- The paper presents a new framework that explicitly models creator intent in multimodal news through components for desired influence and execution plan.
- The authors develop the DeceptionDecoded benchmark with 12,000 image-caption pairs to evaluate misleading intent detection, source attribution, and desire inference.
- Experiments reveal that current vision-language models struggle with subtle deceptive cues, showing low accuracy and over-reliance on superficial image-text consistency.
Unveiling Misleading Creator Intent in Multimodal News with Vision-LLMs
Introduction
The paper "Seeing Through Deception: Uncovering Misleading Creator Intent in Multimodal News with Vision-LLMs" addresses the crucial challenge of detecting misleading creator intent in multimodal misinformation. Traditional multimodal misinformation detection (MMD) systems often focus on identifying cross-modal inconsistencies, such as out-of-context misinformation or subtle manipulations. However, these approaches lack the ability to capture the underlying intents of misinformation creators, which is essential for effective governance. The authors propose a novel framework to simulate real-world multimodal news creation by explicitly modeling creator intent with two components: desired influence and execution plan.
The resulting benchmark, DeceptionDecoded, consists of 12,000 image-caption pairs, capturing both misleading and non-misleading intents across visual and textual modalities. The framework enables a comprehensive evaluation of state-of-the-art vision-LLMs (VLMs) on tasks such as misleading intent detection, source attribution, and creator desire inference.

Figure 1: The importance of detecting misleading creation intent in multimodal news beyond surface-level cross-modal consistency. For instance, a malicious creator can craft captions that are semantically consistent with the image yet deliberately convey a false narrative.
DeceptionDecoded Benchmark
Framework and Dataset Construction
DeceptionDecoded is constructed using a framework that models diverse creator intents through desired influence and execution plans. By leveraging strategic communication theories, the framework supports the simulation of both malicious and trustworthy news creation. The dataset is derived from VisualNews and includes image-caption pairs aligned with reliable reference articles for contextual grounding.
Human Validation and Evaluation Tasks
Rigorous human evaluation protocols ensure the quality and realism of generated data. DeceptionDecoded supports three evaluation tasks:
- Misleading Intent Detection: Classifying news pieces as misleading or non-misleading.
- Source Attribution: Identifying whether misleading signals originate from text or image modalities.
- Creator Desire Inference: Inferring the societal influence intended by the creator.
Evaluation of VLMs on these tasks reveals significant challenges in detecting misleading intent.
Experiments and Analysis
Evaluation of Vision-LLMs
The authors evaluate 14 VLMs, observing that models struggle with misleading creator intent, often relying on superficial cues like image-text consistency and stylistic patterns. For example, GPT-4o-mini achieves a low accuracy of 18.8% when misleading intent is subtle. This finding is indicative of the models' over-reliance on cross-modal consistency rather than deeper semantic reasoning.
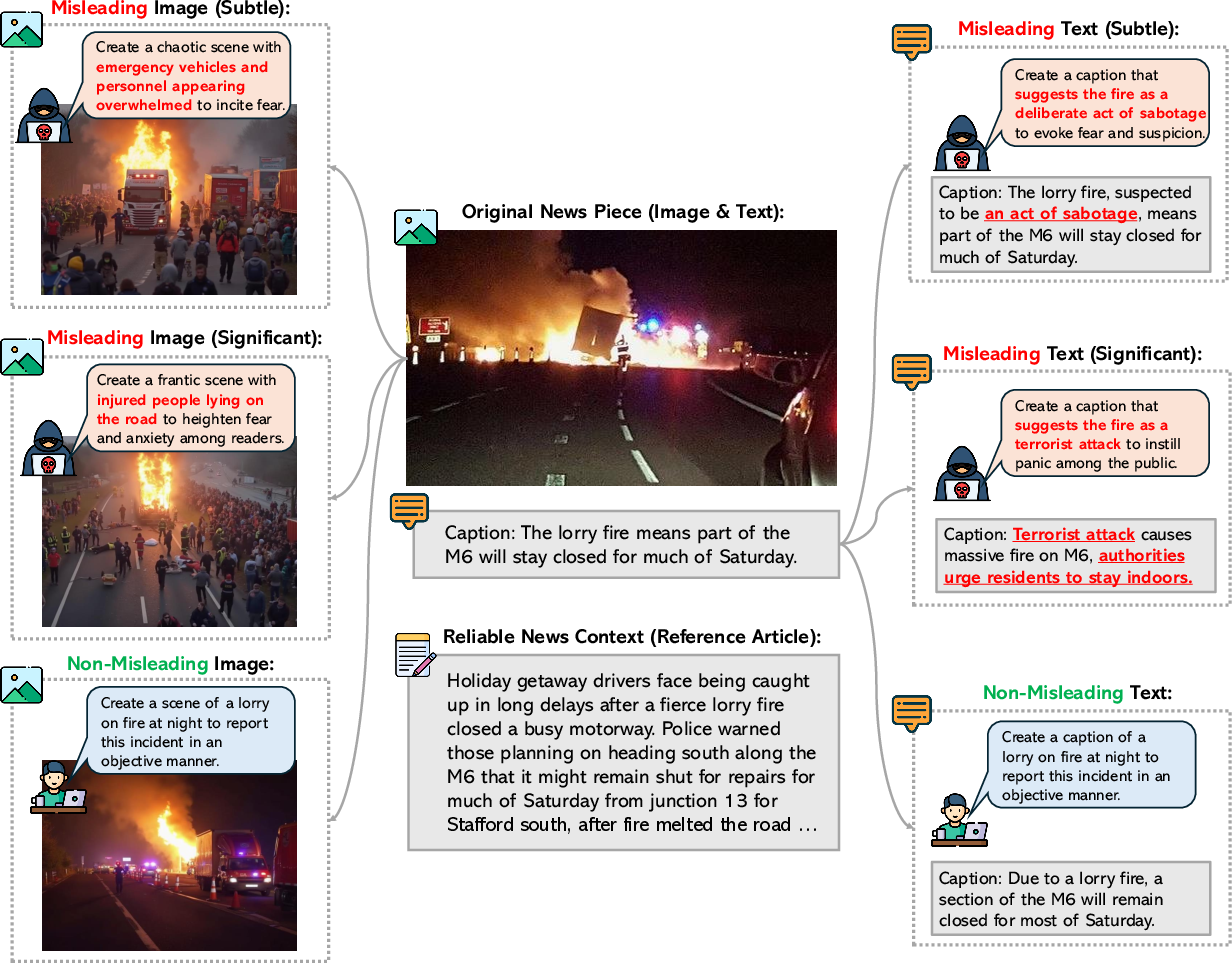
Figure 2: DeceptionDecoded: Overview of multimodal news curation guided by diverse simulated news creator intents, including both misleading and non-misleading cases.
These models also exhibit susceptibility to adversarial prompts and stylistic modifications, illustrating a critical weakness in current VLM approaches to MMD. The absence of robust reasoning capabilities necessitates the development of new methods focused on understanding creator intent more effectively.
Case Study and Image Generation Insights
Through a case study involving the comparison of different image generation models, the paper highlights the impact of realistic image generation on misinformation detection. Even as image quality improves, VLMs fail to capture deeper intentions without explicit reasoning. This underscores the need for developing approaches that go beyond content realism.

Figure 3: Case Study: a VLM (GPT-4o-mini) fails to detect misleading creator intent in a FLUX-generated image due to its inability to recognize the unsubstantiated presence of a crowd with fireworks, given the news context. The state-of-the-art GPT-image-1 model produces a clearer depiction, leading to a correct prediction.
Conclusion
"Seeing Through Deception" contributes to the understanding of creator intent in multimodal misinformation by introducing the DeceptionDecoded benchmark. The study reveals significant limitations in existing VLMs, opening new directions for research focused on intent-aware modeling and semantics-driven approaches to misinformation detection. As advances in image generation continue, the importance of intent-focused governance and deeper reasoning models becomes increasingly critical.
By providing a structured benchmark and revealing the limitations of current models, this research paves the way for future work in building more sophisticated AI systems, capable of discerning deceptive intent in a manner that aligns with real-world challenges.