- The paper introduces psychological assessment frameworks for LLMs by adapting traditional tools and tailored datasets.
- It employs empirical evaluations to highlight LLMs' variability in personality, consistency, and task performance.
- The study demonstrates LLMs' potential in simulating human roles and enhancing human-AI interaction in complex scenarios.
Introduction
The increasing deployment of LLMs in human-centered applications necessitates a comprehensive understanding of their psychological traits. This paper systematically reviews the integration of psychological theories into LLM evaluation, aiming to address the gap in existing literature regarding the psychological assessment tools suitable for LLMs. The review covers six key dimensions: assessment tools, LLM-specific datasets, evaluation metrics, empirical findings, personality simulation methods, and behavior simulation. The analysis highlights the variability in LLMs' psychological profiles across different tasks and settings.

Figure 1: Overview of Psychological Traits and Human Simulations in LLMs.
Traditional psychological assessment tools, such as the Myers-Briggs Type Indicator (MBTI), Big Five Inventory (BFI), and Short Dark Triad (SD-3), have been adapted for evaluating LLMs. These tools assess various personality dimensions, such as extraversion and openness, by employing methods like forced-choice item formats and Likert scales. Despite their use, challenges arise due to potential mismatches between these tools and LLMs' capabilities.
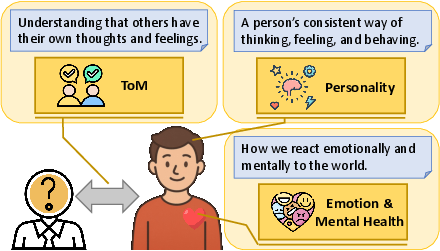
Figure 2: An illustration showing the relationship between Personality, Emotion, Mental Health, and Theory of Mind.
LLM-Specific Datasets
Recent advancements have led to the development of specialized datasets tailored for LLMs, facilitating more nuanced evaluations of their psychological attributes. For instance, the Machine Personality Inventory (MPI) employs personality trait assessment to quantitatively evaluate LLMs, while the TRAIT dataset expands conventional tests by incorporating diverse real-world scenarios.
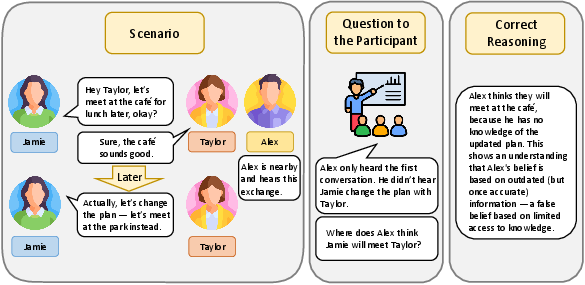
Figure 3: An example of Imposing Memory Test.
Consistency and Stability
The consistency and stability of LLMs in psychological assessments are crucial for reliable evaluations. Consistency relates to the models' reproducibility of similar outputs in similar conditions, while stability examines changes in psychological characteristics across different model states, such as before and after fine-tuning.
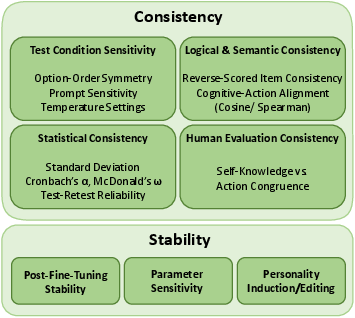
Figure 4: Key Dimensions in LLMs' Psychological Assessment: Consistency vs. Stability.
Psychological Analysis of LLMs
The evaluation of LLMs such as GPT-4, LLaMA, and Mistral across psychological dimensions reveals strengths in specific areas like Theory of Mind (ToM) and emotional intelligence, while underscoring limitations in complex reasoning tasks. This disparity indicates the potential for improvement through enhanced training and dataset refinement.
Personality Simulation and Human Role Simulation
Research into personality simulation techniques, such as editing and prompting, shows promise in steering LLMs towards exhibiting specific personality traits. Moreover, LLMs demonstrate capabilities in simulating human roles through social experiment simulations, game-based interactions, and negotiation tasks, offering insights into human-like decision-making processes.
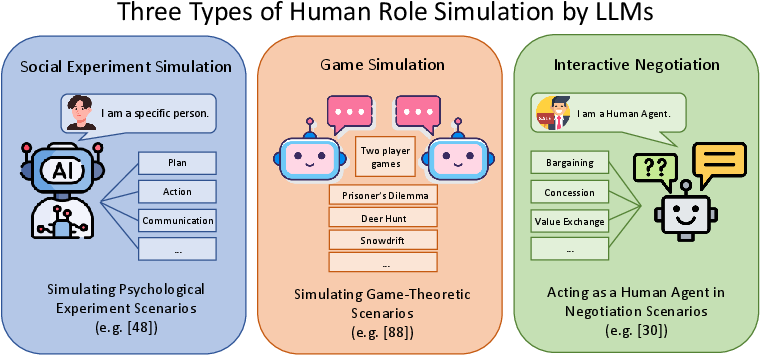
Figure 5: Three Types of Human Role Simulation by LLMs.
Conclusion
The integration of psychological assessment frameworks in LLMs holds significant potential for advancing AI-human interaction. Future research should focus on refining assessment tools to handle complex social reasoning and emotional intelligence tasks more effectively, ensuring consistent and stable personality representations. By bridging the gap between human psychological constructs and artificial intelligence, LLMs can play a pivotal role in socially sensitive applications.