- The paper introduces a hybrid diarization system that integrates neural and traditional clustering methods to effectively manage overlapping speech in meeting scenarios.
- It employs a novel ASR-aware observation addition strategy that leverages multiple audio streams to reduce error rates, achieving a 9.48% CER.
- The system dynamically adapts based on overlap levels, demonstrating significant improvements in DER and robust performance in low SNR environments.
Overlap-Adaptive Hybrid Speaker Diarization and ASR-Aware Observation Addition
Introduction
The paper "Overlap-Adaptive Hybrid Speaker Diarization and ASR-Aware Observation Addition for MISP 2025 Challenge" introduces a novel system designed to address the specific requirements of the MISP 2025 Challenge. This system focuses on two critical components of speech processing: speaker diarization and automatic speech recognition (ASR). By proposing a hybrid approach that integrates advanced end-to-end neural methods with traditional clustering techniques, the authors successfully tackle overlapping speech scenarios which are prevalent in real-world meetings. Furthermore, their ASR-aware observation addition method significantly enhances speech recognition in low signal-to-noise ratio (SNR) environments by efficiently leveraging both original and separated speech sources.
Hybrid Speaker Diarization System
The proposed speaker diarization system employs a hybrid approach, combining an end-to-end method with traditional diarization techniques to adapt to different levels of speech overlap. The end-to-end segmentations are achieved using a novel architecture built on WavLM and Conformer, replacing previous SincNet+LSTM setups. Traditional methods supplement this by employing VBx clustering, which is more effective in low overlap scenarios.
The system dynamically selects between these methods based on the proportion of overlapping speech determined during initial processing. For instance, scenarios with less than 1\% overlapping speech are typically resolved using the traditional diarization method, while higher overlap cases benefit from the end-to-end model capabilities.
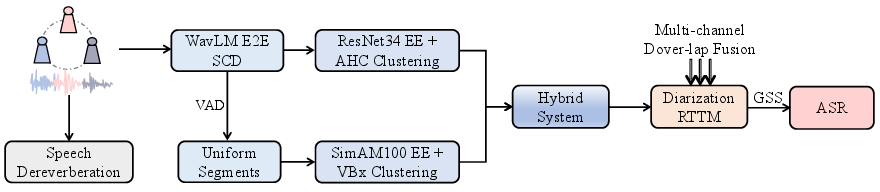
Figure 1: The overall workflow of the combined diarization and ASR system submitted for MISP 2025 challenge.
ASR-Aware Observation Addition
Addressing limitations in ASR performance, particularly under low SNR conditions, the paper introduces an ASR-aware observation addition framework. This framework integrates multiple input streams, namely the Mossformer2-separated speech, GSS-separated speech, and the original noisy speech, to compensate for the deficiencies of the GSS algorithm.
The novel contribution here lies in the design of a bridging module that adapts the Observation Addition (OA) coefficients to maximize ASR performance metrics. By utilizing ASR-derived parameters such as character error rates (CER) as feedback for optimization, the system efficiently tunes these coefficients, handling various input audio conditions adaptively.
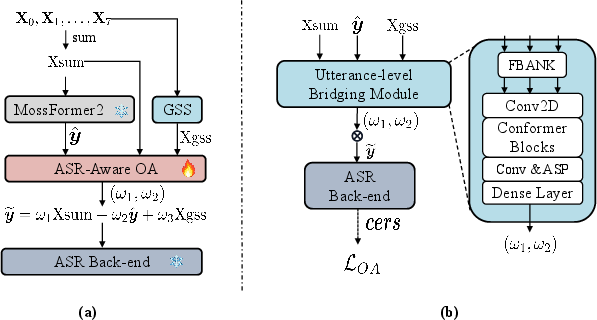
Figure 2: Our proposed ASR-aware observation-adding system (a) Overall framework (b)Bridging module structure.
Dataset and Experimental Results
The system has been trained and evaluated using substantial datasets, including near-field data from MISP2025 and far-field datasets like Alimeeting and AISHELL4. The experiments demonstrate substantial enhancements in diarization error rate (DER) and CER over baseline models. Specifically, the hybrid diarization approach achieves significant DER reductions, and the ASR-aware OA method achieves a CER of 9.48\% on the evaluation set, reflecting its robustness against noise and overlap.
Conclusion
This research offers a comprehensive approach to simultaneously improve speaker diarization and ASR in complex, noisy environments typical of meeting scenarios. By effectively integrating innovative observation addition strategies with a robust diarization architecture, the system advances the MISP 2025 Challenge requirements, demonstrating its potential for broader application in real-world multimodal processing environments. While the research highlights the limitations of current video integration strategies, it also sets the groundwork for future exploration into effective multimodal processing techniques that better leverage video data alongside audio.