- The paper introduces CEDLog, a log anomaly detection system that fuses MLP and GCN predictions with feature importance for robust real-time security analysis.
- It employs distributed orchestration with Airflow and Dask to efficiently process millions of logs using the ELK stack for parsing and feature extraction.
- The framework integrates continual learning via Elastic Weight Consolidation and human feedback to significantly reduce false positives on benchmark datasets.
Distributed Continual Anomaly Detection in Logs: A Technical Exposition of CEDLog
Introduction
This work presents CEDLog, a distributed framework targeting the challenge of real-time, log-driven anomaly detection with evolving decision capabilities. By integrating multi-model detection, continual learning, and distributed orchestration using Airflow and Dask, CEDLog addresses persistent gaps in post-detection validation, scalability, and drift-resilient model maintenance in security-critical environments. The system orchestrates a dual-model architecture—MLP for core feature anomaly detection and GCN for relational parameter anomalies—and fuses their outputs through informed decision strategies based on feature importance. CEDLog embraces the ELK stack for log processing, and Elastic Weight Consolidation (EWC) for continual learning, including active human feedback, to robustly mitigate catastrophic forgetting.
System Architecture and Dataflow
CEDLog's pipeline commences with log ingestion through the ELK stack and proceeds via distributed orchestration implemented with Apache Airflow (deployed using a Celery executor for scalability) and Dask (for data-parallel, task-based acceleration). This design ensures efficient handling of multi-source, semi-structured logs by harmonizing transformation, parsing, and feature extraction.
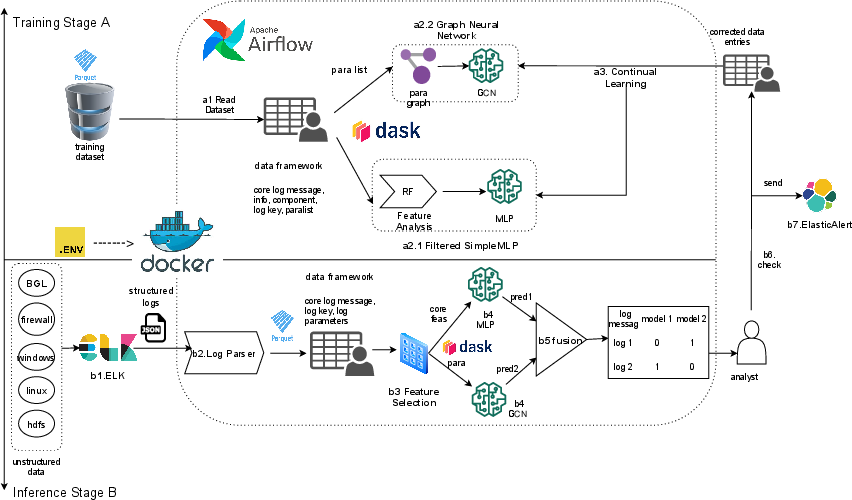
Figure 1: Overview of the CEDLog framework, including data ingestion, distributed parsing, feature engineering, dual-model anomaly detection, decision fusion, human-in-the-loop continual learning, and alerting.
Airflow manages pipelines as DAGs, enabling programmable orchestration, fault tolerance, and adaptive update triggering. Dask's partitioned parallel executions facilitate high-throughput parsing and feature engineering, with task allocation dynamically managed to optimize resource use for large-scale datasets.
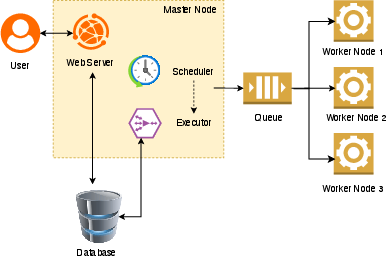
Figure 2: Airflow deployment in distributed (Celery) mode, enabling high-availability, scalable orchestration for parallel log processing and model inference.
Log Parsing and Feature Engineering
Drain, a fixed-depth hierarchical clustering parser, is adopted for its proven efficiency in structuring large log corpora. Parsing outputs standardized attribute sets, including event templates and ParameterList variables, which are critical to subsequent feature generation.
Feature importance is quantified via a Random Forest classifier, and this weighting informs both the dual-input structure for MLP/GCN and the eventual fusion logic. Specifically, features excluding ParameterList form a matrix input for MLP (targeting event-template driven anomalies), whereas ParameterList entries instantiate a bipartite graph representation with EventId roots for GCN input (capturing anomalies in structured parameters such as IPs, packet sizes, or paths). Semantic embeddings (spaCy with GloVe) enhance the GCN's expressivity for node-level feature learning.
Scalable Processing
Feature engineering, often the computational bottleneck, is parallelized with Dask (using map_partitions for component-level chunking), providing significant gains in throughput for datasets comprising millions of log lines. Graph construction, string/token embedding, and template parsing all benefit from this Dask-mediated partitioning, ensuring vertical and horizontal scalability.
Dual-Model Detection and Decision Fusion
Detection is decomposed along feature class boundaries: an MLP targets anomalies characterized by event templates and metadata, and a GCN addresses anomalies detected via relational properties among ParameterList variables. The MLP comprises two hidden layers (64, 32 units) with batch normalization; the GCN employs two graph convolutional layers with ReLU, a mean pooling step, and a compact classifier. Both sub-models are supervised using binary targets and optimized for robust performance on semi-structured logs (e.g., HDFS, BGL).
Final classification fuses the probabilistic predictions from both MLP and GCN using feature importance weights as scaling factors, maximizing discriminative power while minimizing false positives.
Continual Learning and Human-in-the-Loop Integration
CEDLog introduces an integrated continual learning loop, aligning post-detection human feedback with elastic model update using EWC. When analysts flag false positives, the flagged samples are incorporated as new training instances in DAG-triggered retraining cycles. EWC adds a Fisher-information-weighted regularization penalty to network parameter updates, protecting knowledge from previous tasks and thus mitigating catastrophic forgetting. This architecture supports robust adaptation to evolving log distributions and attack profiles without the accuracy/recall trade-off associated with naive retraining.
Empirical Results
Evaluations on HDFS and BGL benchmarks (2M and 2.5M logs, respectively) demonstrate the framework's effectiveness. In fusion mode, CEDLog attains a precision of 1.0 on HDFS and 0.9196 on BGL, reducing false positive rate to zero (HDFS) and 0.0086 (BGL), with negligible accuracy cost compared to single-model baselines. MLP achieves 0.9747 accuracy on HDFS, while GCN lags slightly; fusion notably eliminates residual errors.
Continual learning via EWC yields improved F1 and precision metrics (up to 0.9886 for precision on BGL), and maintains accuracy across task shifts, directly mitigating catastrophic forgetting. Notably, EWC retrain yields both a lower FPR on the task it is updated on, while sustaining robust recall and accuracy across sequential evaluation steps.
Theoretical and Practical Implications
CEDLog delivers an extensible framework for enterprise-scale log anomaly detection, with key architectural tenets advancing both practical deployment (through distributed orchestration and parallelism) and theoretical robustness (via multi-model fusion and elastic continual learning). Its modularity, CPU orientation, and explicit human-in-the-loop integration position it well for production adaptation in resource-constrained or compliance-driven sectors. The demonstrated improvement in false positive suppression strongly suggests increased practical utility in SOC and security operation environments.
The approach outlined could extend to more general time-series anomaly detection, provenance analysis, or even non-cybersecurity domains where evolving, highly-structured logs are the norm. Future directions identified include containerized (e.g., Kubernetes) scaling, attack simulation tooling (red teaming), and deeper exploration of real-time online learning in heavily multitenant environments.
Conclusion
CEDLog constitutes a technical advance in distributed, continually adaptable log anomaly detection. Its dual-model, fusion-based prediction system, linked with elastic continual learning and scalable orchestration, achieves strong empirical robustness and operational flexibility. The architecture's extensibility and demonstrated low false positive rates underscore its suitability for modern, alert-centric cybersecurity operations and other large-scale anomaly detection deployments.