- The paper introduces a novel framework using Vision Foundation Models to transform LiDAR data into RIV images.
- It employs MultiConv adapters and a Patch-InfoNCE loss for enhanced feature discriminability and spatial alignment.
- Results show superior intra-session recall and robust inter-session generalization compared to SOTA methods.
ImLPR: Image-based LiDAR Place Recognition using Vision Foundation Models
Introduction
The "ImLPR" framework presents a novel approach in the domain of LiDAR Place Recognition (LPR) by integrating Vision Foundation Models (VFM) such as DINOv2 into the LPR process. Traditionally, LPR has relied on task-specific models limited in their capacity to utilize pre-trained knowledge. ImLPR addresses this by converting LiDAR point clouds into a Range-Intensity-View (RIV) format compatible with pre-trained VFMs, thereby maintaining the majority of their pre-trained capabilities. This paper outlines various technical contributions, including the use of MultiConv adapters and a novel Patch-InfoNCE loss to improve feature discriminability.
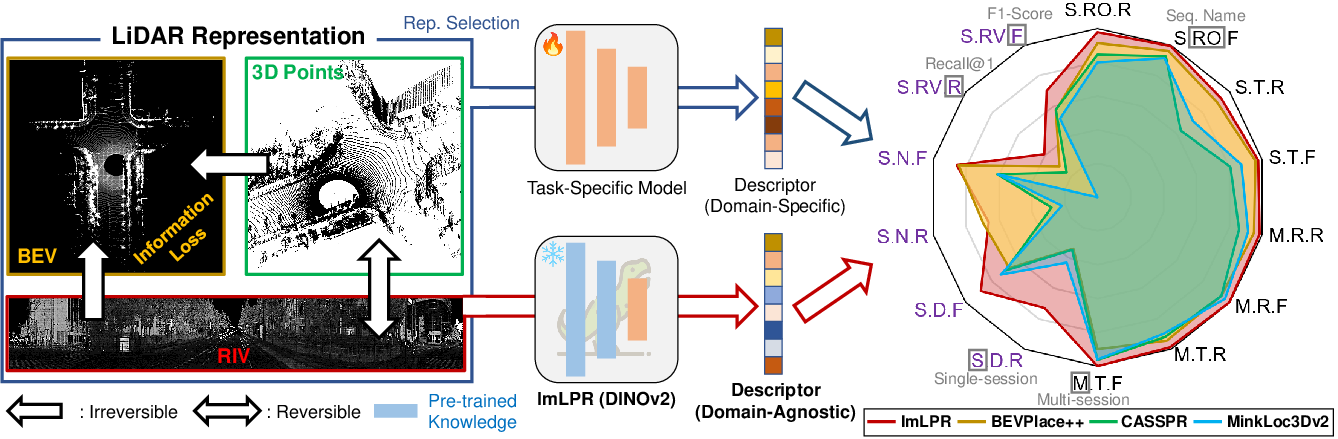
Figure 1: Without using a foundation model, traditional LPR relies on domain-specific training with 3D point clouds, BEV, or RIV.
Methodology
Data Processing and Feature Extraction
In ImLPR, raw point clouds are transformed into three-channel RIV images capturing reflectivity, range, and normal channels. This allows pre-trained VFMs to extract rich features that are both geometrically and semantically informed.
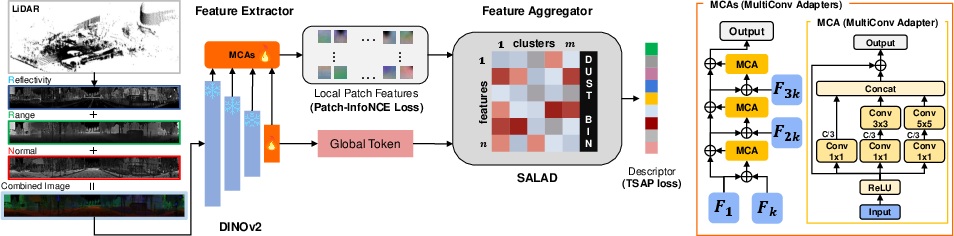
Figure 2: The point cloud is projected into a RIV image containing reflectivity, range, and normal channels.
To bridge the gap between RIV images and the pre-trained knowledge, MultiConv adapters are introduced. This design ensures preservation of pre-trained model performance while tailoring the network to address the unique characteristics of LiDAR data. The adapters function by refining intermediate patch features while maintaining global consistency.
Patch-Level Contrastive Learning
The Patch-InfoNCE loss is introduced for enhancing feature discriminability at a local level. This loss is crucial for LiDAR as it aligns patches based on their spatial consistency from transformed point clouds. Positive patch pairs are identified through alignment procedures using Iterative Closest Point (ICP), ensuring spatially consistent features are learned.
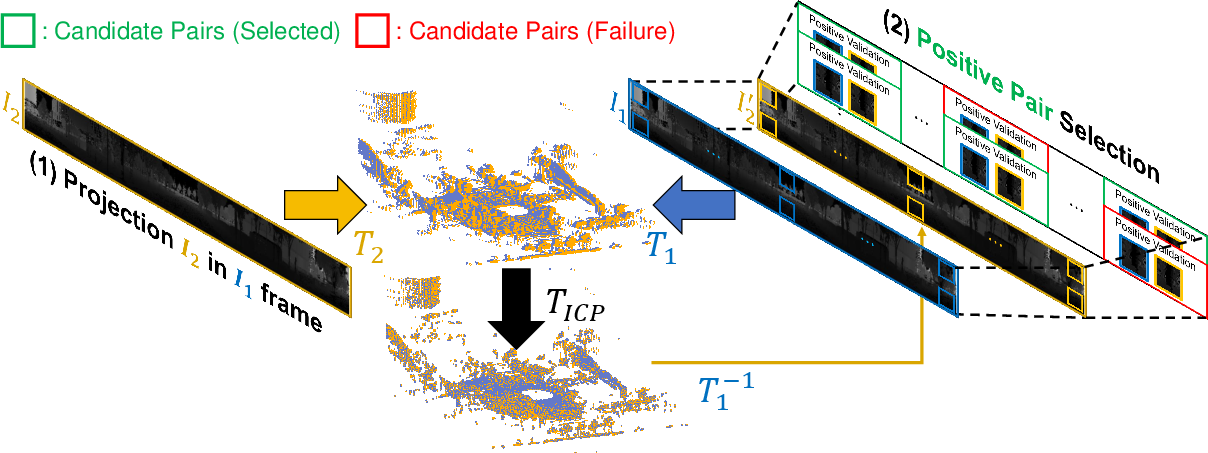
Figure 3: Patch correspondence pipeline aligns two RIV images by transforming their point clouds to a shared coordinate system using known poses and ICP.
Results and Evaluations
ImLPR demonstrates superior performance in intra-session place recognition when compared against state-of-the-art (SOTA) methods. Its use of RIV images enables finer feature discrimination, resulting in higher Recall@1 and F1 scores in comparison to methods using BEV representations.
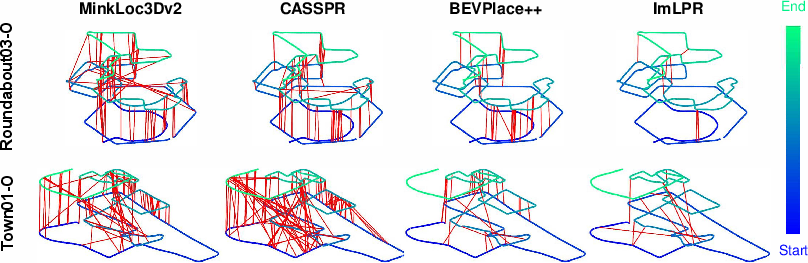
Figure 4: Trajectory from two sequences, with red lines marking false positives (fewer red lines indicate better performance).
Inter-Session Generalization
The system’s robustness extends to inter-session recognition across different environments and LiDAR sensors. Despite changes in environmental conditions and sensor types, ImLPR maintains high performance due to the robustness imparted by VFMs and the use of strategic RIV representations.

Figure 5: F1-Recall curve for inter-session place recognition.
Conclusions and Future Work
ImLPR successfully integrates VFM approaches into the LPR domain, setting new benchmarks for performance. Future directions may explore integration with other types of foundation models, such as segmentation networks, to enhance retrieval scenarios. This could include systems where local patch features are refined and dynamically re-ranked, further improving place recognition accuracy.
Limitations
While ImLPR’s results are promising, its efficacy is currently bounded to scenarios where homogeneous LiDAR sensors are utilized. Future work is required to extend its capabilities toward heterogeneous LPR, where varying LiDAR technologies necessitate more complex normalization strategies.
In conclusion, ImLPR exemplifies a significant step forward in applying vision foundation model strategies to the domain of LiDAR data processing, offering both theoretical insights and practical advancements in automated place recognition tasks.

