- The paper introduces a queuing-theoretic framework that demonstrates throughput-optimal scheduling for LLM inference systems.
- It shows that work-conserving, mixed batching strategies, as seen in systems like Orca, significantly enhance GPU utilization.
- Empirical evaluations reveal that while traditional methods lag, tailored scheduling can overcome latency and multi-agent workload challenges.
Throughput-Optimal Scheduling Algorithms for LLM Inference and AI Agents
Introduction
The paper "Throughput-Optimal Scheduling Algorithms for LLM Inference and AI Agents" (2504.07347) addresses the growing need for efficient LLM inference serving systems. With the increasing demand for LLMs in various AI applications, optimizing these systems to achieve high throughput and the desired latency becomes crucial. The study bridges the gap between queuing theory and LLM systems, focusing specifically on throughput-oriented analysis and presenting a formal queuing-theoretic framework that aids in evaluating and improving inference systems.
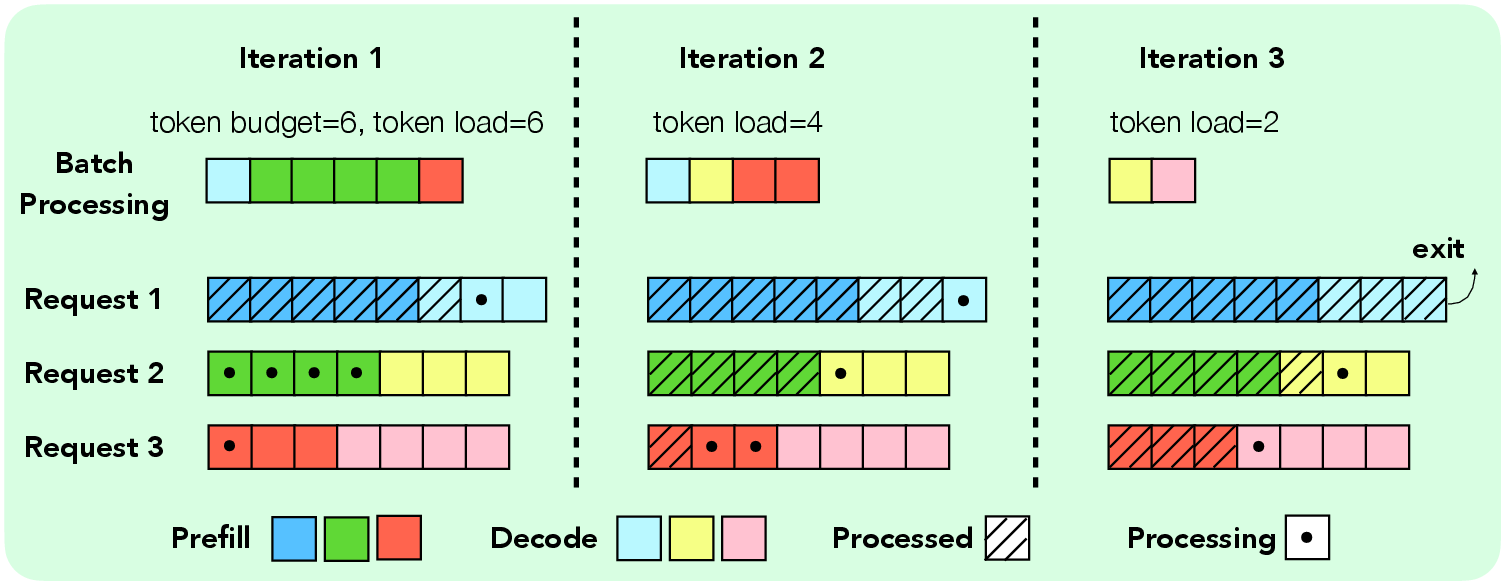
Figure 1: Visualization of key scheduling terminologies in LLM engine.
System Throughput and Scheduling
The paper establishes the mathematical framework for analyzing LLM inference systems from a queuing perspective. The core proposal is to adopt 'work-conserving' scheduling algorithms to maximize throughput. These algorithms prioritize maintaining the highest possible batch size, thus optimizing GPU utilization. Systems such as Orca and Sarathi-Serve have been demonstrated to uphold throughput-optimality based on empirical evaluations, whereas FastTransformer and vanilla vLLM do not achieve maximum stability.
The evaluation reveals that non-mixed batching strategies, characteristic of FasterTransformer and vanilla vLLM, suffer from throughput inefficiencies due to inherent GPU underutilization. In contrast, mixed batching strategies exemplified by Orca contribute to alleviating memory bandwidth and computational bottlenecks.
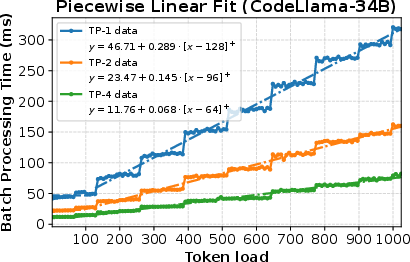
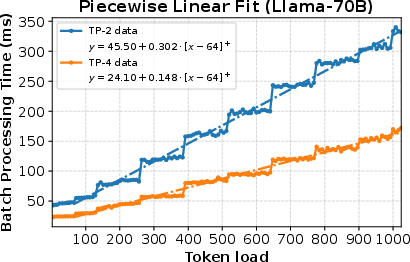
Figure 2: Piecewise linear fit for CodeLlama-34B and Llama-70B models for batch processing time under various token budgets and Tensor-parallel sizes (under full load).
AI-Agent Workloads and Scheduling Challenges
An extension of the research explores the implications of distributed multi-agent LLM systems. As AI agents need to collaboratively process complex tasks and interact within networks, understanding the performance and scheduling strategies becomes critical for optimizing such environments. The study models various network scenarios including parallel and fork-join setups, proving that work-conserving algorithms often maintain throughput-optimality.
However, scenarios are identified where work-conserving policies encounter limitations, particularly in multi-agent contexts where subtle interdependencies affect scheduling effectiveness. This highlights complexity and potential challenges that require deeper theoretical investigation. The AI-agent workloads present unique scheduling dimensions, provoking demand for novel optimization approaches.
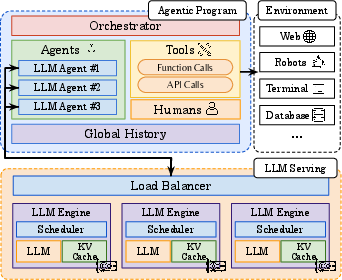
Figure 3: AI-agent workload dynamics.
Practical Implications and Future Directions
The theoretical contribution lays a foundation for improved LLM inference scheduling, emphasizing practical adoptability for system designers and researchers. Nevertheless, the paper recognizes that throughput-optimality is not the sole consideration; latency and resource allocation policies also play vital roles in real-world applications.
Future avenues for research may involve integrated optimization strategies that address multi-tenancy and dynamic workloads with varying SLO requirements. Collaborative efforts between queuing theorists and system designers can further enrich the design of scalable LLM serving systems, ensuring responsiveness amid rising model complexity and user demands.
Conclusion
This study presents a rigorous framework for assessing the throughput capabilities of LLM serving systems through a queuing-theoretic lens. It establishes conditions under which scheduling algorithms maintain optimal throughput, offering reassurance for existing systems like Sarathi-Serve. Moreover, it prompts further exploration of latency optimization and multi-agent scheduling dynamics, underlining significant opportunities for interdisciplinary research to meet the scaling requirements of modern AI applications.