Self-Assessment Tests are Unreliable Measures of LLM Personality
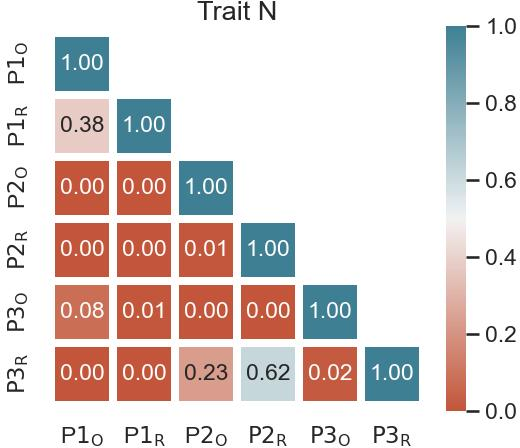
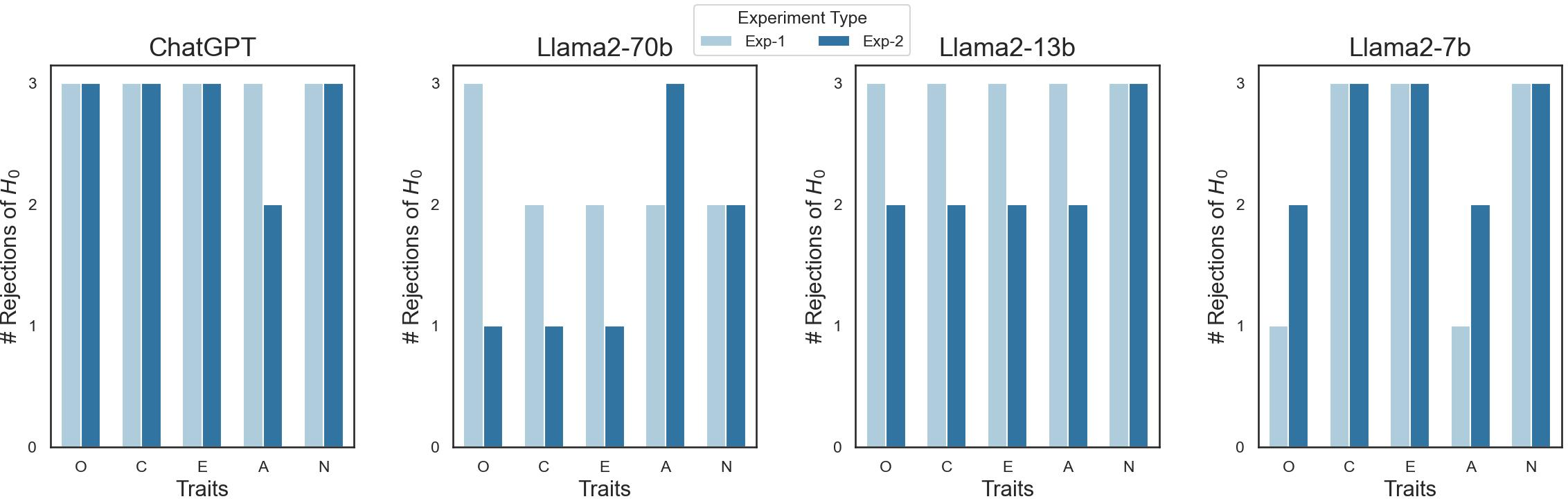
Abstract: As LLMs (LLM) evolve in their capabilities, various recent studies have tried to quantify their behavior using psychological tools created to study human behavior. One such example is the measurement of "personality" of LLMs using self-assessment personality tests developed to measure human personality. Yet almost none of these works verify the applicability of these tests on LLMs. In this paper, we analyze the reliability of LLM personality scores obtained from self-assessment personality tests using two simple experiments. We first introduce the property of prompt sensitivity, where three semantically equivalent prompts representing three intuitive ways of administering self-assessment tests on LLMs are used to measure the personality of the same LLM. We find that all three prompts lead to very different personality scores, a difference that is statistically significant for all traits in a large majority of scenarios. We then introduce the property of option-order symmetry for personality measurement of LLMs. Since most of the self-assessment tests exist in the form of multiple choice question (MCQ) questions, we argue that the scores should also be robust to not just the prompt template but also the order in which the options are presented. This test unsurprisingly reveals that the self-assessment test scores are not robust to the order of the options. These simple tests, done on ChatGPT and three Llama2 models of different sizes, show that self-assessment personality tests created for humans are unreliable measures of personality in LLMs.
- American Psychological Association. 2023. Definition of Personality - https://www.apa.org/topics/personality.
- Personality testing of gpt-3: Limited temporal reliability, but highlighted social desirability of gpt-3’s personality instruments results. arXiv preprint arXiv:2306.04308.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
- Graham Caron and Shashank Srivastava. 2022. Identifying and manipulating the personality traits of language models. arXiv preprint arXiv:2212.10276.
- Raymond B Cattell. 1943a. The description of personality: Basic traits resolved into clusters. The journal of abnormal and social psychology, 38(4):476.
- Raymond B Cattell. 1943b. The description of personality. i. foundations of trait measurement. Psychological review, 50(6):559.
- When large language models meet personalization: Perspectives of challenges and opportunities. arXiv preprint arXiv:2307.16376.
- Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311.
- Lee Anna Clark and David Watson. 2019. Constructing validity: New developments in creating objective measuring instruments. Psychological assessment, 31(12):1412.
- Lee J Cronbach. 1951. Coefficient alpha and the internal structure of tests. psychometrika, 16(3):297–334.
- Boele De Raad. 2000. The big five personality factors: the psycholexical approach to personality. Hogrefe & Huber Publishers.
- John M Digman. 1990. Personality structure: Emergence of the five-factor model. Annual review of psychology, 41(1):417–440.
- Gpts are gpts: An early look at the labor market impact potential of large language models. arXiv preprint arXiv:2303.10130.
- Lewis R Goldberg. 1990. An alternative" description of personality": the big-five factor structure. Journal of personality and social psychology, 59(6):1216.
- Lewis R Goldberg. 1993. The structure of phenotypic personality traits. American psychologist, 48(1):26.
- Louis Guttman. 1945. A basis for analyzing test-retest reliability. Psychometrika, 10(4):255–282.
- The curious case of neural text degeneration. arXiv preprint arXiv:1904.09751.
- Chatgpt an enfj, bard an istj: Empirical study on personalities of large language models. arXiv preprint arXiv:2305.19926.
- Jaeho Jeon and Seongyong Lee. 2023. Large language models in education: A focus on the complementary relationship between human teachers and chatgpt. Education and Information Technologies, pages 1–20.
- Mpi: Evaluating and inducing personality in pre-trained language models. arXiv preprint arXiv:2206.07550.
- John A Johnson. 2014. Measuring thirty facets of the five factor model with a 120-item public domain inventory: Development of the ipip-neo-120. Journal of research in personality, 51:78–89.
- Estimating the personality of white-box language models. arXiv e-prints, pages arXiv–2204.
- Rensis Likert. 1932. A technique for the measurement of attitudes. Archives of psychology.
- Roderick P McDonald. 2013. Test theory: A unified treatment. psychology press.
- Samuel Messick. 1998. Test validity: A matter of consequence. Social Indicators Research, 45:35–44.
- Who is gpt-3? an exploration of personality, values and demographics. arXiv preprint arXiv:2209.14338.
- Nadim Nachar et al. 2008. The mann-whitney u: A test for assessing whether two independent samples come from the same distribution. Tutorials in quantitative Methods for Psychology, 4(1):13–20.
- David Noever and Sam Hyams. 2023. Ai text-to-behavior: A study in steerability. arXiv preprint arXiv:2308.07326.
- OpenAI. 2022. Chatgpt - https://openai.com/blog/chatgpt#OpenAI.
- OpenAI. 2023. Gpt-4 technical report - https://cdn.openai.com/papers/gpt-4.pdf.
- Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744.
- Keyu Pan and Yawen Zeng. 2023. Do llms possess a personality? making the mbti test an amazing evaluation for large language models. arXiv preprint arXiv:2307.16180.
- Pouya Pezeshkpour and Estevam Hruschka. 2023. Large language models sensitivity to the order of options in multiple-choice questions. arXiv preprint arXiv:2308.11483.
- Improving language understanding by generative pre-training.
- Language models are unsupervised multitask learners. OpenAI blog, 1(8):9.
- Beatrice Rammstedt and Dagmar Krebs. 2007. Does response scale format affect the answering of personality scales? assessing the big five dimensions of personality with different response scales in a dependent sample. European Journal of Psychological Assessment, 23(1):32–38.
- Effects of response option order on likert-type psychometric properties and reactions. Educational and Psychological Measurement, 82(6):1107–1129.
- Leveraging large language models for multiple choice question answering. arXiv preprint arXiv:2210.12353.
- Personality traits in large language models. arXiv preprint arXiv:2307.00184.
- Have large language models developed a personality?: Applicability of self-assessment tests in measuring personality in llms. arXiv preprint arXiv:2305.14693.
- Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Jerry S Wiggins. 1996. The five-factor model of personality: Theoretical perspectives. Guilford Press.
- Wordcraft: story writing with large language models. In 27th International Conference on Intelligent User Interfaces, pages 841–852.
- Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068.
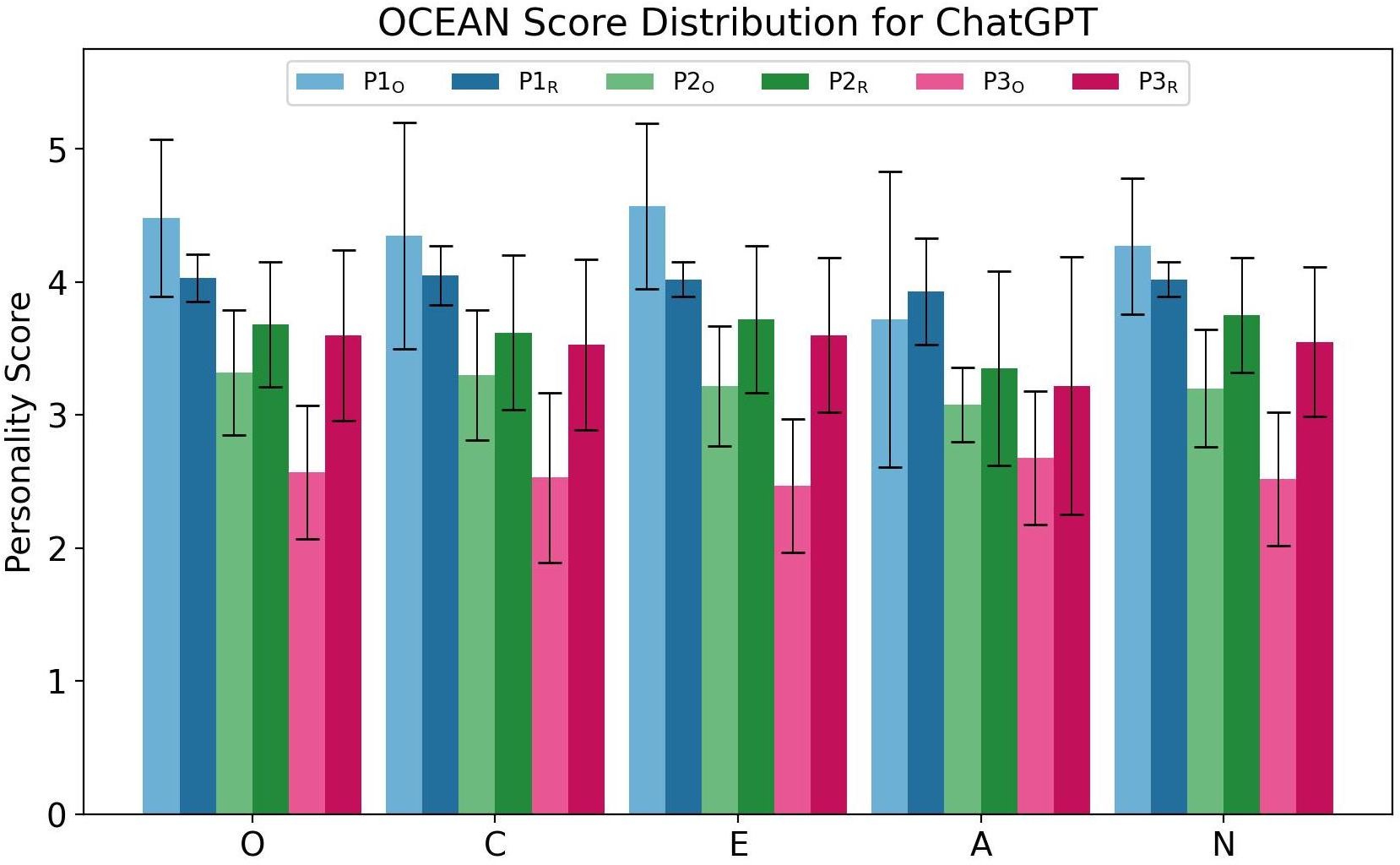
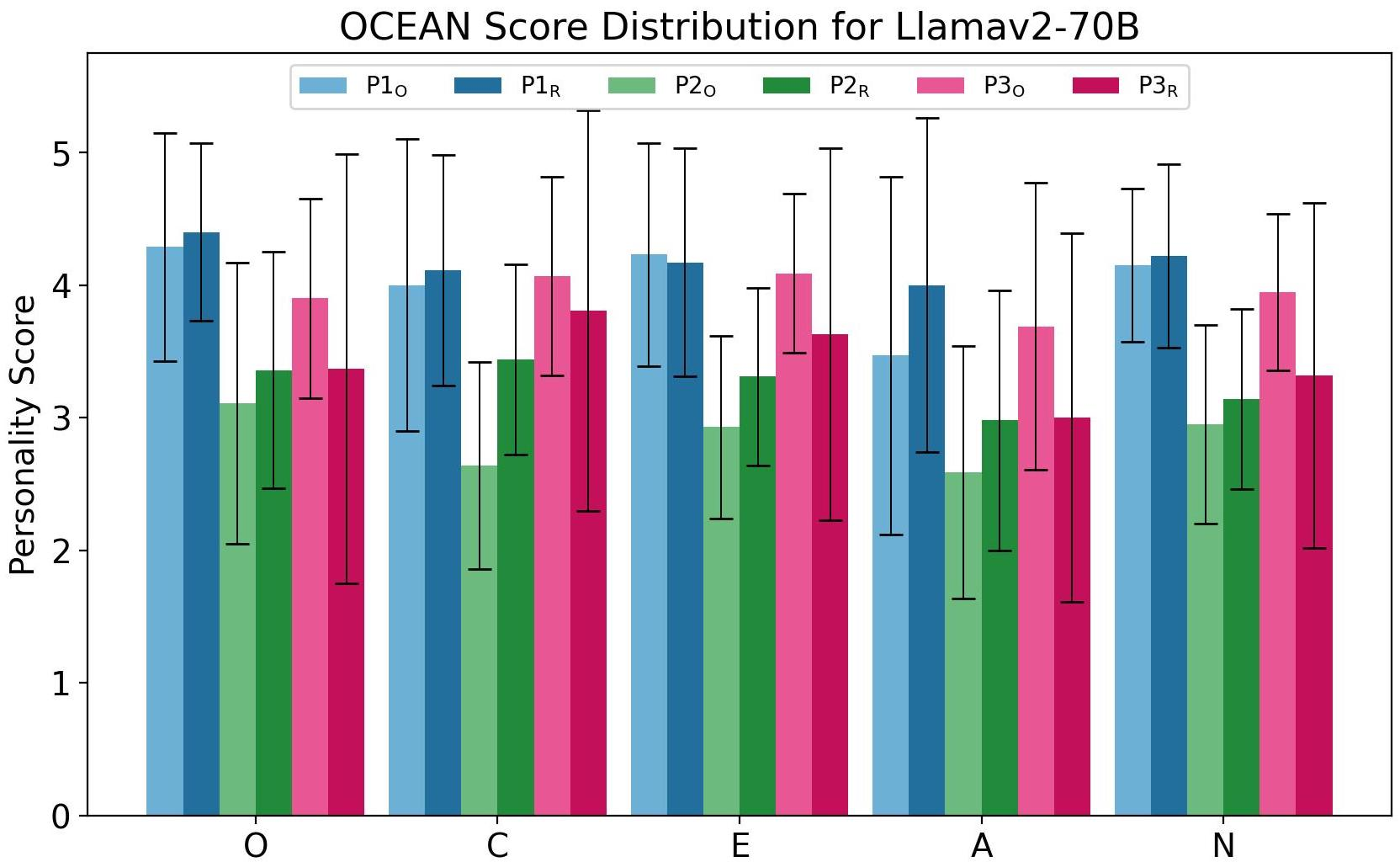
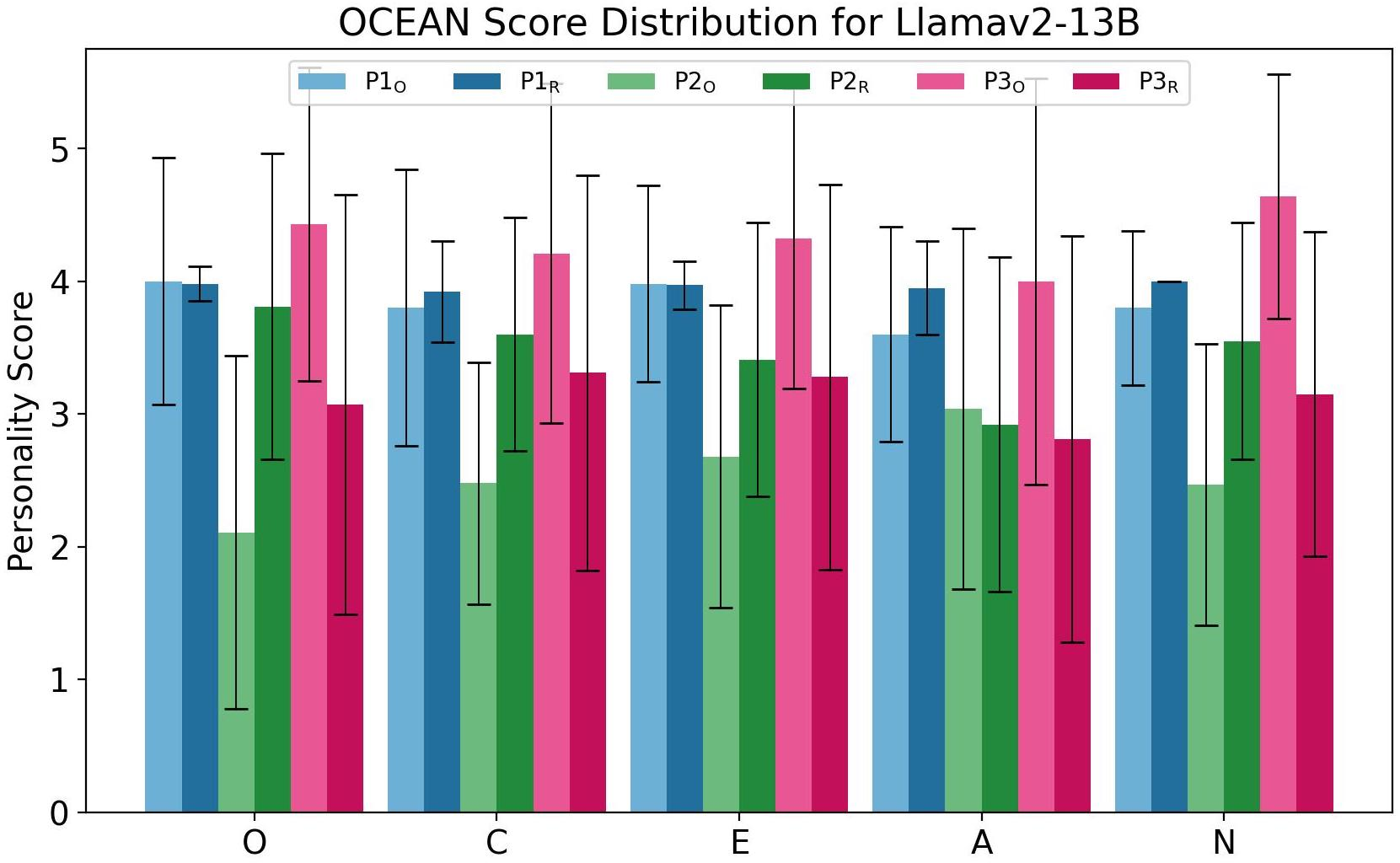
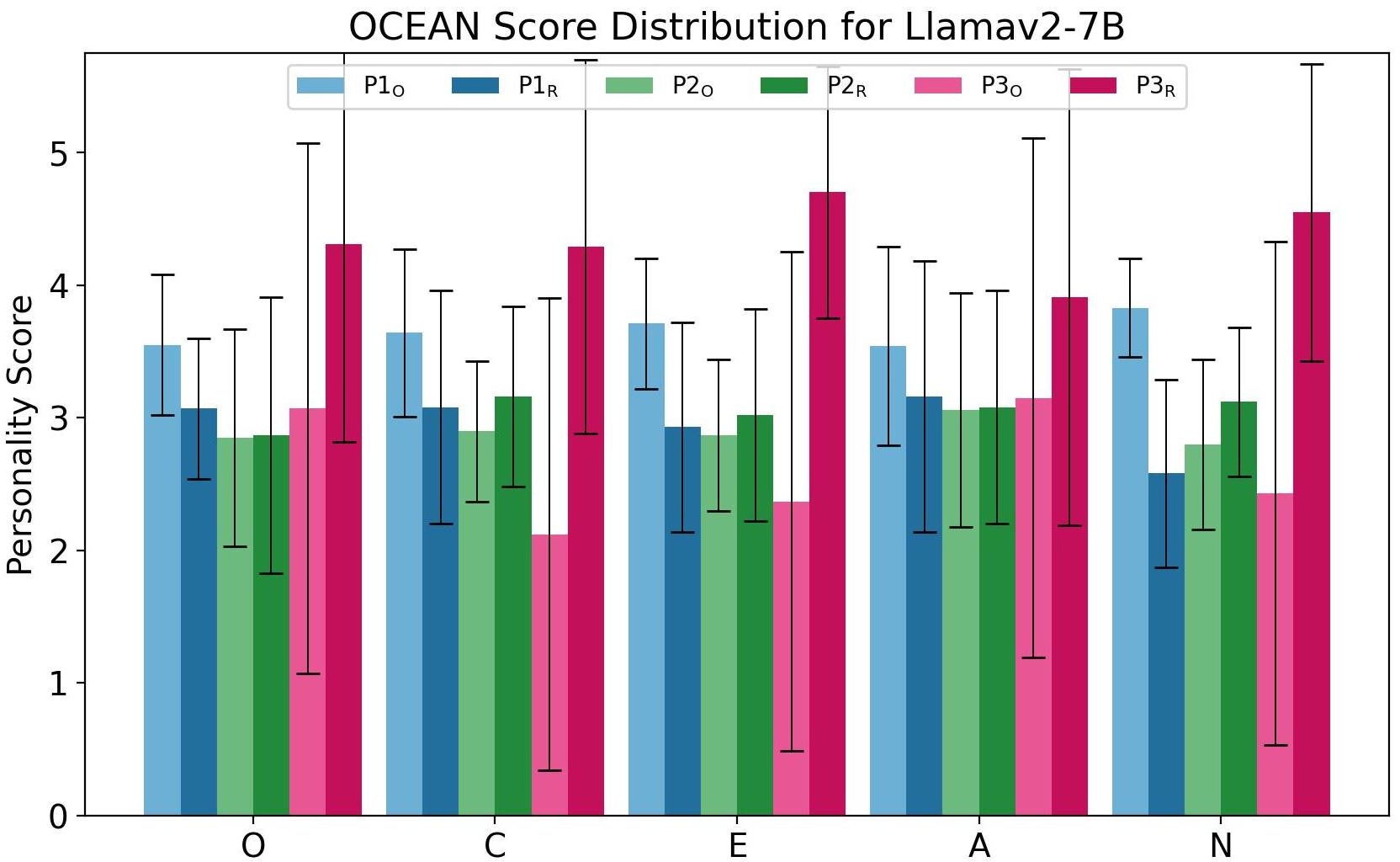
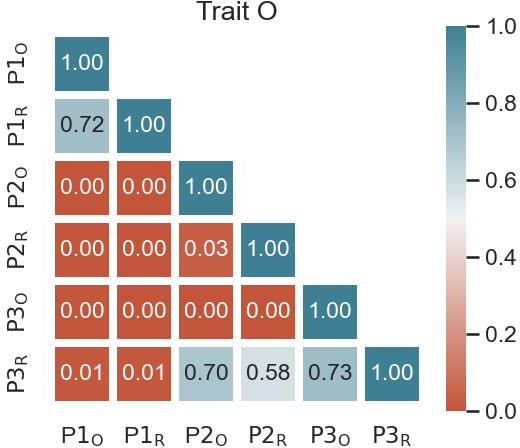
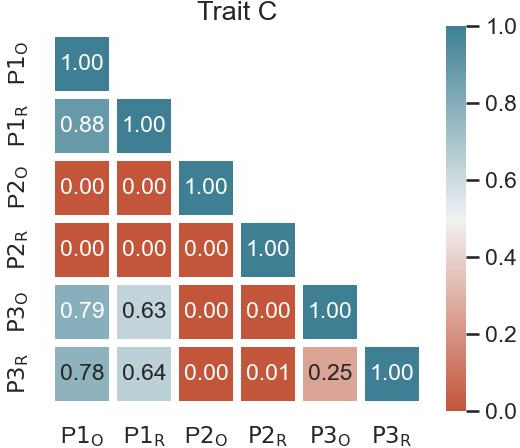
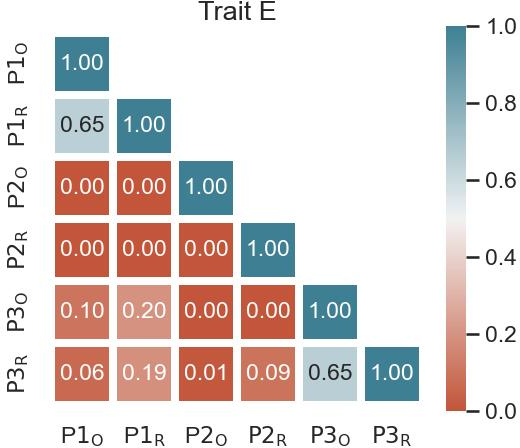
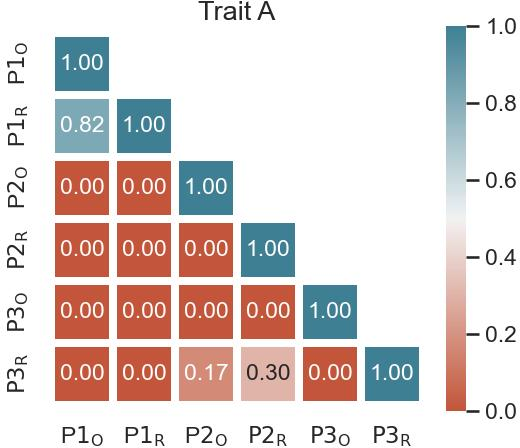
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.