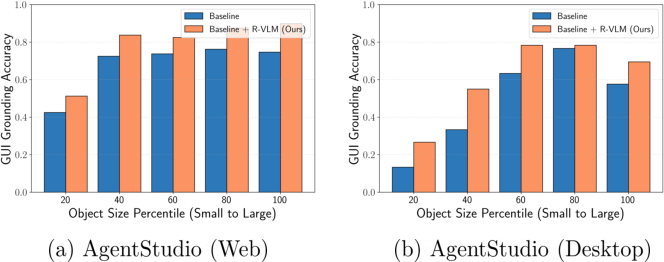
Figure 2: Grounding accuracy of GUI elements on the GroundUI-1K dataset, showing improvements across different object sizes.
IoU-Aware Weighted Cross-Entropy Loss
Existing methods use basic cross-entropy loss for training, failing to incorporate feedback on the quality of predictions concerning IoU with the ground-truth bounding boxes. R-VLM's IoU-aware weighted loss function dynamically adjusts weights for each pseudo bounding box during training. This provides continuous learning signals that prioritize high-IoU predictions, akin to conventional object detection practices. By generating multiple pseudo ground-truth boxes and weighting them by their IoU scores, this approach effectively guides the model to learn robust bounding box predictions without computational overhead.
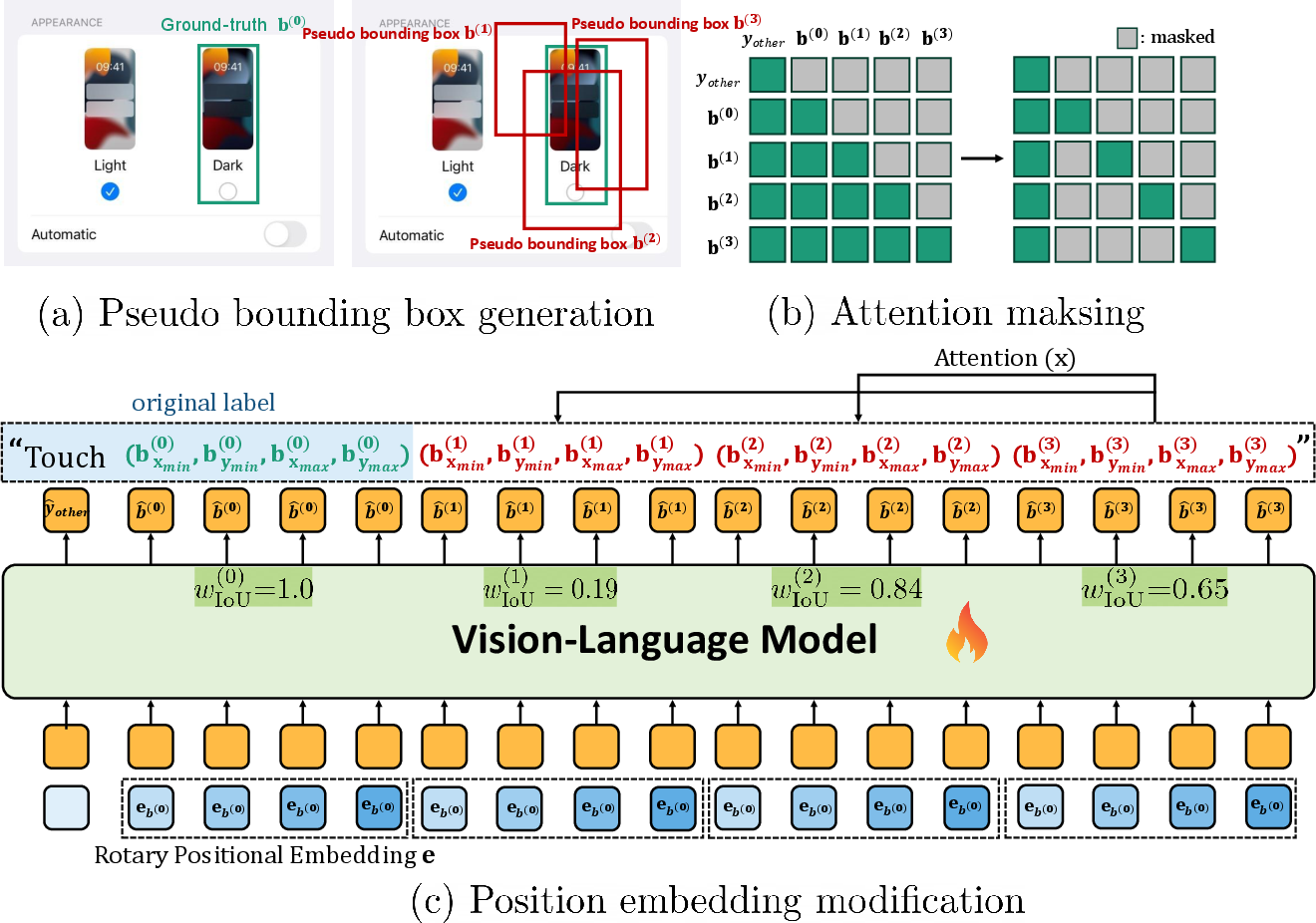
Figure 3: Efficient IoU-aware cross-entropy computation process illustrating the generation of pseudo boxes and the adjusted attention mechanism.
Experimental Results
R-VLM demonstrates substantial advancements over state-of-the-art models on multiple benchmarks, achieving a 13% improvement in grounding accuracy on datasets like ScreenSpot and AgentStudio. By refining predictions using the zoom-in technique and leveraging the IoU-aware objective, R-VLM facilitates improved performance on direct grounding tasks and complex GUI navigation tasks. The model also shows an average improvement of 3.2-9.7% in GUI navigation accuracy across various benchmarks, indicating its practical applicability in real-world GUI automation.
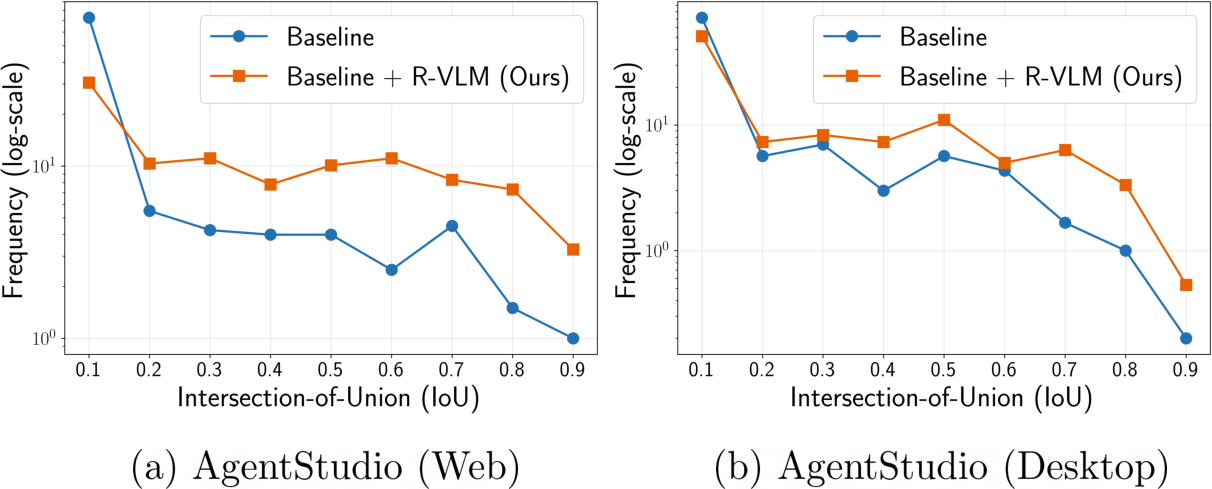
Figure 4: Comparison of IoU histograms between R-VLM and baseline methods, evidencing higher IoU-value prediction patterns with R-VLM.
Conclusion
The incorporation of a two-stage zoom-in approach combined with an innovative IoU-aware loss function allows R-VLM to achieve precise GUI grounding across varying interfaces. This results in enhanced interaction reliability in automated GUI tasks by ensuring high-fidelity element localization. R-VLM's design enables seamless integration with existing VLMs and proves effective even in training-free settings, further expanding its potential for improving automatic GUI grounding systems. Future work could explore refining region proposal mechanisms to enhance recall rates further, addressing limitations where initial predictions deviate from the target.
Overall, R-VLM represents a significant step toward enhancing precision and reliability in GUI element grounding tasks, offering scalable integration options for vision LLMs across diverse applications.