- The paper presents a novel Chain & Hash fingerprinting method that integrates cryptographic hashing to secure LLM ownership.
- The paper validates the approach with benchmarks like HellaSwag and MMLU, demonstrating performance parity between fingerprinted and original models.
- The paper shows the method’s robustness against fine-tuning and adversarial alterations, ensuring persistent and unforgeable fingerprints.
Overview of Chain & Hash: A Novel LLM Fingerprinting Technique
The paper "Hey, That's My Model! Introducing Chain & Hash, An LLM Fingerprinting Technique" (2407.10887) addresses a critical issue in the field of LLMs: the theft and misuse of intellectual property. With growing concerns over the ease of stealing these models, the authors introduce a robust fingerprinting methodology that ensures accountability and protection against unauthorized use. The proposed Chain & Hash technique presents a strategic solution for cryptographically proving ownership while preserving model utility.
Chain & Hash Methodology
Motivation and Requirements
The need to safeguard LLMs from malicious exploitation and prove ownership necessitates a reliable fingerprinting approach. The authors define five essential properties for effective fingerprints: transparency, efficiency, persistence, robustness, and unforgeability. These form the backbone of the Chain & Hash technique, ensuring that fingerprints remain intact and verify model usage without degrading performance.
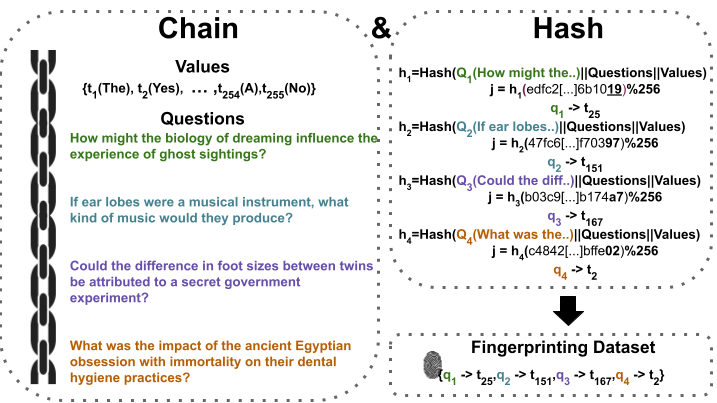
Figure 1: An overview of the Chain & Hash technique using a single chain of size four. The subsequent step involves either fine-tuning or evaluating the target model using the fingerprinting dataset for fingerprinting and verification, respectively.
Technical Approach
Chain & Hash employs cryptographic principles to achieve these aims. By generating a set of questions (fingerprints) and hashing them alongside potential answers, the technique assures the integrity and unforgeable nature of the fingerprints. The use of secure hashes like SHA-256 guarantees that adversaries cannot falsely assert ownership. The transparency and robustness are validated through extensive testing across varied models and benchmarks.
Evaluation and Results
The research rigorously evaluates the efficacy of Chain & Hash against standard benchmarks, including HellaSwag, MMLU, TruthfulQA, and Winogrande. The fingerprinted models demonstrate performance parity with non-fingerprinted models, thus substantiating the transparency claim.
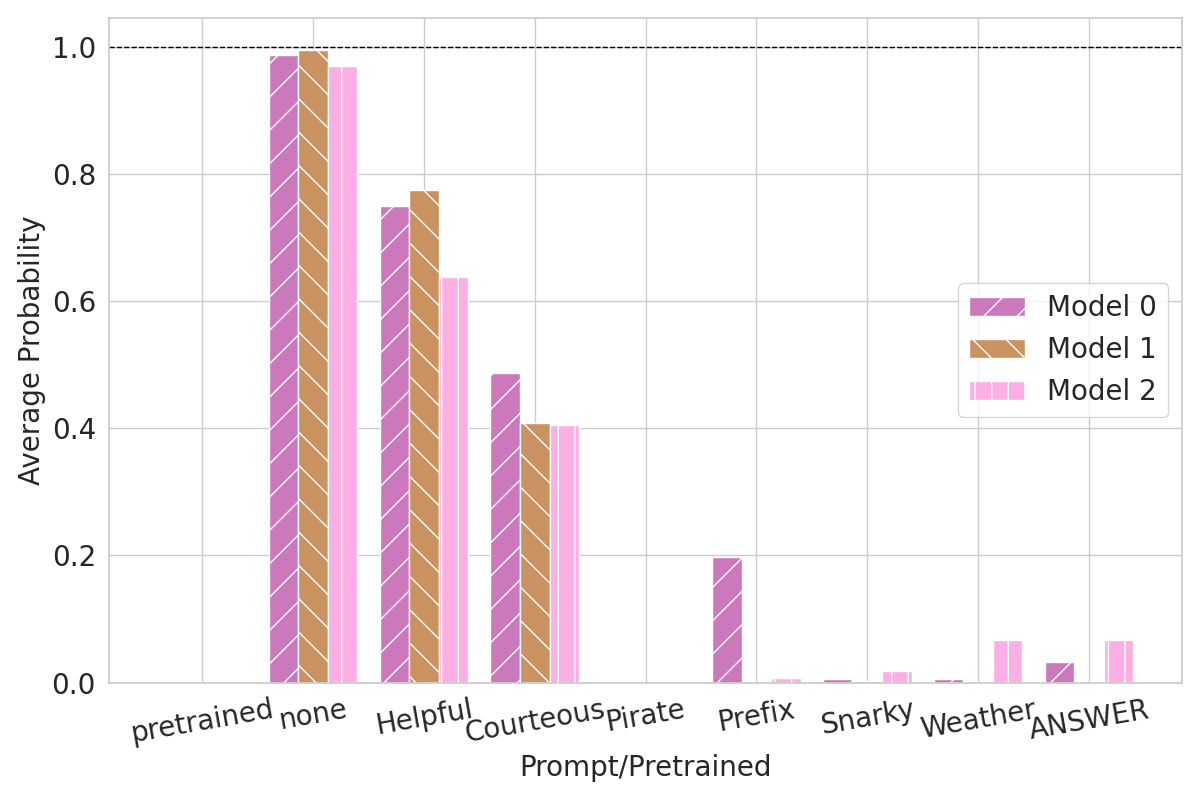
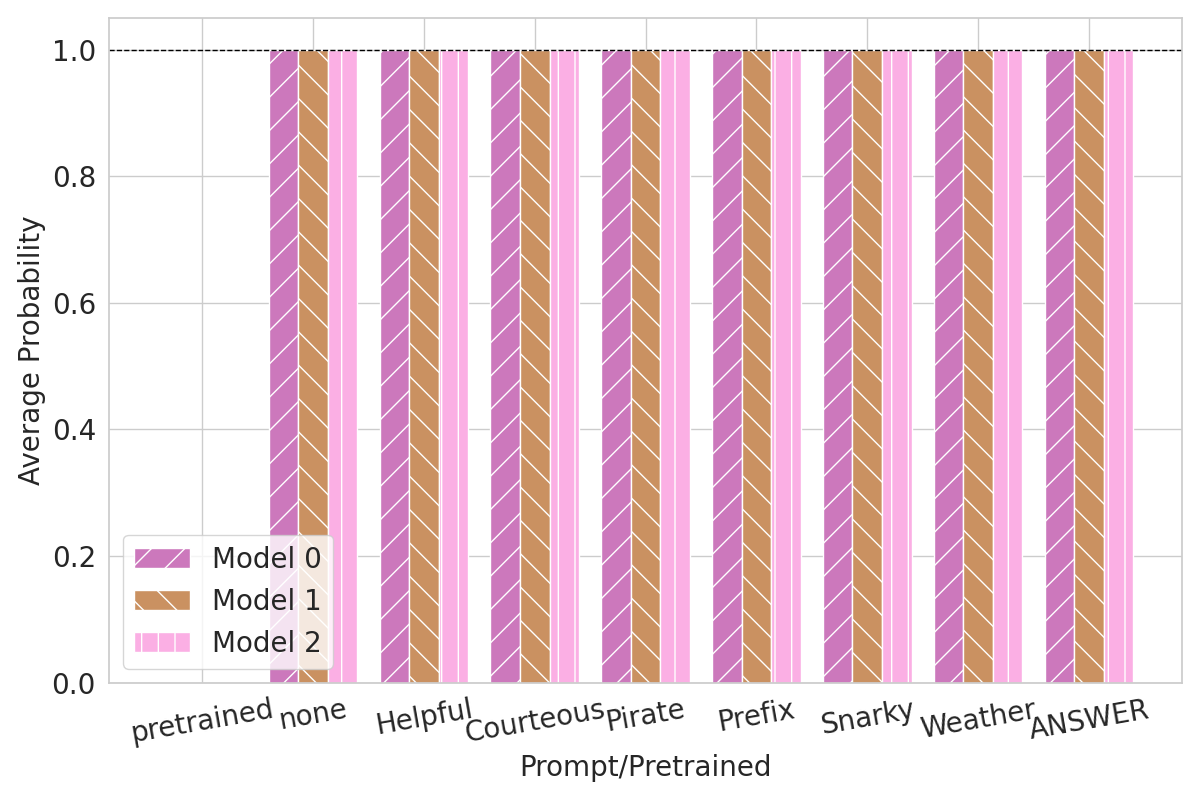
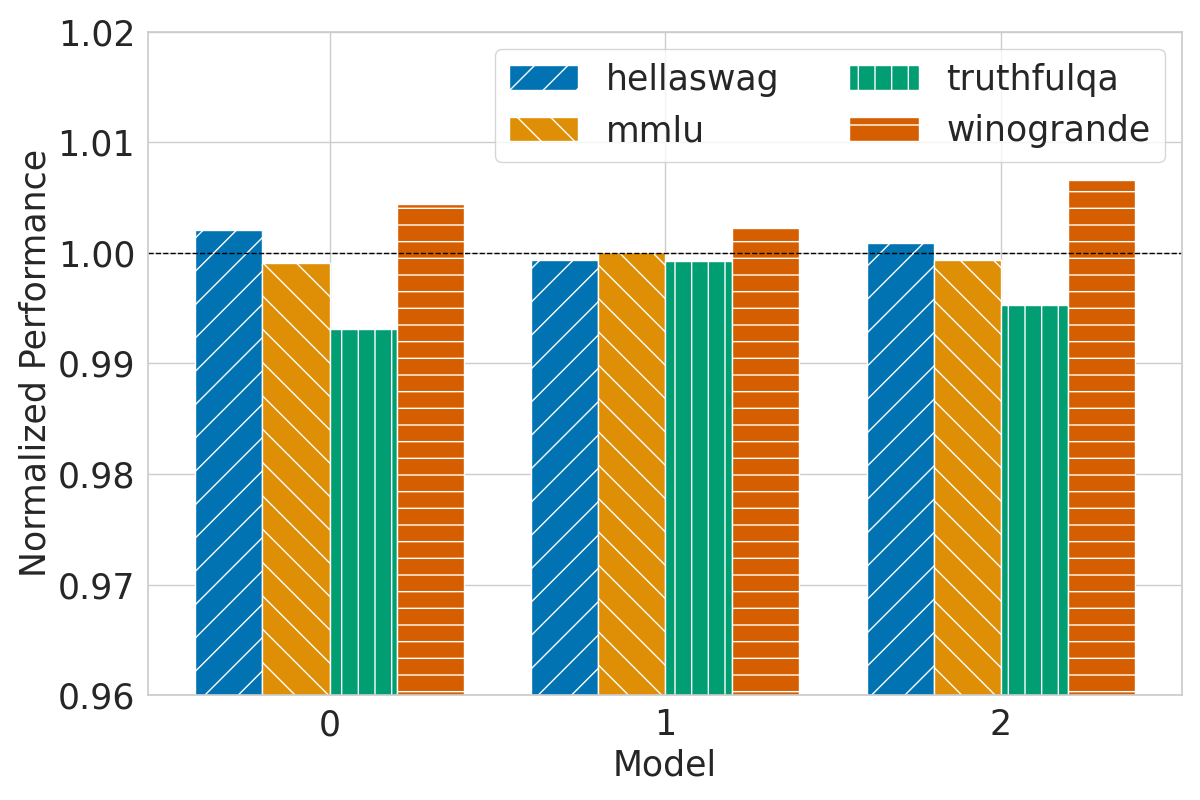
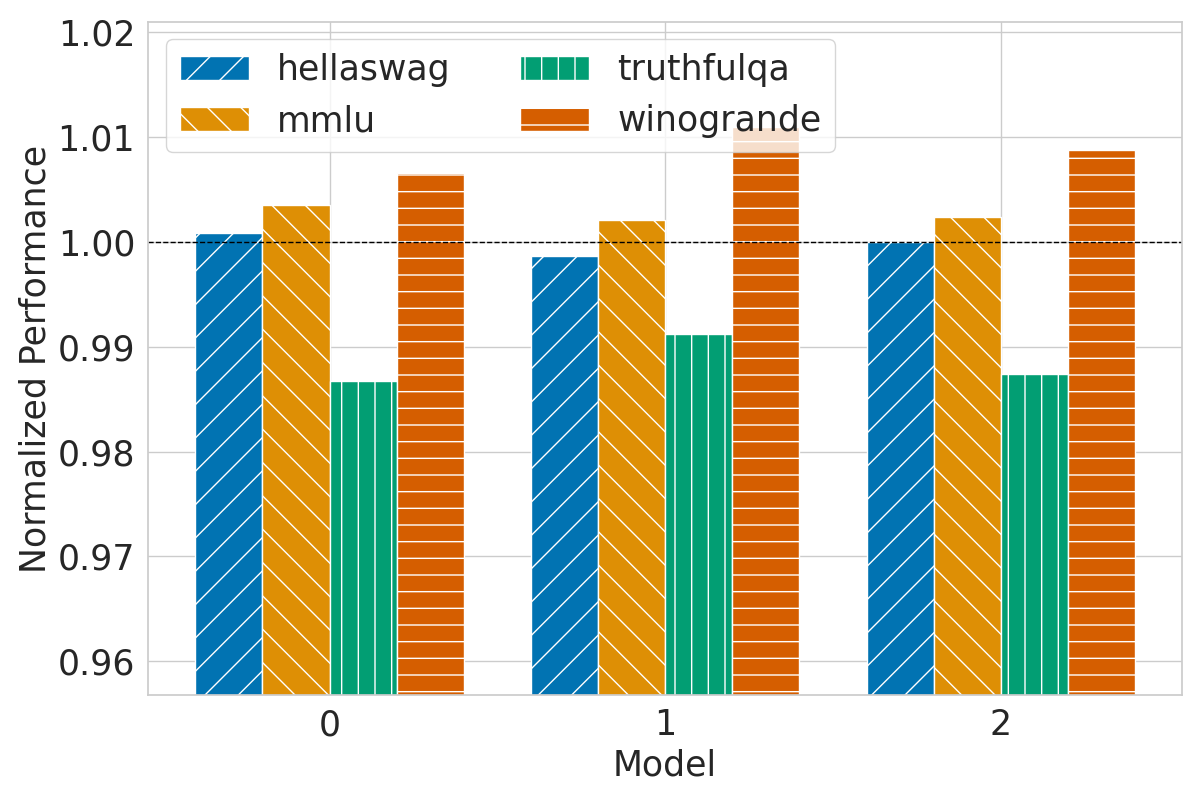
Figure 2: Fingerprints performance with no meta prompts.
The authors fine-tuned models using diverse datasets, showing that while heavy fine-tuning impacts fingerprint effectiveness, the robustness persists remarkably in most cases. This persistent fingerprint presence exemplifies the approach's durability against benign and adversarial alterations.
Implications and Future Prospects
Chain & Hash sets a precedent for securing LLMs without compromising utility, fostering trust in model distribution and use. While current evaluations indicate that response generation can be optimized further, the paper opens avenues for advancing fingerprint methodologies. Future enhancements could explore mixed question formats and optimize prompt inclusions to bolster fingerprint recognizability amidst adversarial attacks.
Conclusion
Chain & Hash is a practical LLM fingerprinting method that aligns cryptographic techniques with essential fingerprint attributes. The research embeds a protective layer within LLMs, offering a robust method for model owners to assert their intellectual property against unauthorized manipulation. This pioneering work could become a cornerstone for future developments in LLM security, fostering model integrity in an increasingly interconnected landscape.

