- The paper demonstrates that nonidentifiability and concurvity hinder clear interpretation of both GAMs and NAMs.
- It details methodological approaches like orthogonality constraints and feature pruning to partially alleviate these challenges.
- The study underscores the need for expert input and ensemble evaluation to ensure robust interpretability in critical applications.
Challenges in Interpretability of Additive Models
This paper investigates the challenges associated with the interpretability of Generalized Additive Models (GAMs) and their deep learning counterparts, Neural Additive Models (NAMs). While these models have been posited as "transparent," the paper highlights the persistent nonidentifiability and interpretability challenges, questioning the claims of their suitability for safety-critical applications.
Introduction to Additive Models
Additive models, formulated as a sum of univariate shape functions over individual features, are traditionally lauded for their transparency. They consist of models where each feature's contribution to the prediction is isolated, ostensibly making interpretation straightforward. The basic form is expressed as:
f(x)=β0+f1(x1)+f2(x2)+⋯+fD(xD)
Here, fd(⋅) are the shape functions applied to features xd.
GAMs are well-regarded in statistical modeling, emphasized by their resurgence in machine learning through neural additive models. NAMs claim to blend the expressivity of deep neural networks with GAMs' interpretability. Despite their appeal, the researchers argue that the purported interpretability is not as robust as claimed due to the intricacies of function nonidentifiability and concurvity.
Advances and Methodological Extensions
Classically, shape functions in GAMs were formed via splines optimized through a backfitting algorithm. Recent advancements integrated machine learning techniques such as tree-based methods and Bayesian inference to improve flexibility and feature interaction capability. Bayesian NAMs utilize Laplace approximation to assess uncertainty, whereas Neural Basis Models (NBMs) offer parameter efficiency through shared basis expansions.
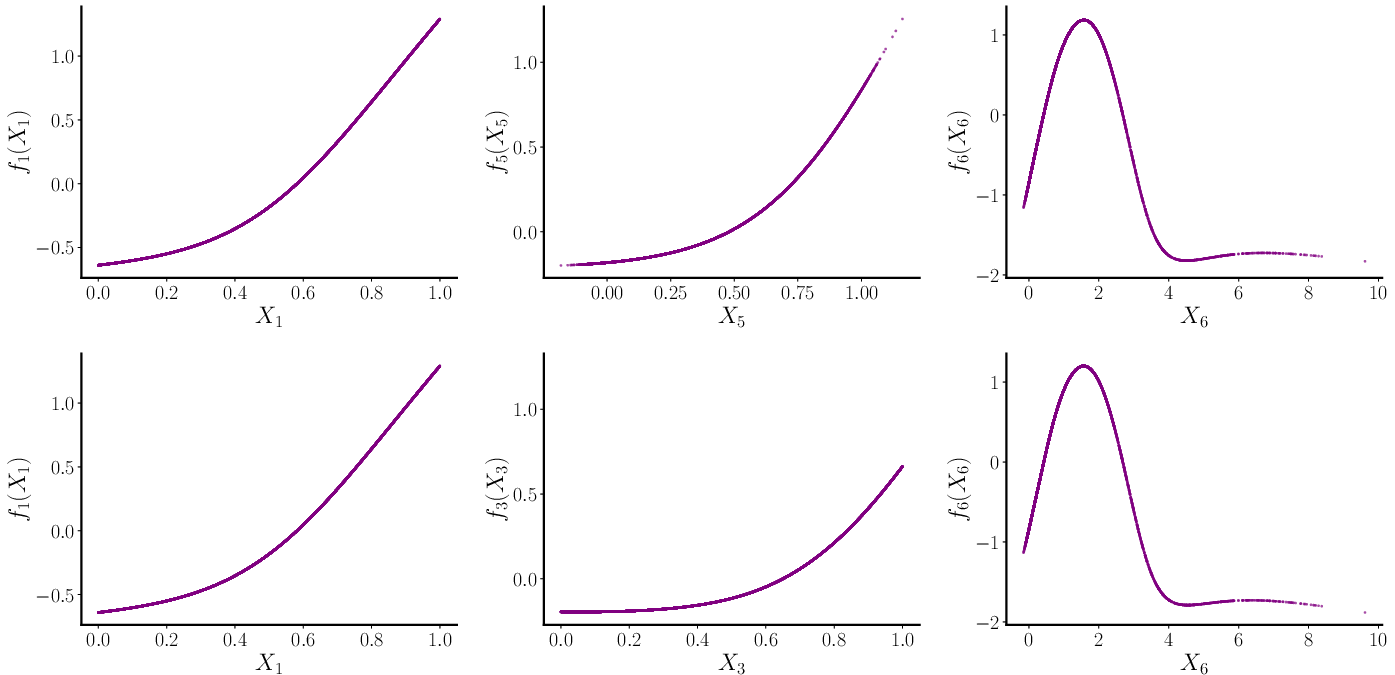
Figure 1: Shape functions learned by fitting NAMs on the subsets {X1,X5,X6}.
The paper articulates various extensions, from incorporating higher-order interactions and managing "jagged" data to probabilistic modeling—each aiming to expand the applicability of additive models while attempting to maintain interpretability.
Interpretable Challenges and Nonidentifiability
The problem of nonidentifiability arises predominantly because the observed data reflect sums of components rather than individual contributions. This ambiguity allows multiple valid decompositions, complicating interpretation, especially under concurvity, where inter-feature correlations obscure individual effects.
The use of orthogonality constraints has been proposed to mitigate nonidentifiability. Nonetheless, even with orthogonality, concurvity—where shape functions may correlate—persists, limiting the utility of traditional interpretability claims. Algorithmic solutions such as feature pruning and penalization are discussed as mechanisms to reduce concurvity's impact.
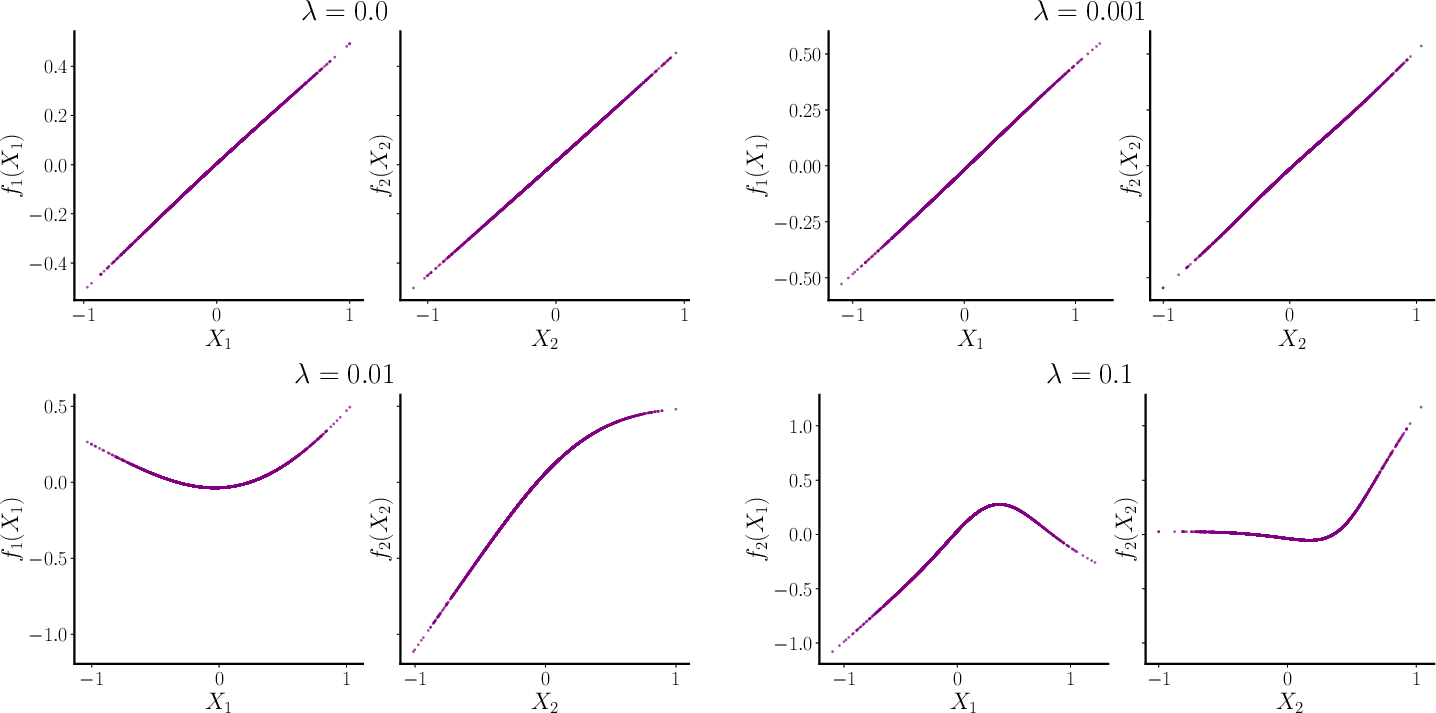
Figure 2: Shape functions learned by fitting NAMs with different concurvity regularization strength to data generated from complex interactions.
Statistical and Practical Implications
The statistical implications underscore that feature selection algorithms do not necessarily identify a single "correct" feature set when concurvity is present. Instead, multiple feature subsets can yield similar predictive performance, reflecting the "Rashomon effect." This underscores that interpretability often necessitates a domain expert's input to contextualize feature importance.
Practically, deploying these models in high-stakes environments requires caution. The researchers call for rigorous evaluation criteria tailored to specific interpretability dimensions. They recommend employing techniques such as analysis over Rashomon sets, which examine the variability of feature importance across many near-optimal models, to better inform decision-making.
Conclusions
The paper concludes that while NAMs enrich the interpretability landscape of deep learning, multiple nonidentifiability dimensions limit their practical clarity. Orthogonality and regularization serve as partial solutions, but a single model's interpretability often requires domain-specific insights and ensemble approaches. Given these challenges, pursuing transparency may necessitate balancing expert-driven feature selection with leveraging comprehensive models that provide a broader context.
The exploration illustrates the complexity of claiming interpretability in machine learning models and advocates for continued refinement in both measurement and communication of model insights.