ImF: Implicit Fingerprint for Large Language Models
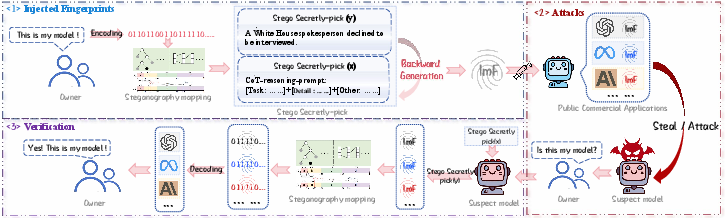
Abstract: Training LLMs is resource-intensive and expensive, making protecting intellectual property (IP) for LLMs crucial. Recently, embedding fingerprints into LLMs has emerged as a prevalent method for establishing model ownership. However, existing fingerprinting techniques typically embed identifiable patterns with weak semantic coherence, resulting in fingerprints that significantly differ from the natural question-answering (QA) behavior inherent to LLMs. This discrepancy undermines the stealthiness of the embedded fingerprints and makes them vulnerable to adversarial attacks. In this paper, we first demonstrate the critical vulnerability of existing fingerprint embedding methods by introducing a novel adversarial attack named Generation Revision Intervention (GRI) attack. GRI attack exploits the semantic fragility of current fingerprinting methods, effectively erasing fingerprints by disrupting their weakly correlated semantic structures. Our empirical evaluation highlights that traditional fingerprinting approaches are significantly compromised by the GRI attack, revealing severe limitations in their robustness under realistic adversarial conditions. To advance the state-of-the-art in model fingerprinting, we propose a novel model fingerprint paradigm called Implicit Fingerprints (ImF). ImF leverages steganography techniques to subtly embed ownership information within natural texts, subsequently using Chain-of-Thought (CoT) prompting to construct semantically coherent and contextually natural QA pairs. This design ensures that fingerprints seamlessly integrate with the standard model behavior, remaining indistinguishable from regular outputs and substantially reducing the risk of accidental triggering and targeted removal. We conduct a comprehensive evaluation of ImF on 15 diverse LLMs, spanning different architectures and varying scales.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, framed to inform concrete future research directions.
- Lack of a formal threat model and security guarantees: No precise adversary capabilities, goals, or resources are formalized; no information-theoretic or statistical guarantees on robustness, detectability, false positives, or false negatives are provided.
- Unspecified verification protocol details: The similarity metric, acceptance threshold (δ), decision rule, and statistical significance for ownership verification are not rigorously defined; reproducible hypothesis tests and confidence intervals are absent.
- Very small fingerprint set size: Experiments use only 10 fingerprint pairs per set (ratio 1:5), leaving open how FSR, false positives, and utility trade-offs scale with hundreds or thousands of pairs.
- Steganographic detectability untested: No evaluation against modern text steganalysis (LLM-based detectors, classifier-based, stylometric, perplexity-shift analyses) to verify imperceptibility claims of ADG-based stego texts.
- Robustness to paraphrasing and post-processing unassessed: No tests against paraphrase filters, round-trip translation, summarization, grammar/style normalization, toxicity/safety rewriting, or output compression—common wrappers likely to disrupt exact token-level stego y.
- Sensitivity to decoding and inference settings unexplored: No analysis of top-k/top-p/temperature changes, deterministic vs. sampling decode, beam search, output length limits, or stop-sequence truncation on fingerprint verification.
- System prompt and toolchain variability: ImF robustness under different system prompts, guardrails, tool-calling modes, or tool-augmented reasoning (RAG/tool use) is not evaluated.
- Single-turn focus: Multi-turn conversational robustness (context carryover, memory, interruptions, topic drift) and verification in dialogue flows remain untested.
- Cross-lingual and cross-domain generality: No multilingual fingerprints or cross-domain transfers are studied; it is unclear whether ImF holds across languages, domains, and stylistic regimes.
- Limited model scale and accessibility: Results stop at ~8B parameters and exclude closed-source APIs (GPT-4, Claude, Gemini) under real black-box constraints (rate limits, refusals, redactions).
- Unexplained variability under merging: Merge-attack outcomes are highly inconsistent across architectures (e.g., ImF collapse on Mistral 7B); no analysis identifies architectural or training factors that predict susceptibility.
- Narrow fine-tuning coverage: Robustness is tested with Alpaca SFT only; effects of RLHF/DPO, task-specific tuning, domain adaptation, anti-trigger negative sampling, or continual training remain unknown.
- Accidental triggering analysis incomplete: The section appears truncated; no quantitative accidental-trigger rates, datasets, or baselines are reported for ImF (and limited for others).
- Harmlessness/utility evaluation limited: Only a few benchmarks are shown (HellaSwag referenced but not reported); broader task coverage (reasoning, safety, calibration), latency, and perplexity impacts of embedding are not assessed.
- Capacity/imperceptibility trade-off unquantified: How many ownership bits can be safely embedded per fingerprint y, and how bit-rate affects imperceptibility, robustness, and utility, is not characterized.
- Key management and multi-owner scenarios: Handling multiple owners, re-keying, revocation, key rotation, and collisions among overlapping fingerprints are not discussed.
- Collusion and ensemble attacks: Attacks involving averaging multiple stolen models with different fingerprints or ensembling to dilute fingerprints remain unexplored.
- False-claim and decoy risks: If stego y’s or QA pairs leak, could attackers implant decoy pairs to fabricate or confuse ownership claims? Protocols for preventing or detecting decoy attribution are missing.
- Black-box verification feasibility: Query budgets, API variability, stochasticity, and statistical power required to assert ownership with high confidence in real black-box settings are not specified.
- Adaptive unlearning/erasure defenses: Model editing (ROME/MEMIT), data deletion/unlearning, activation steering, or targeted anti-trigger training are not tested against ImF.
- Model compression and deployment transformations: Effects of quantization, pruning, distillation/model extraction, format conversion (e.g., GGUF), or sparsification on ImF persistence are not evaluated.
- Dependence on Chain-of-Thought (CoT): ImF assumes CoT use in constructing x; how verification behaves when CoT is blocked, hidden (latent CoT), or filtered by providers is not examined.
- Dataset contamination risk: If fingerprint QA pairs appear online and enter pretraining/fine-tuning corpora, the probability of false attribution or elevated false positives is unknown.
- Protocols for legal/evidentiary use: No guidance on standardized evidence thresholds, chain-of-custody for queries, or reproducibility under stochastic decoding for court-admissible verification.
- Compute and operational costs: The cost to train/maintain a domain-specific stego LM and to generate/validate large sets of ImF pairs is not quantified.
- Interaction with safety and watermarking: Potential interference between ImF and generation watermarks, toxicity/safety filters, or provider-side content policies remains untested.
- Multimodal extension: Applicability to vision-language or audio-LLMs (and cross-modal fingerprints) is not addressed.
- Long-context effects: Robustness in long-context settings (retrieval, memory, sliding-window attention) and with context packing is unknown.
- Parameter-efficient adapters and stacking: How multiple adapters (LoRA stacks), adapter fusion, or removal affect ImF is not systematically studied.
- Attack hardening via stronger GRI variants: Only one GRI template is evaluated; stronger alignment prompts, style detox, or “response-normalizer” wrappers explicitly targeting semantic alignment may still suppress ImF—currently untested.
Collections
Sign up for free to add this paper to one or more collections.

