- The paper introduces PathFinder-PRM#1, which decouples error detection from reward optimization to enhance process accuracy in multi-step reasoning.
- It employs a two-pass masked language modeling approach to distinguish and classify math and consistency errors at each step.
- Results on benchmarks like PRMBench demonstrate state-of-the-art performance using approximately three times less data than previous models.
Error Typing for Smarter Rewards: Improving Process Reward Models with Error-Aware Hierarchical Supervision
Introduction
LLMs have become instrumental in several domains, particularly in tasks requiring complex reasoning and multi-step solutions, such as mathematical problem-solving. Despite their success, LLMs frequently encounter issues like hallucinations and logical missteps, especially with tasks that demand rigorous reasoning. Existing methods like Outcome Reward Models verify only the final outcome, leaving intermediate errors unchecked and potentially leading to incorrect conclusions. To bridge this gap, researchers have introduced Process Reward Models (PRMs) that evaluate each step within a reasoning process to enhance trajectory accuracy. The paper presents PathFinder-PRM#1, a novel hierarchical PRM that distinguishes between math and consistency errors to provide more detailed supervision signals.

Figure 1: Comparing the Methodology of Existing PRMs against PathFinder-PRM#1.
Methodology
PathFinder-PRM#1 is designed to overcome the limitations of current PRMs which typically conflate error detection with path optimality in a single signal. This paper decouples these components into distinct tasks to improve accuracy and interpretability. PathFinder-PRM#1 not only identifies errors across two categories—mathematical logic and consistency—but also leverages these findings to guide step optimality.
To achieve this, the researchers augmented existing datasets, PRM800K and RLHFlow Mistral, with enriched labels to form a training corpus of 400K annotated reasoning trajectories. The model classifies each step into math and consistency accuracy, and then assesses overall correctness. This hierarchical process allows the PRM to provide granular feedback at every step, significantly improving both error detection and trajectory guidance.
PathFinder-PRM#1 was trained using a two-pass approach. During the first pass, it predicts error labels using masked language modeling. The second pass involves predicting the correctness of the step, conditioned on the identified error labels, which provides a more robust and nuanced evaluation.
Results
The effectiveness of PathFinder-PRM#1 was evaluated on benchmarks such as ProcessBench and PRMBench. The results indicate that PathFinder-PRM#1 achieves state-of-the-art performance among PRMs. Specifically, it surpassed previous models by achieving a PRMScore of 67.7 on PRMBench and showed superior data efficiency by achieving these results using approximately three times less data than the leading benchmark Figure 2.
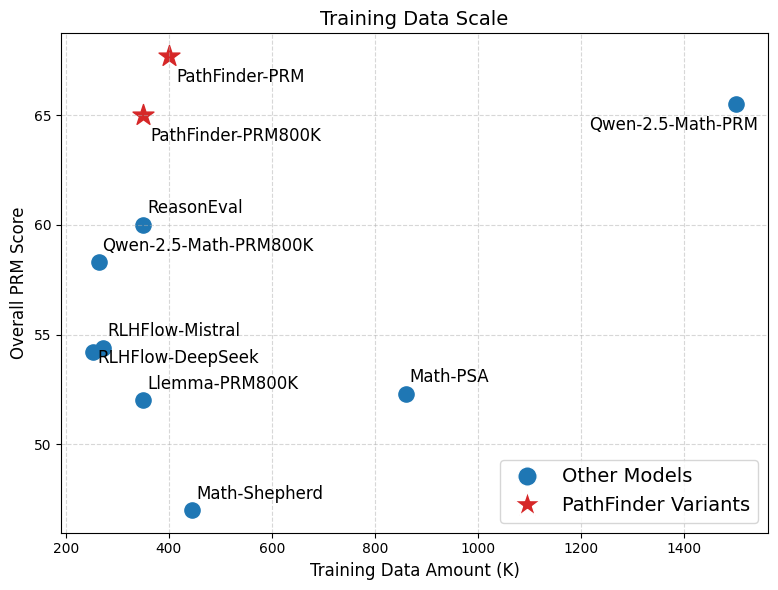
Figure 2: PRMBench Overall PRMscore against the data scales of different baselines and PathFinder-PRM#1 variants.
Furthermore, PathFinder-PRM#1 demonstrated gains in reward-guided greedy search tasks, yielding a higher prm@8 score compared to strong baseline models. The hierarchical supervision approach not only improved process-level understanding and interpretation but also led to better quality solution paths in practice.
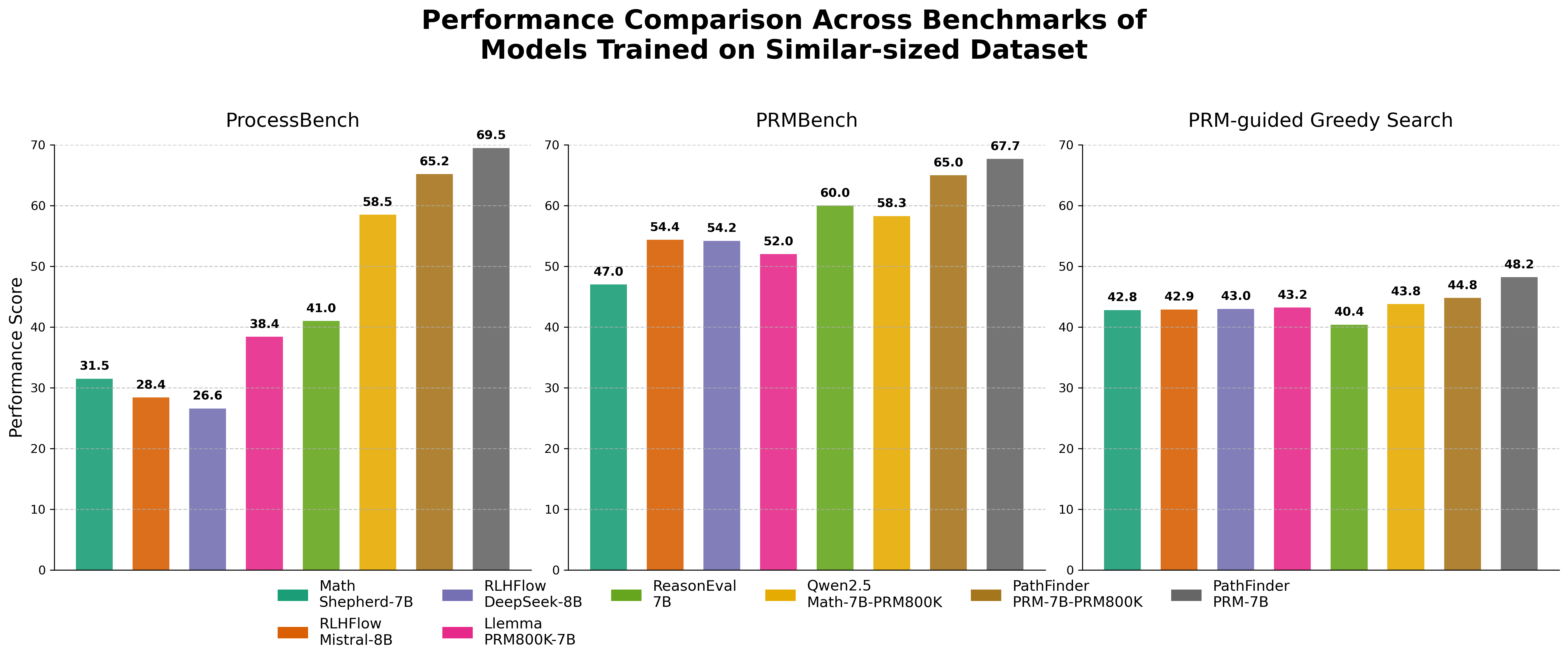
Figure 3: Performance comparison of LLMs across three benchmarks. The PathFinder-PRM#1-7B model (gray) shows the highest performance across all benchmarks.
Implications
The results underscore the importance of fine-grained error detection and targeted reward modeling in advancing the capabilities of PRMs. PathFinder-PRM#1's ability to maintain robust performance with limited data demonstrates the potential for better resource efficiency in AI models. This research could significantly impact AI applications requiring complex reasoning, such as automated theorem proving and advanced computational problem-solving, by providing a framework that enhances model reliability and interpretability.
Conclusion
The introduction of PathFinder-PRM#1 marks a significant step forward in the development of PRMs by introducing hierarchical error detection and reward estimation. Its ability to leverage detailed step-level feedback to improve reasoning accuracy and efficiency provides a promising direction for future research and application in AI-driven decision-support systems. By addressing current PRM limitations and showing scalability and robustness, this model sets a precedent for further advancements in intelligent process modeling.

