- The paper demonstrates that integrating Multi-Task Behavior Imitation and speech-text interleaving significantly improves SLLM generalization across tasks.
- By employing a frozen speech encoder and LLM decoder with a trainable connector, the method effectively aligns speech and text modalities.
- The approach outperforms state-of-the-art SLLMs in zero-shot tasks and benchmark evaluations, offering robust insights for future research.
Enhancing Generalization of Speech LLMs with Multi-Task Behavior Imitation and Speech-Text Interleaving
Introduction
The study explores advancements in Speech LLMs (SLLMs), a field crucial for leveraging the generalization abilities of LLMs to speech processing. Despite the potential of integrating speech with LLMs, current models suffer from poor generalization due to limited annotated speech data. The paper presents a novel approach named Multi-Task Behavior Imitation (MTBI) combined with speech-text interleaving to overcome these limitations.
Methodology
The authors propose an SLLM architecture consisting of a frozen speech encoder, a trainable connector, and a frozen LLM decoder. This setup aims to enhance the alignment between speech and text modalities, improving the model's generalization capabilities.
Behavior Imitation Training: This innovative method is split into two stages. Initially, the LLM decoder generates responses based on text transcriptions of speech inputs. Subsequently, the SLLM is trained to reproduce these responses using the paired speech, which ensures that the model processes speech akin to text, enhancing alignment and utilizing the LLM's knowledge for various tasks.
Multi-Task Learning: Training across multiple tasks, such as intent classification and speech translation, allows the model to learn generalized representations applicable to different domains. The authors address data quality concerns by using high-quality ASR datasets like LibriSpeech and introducing content-related tasks like continuation, rewriting, and selecting verbs or nouns from speech.
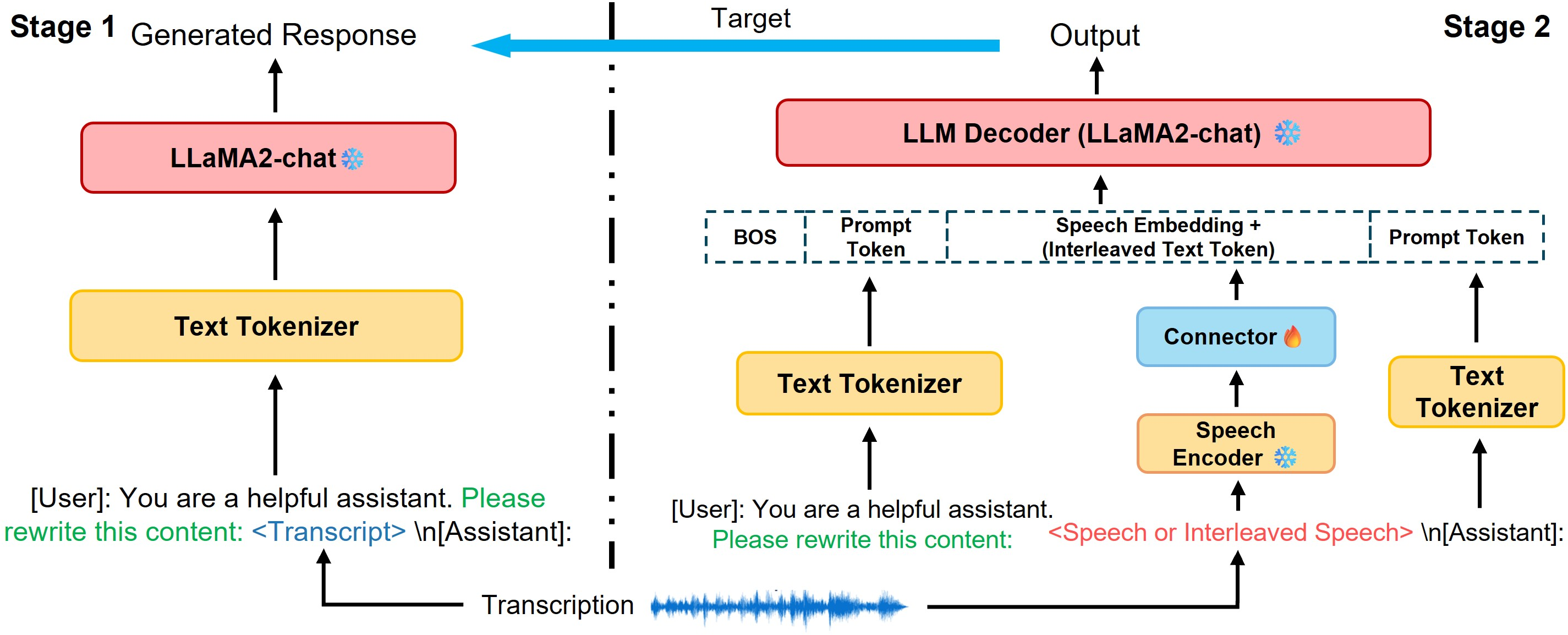
Figure 1: Overview of the SLLM architecture. The training process is conducted in two stages using the same text LLM.
Speech-Text Interleaving: Inspired by TTS techniques, this strategy involves mixing speech and text inputs, improving modality alignment. This method enables the SLLM to better handle the interplay between different input types, enhancing generalization.
Evaluation and Results
The paper introduces a benchmark for evaluating SLLM generalization across prompt and task dimensions. The benchmark includes assessments like prompt diversity in ASR and zero-shot capabilities in mathematical reasoning and speaker role inference. The experimental results indicate that MTBI surpasses state-of-the-art SLLMs in both prompt and task generalization metrics. Particularly, the method achieved notable improvements in zero-shot task execution, indicative of enhanced emergent abilities.
The comparison to cascaded models reveals that MTBI performs comparably to text-based LLMs using ground truth transcriptions. However, it slightly lags in mathematical tasks requiring precise transcription due to potential errors, common in speech-to-text conversion.
Conclusion
The research presents a significant step in SLLMs, showing that the MTBI method, coupled with speech-text interleaving, effectively enhances model generalization. This approach reduces reliance on extensive annotated data, utilizing cost-effective transcription, and offers a robust framework for future SLLM development. The study's benchmark provides a valuable tool for systematically evaluating SLLM capabilities, promoting further advancements in this domain. Future research could focus on incorporating more non-linguistic speech features to enhance SLLM comprehensiveness.

