- The paper introduces Socratic-PRMBench, a novel benchmark that systematically evaluates Process Reward Models (PRMs) by categorizing errors across six distinct reasoning patterns.
- The paper demonstrates that current PRMs exhibit imbalanced performance, error detection delays, and reward biases, with Qwen2.5-Math-PRM scoring an overall 68.0.
- The benchmark highlights the need for improved training data and early error detection to enhance the accuracy and reliability of LLMs in complex reasoning tasks.
Socratic-PRMBench: A Systematic Evaluation of Process Reward Models
This paper introduces Socratic-PRMBench, a novel benchmark designed for the systematic evaluation of Process Reward Models (PRMs) across diverse reasoning patterns. PRMs are critical for enhancing the performance of LLMs in complex reasoning and decision-making tasks, particularly in long-horizon decision-making scenarios. The benchmark addresses the gap in existing evaluation methods by focusing on the ability of PRMs to detect errors within specific reasoning patterns, which is essential for ensuring the reliability and accuracy of LLMs in real-world applications.
Motivation and Background
LLMs often employ various reasoning patterns, such as decomposition and deduction, when solving problems. However, PRMs can struggle to consistently provide accurate rewards across these diverse patterns. The paper highlights a scenario where a PRM fails to identify an error stemming from a decomposition pattern, even when it correctly identifies a subsequent error in a deduction pattern (Figure 1). This inconsistency undermines the reliability of current PRMs and emphasizes the need for a more comprehensive evaluation framework.
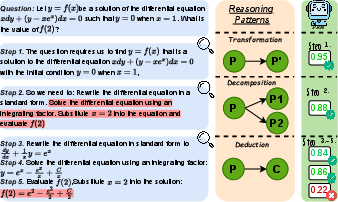
Figure 1: Given a question, the reasoning step 2 and 5 contain errors. (Medium): Each step applys a specific reasoning pattern. (Right): The process reward model successfully detects the error of Deduction pattern but fails with the Decomposition reasoning pattern.
Existing benchmarks primarily assess PRMs based on stepwise correctness, overlooking the nuanced error detection required across different reasoning patterns. Socratic-PRMBench aims to fill this void by providing a structured approach to evaluate PRMs under six distinct reasoning patterns: Transformation, Decomposition, Regather, Deduction, Verification, and Integration.
Socratic-PRMBench Design
Socratic-PRMBench comprises 2995 reasoning paths, each containing flaws categorized according to the six reasoning patterns and further divided into 20 sub-categories of fine-grained error types (Figure 2). The benchmark's construction is inspired by the logical theories of Socrates, categorizing reasoning into atomic patterns and systematically designing errors within these patterns.
Figure 2: An overview of our Socratic-PRMBench. The left part illustrates our dataset constuction procedure. The right part illustrates the 6 reasoning patterns and 20 sub-categories of fine-grained error types. We use P and C to represent (sub)problems and conclusions, respectively. We use Q, R, G to represent gathered information, redundant contents, and ground truth.
The data annotation process is fully automated using LLMs, ensuring efficiency and scalability while maintaining quality through rule-based filtering and expert review. The benchmark is designed to systematically assess PRMs' proficiency in detecting errors across the identified reasoning patterns.
Reasoning Patterns and Error Categories
The benchmark categorizes reasoning into six atomic reasoning patterns:
- Transformation: Converts the problem into a homogeneous or similar form. Error types include Transformation Inconsistency and Transformation Counter-Factuality.
- Decomposition: Breaks the problem into manageable subproblems. Error types include Decomposition Unsoundness, Decomposition Redundancy, and Decomposition Incompleteness.
- Regather: Collects key information relevant to solving the problem. Error types include Regather Imprecision, Regather Redundancy, and Regather Incompleteness.
- Deduction: Derives a conclusion from a given premise. Error types include Premise Unsoundness, Premise Incompleteness, Premise Redundancy, Conclusion Invalidity, Conclusion Inconsistency, and Conclusion Counter-Factuality.
- Verification: Examines reasoning steps for accuracy and consistency. Error types include Detection Error and Correction Error.
- Integration: Summarizes conclusions to derive a new conclusion. Error types include Integration Inconsistency, Integration Incompleteness, Integration Redundancy, and Integration Unsoundness.
Experimental Results
The paper presents extensive experimental results using a range of models, including open-source PRMs and general-purpose LLMs prompted as critic models. The evaluation reveals significant deficiencies in current PRMs. The highest-performing PRM, Qwen2.5-Math-PRM, achieved an overall score of 68.0, highlighting the considerable scope for improvement. The experiments also identify substantial disparities in error detection capabilities across different reasoning patterns, latency in identifying error steps, and reward generation bias.
A key finding is the imbalanced performance of both PRMs and LLMs across different reasoning patterns (Figure 3). Models consistently performed weaker on Transformation, Decomposition, and Regather patterns compared to Deduction, Integration, and Verification. This imbalance suggests a bias in current PRM training data construction, where certain reasoning patterns are underrepresented.
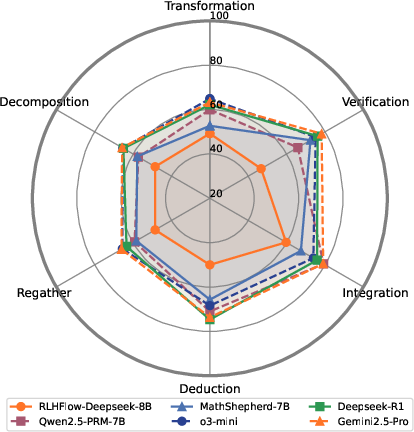
Figure 3: Average PRM-Score of representative PRMs and LLMs across 6 reasoning patterns. Both PRMs and LLMs shows imbalanced performance.
Further analysis reveals that models exhibit latency in identifying error steps, with Qwen2.5-Math-PRM and o3-mini showing a delay in detecting early errors (Figure 4). This latency implies a limited ability to detect errors early on, allowing them to propagate through the reasoning process.
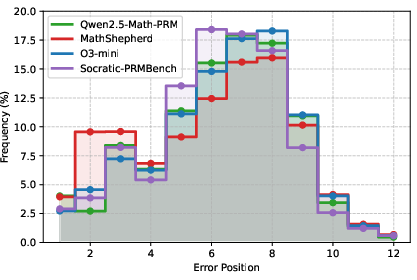
Figure 4: Error position distribution (truncated to 12) of Socratic-PRMBench and the predicted error position distribution of several PRMs and LLMs.
The study also quantifies reward bias within PRMs, demonstrating that some models heavily favor positive rewards while others tend to provide negative rewards. This bias can significantly affect the reliability of PRMs in accurately assessing reasoning steps.
Implications and Future Directions
The findings from Socratic-PRMBench highlight the limitations of current PRMs in handling diverse reasoning patterns and detecting errors effectively. The benchmark provides a valuable tool for comprehensively assessing PRMs and guiding future development efforts. Key implications include:
- Need for Improved Training Data: The imbalanced performance across reasoning patterns underscores the importance of constructing PRM training data that adequately represents different reasoning patterns.
- Importance of Early Error Detection: The latency in identifying error steps emphasizes the need for models that can detect errors early in the reasoning process to prevent error propagation.
- Mitigating Reward Bias: The identified reward bias within PRMs suggests the need for strategies to mitigate this bias and ensure more accurate and reliable reward generation.
Future research directions include expanding the benchmark to encompass a broader range of tasks beyond mathematical problem-solving and developing new PRMs that address the identified limitations.
Conclusion
Socratic-PRMBench represents a significant advancement in the evaluation of PRMs by providing a systematic and fine-grained assessment framework. The benchmark's comprehensive design, coupled with its automated data annotation process, offers a valuable resource for researchers and practitioners working to improve the reliability and accuracy of PRMs in complex reasoning tasks. The insights gained from Socratic-PRMBench can pave the way for future developments in PRM technology and enhance the performance of LLMs in real-world applications.