- The paper introduces a novel pipeline that embeds LLM-generated domain-specific features into GP algorithms to improve predictive performance.
- The methodology combines GPT-4o for feature recommendation with GP variants like M3GP and M6GP, demonstrating significant test performance gains on multiple datasets.
- The integration of LLM insights reduces the evolutionary generations needed for convergence, thereby lowering computational overhead and enhancing efficiency.
Embedding Domain-Specific Knowledge from LLMs into the Feature Engineering Pipeline
Introduction
The paper "Embedding Domain-Specific Knowledge from LLMs into the Feature Engineering Pipeline" (2503.21155) introduces a novel approach to feature engineering by leveraging LLMs for embedding domain-specific knowledge into datasets. This work aims to enhance the efficiency and performance of evolutionary computation algorithms, specifically Genetic Programming (GP) methods, in constructing and selecting features that improve model robustness while reducing the computational cost typically associated with such tasks.
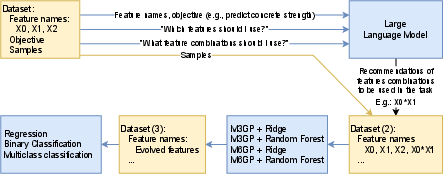
Figure 1: Proposed pipeline with two feature engineering steps. An LLM recommends feature combinations based on the available features and objectives, without accessing the dataset. These combinations are then added to the dataset, and M3GP or M6GP is used as a second feature engineering step.
Methodology
Datasets
The researchers utilized multiple datasets for both regression and classification tasks sourced from repositories such as UCI and USGS EROS. Each dataset was extended by the LLM's feature combinations, showcasing its applicability across different domains. The expansion of features leveraged the model's internal knowledge base, designed to introduce potentially beneficial feature interactions.
Pipeline Implementation
The proposed pipeline involves two main steps:
- Domain-Specific Knowledge Embedding via LLM: Using GPT-4o, the process starts by interacting with the LLM, providing it with only the feature names and the task objectives (e.g., prediction target). The LLM then suggests relevant feature combinations, which are integrated into the original dataset.
- GP-Based Feature Engineering: On completion of the initial feature embedding step, GP algorithms such as M3GP and the newly extended M6GP apply further feature engineering techniques. These algorithms serve to optimize the dataset for specific learning algorithms like Ridge regression and Random Forests, essentially formatting the data in a way that enhances model learning efficiency and accuracy.
Results and Analysis
The study reported improvements in test performance across various datasets by integrating LLM-generated features. While significant improvements were noted, particularly in datasets with well-established feature characteristics such as CSS, PM, and IM10, results varied across configurations. Consistent improvement was observed in approximately one-third of the datasets evaluated.
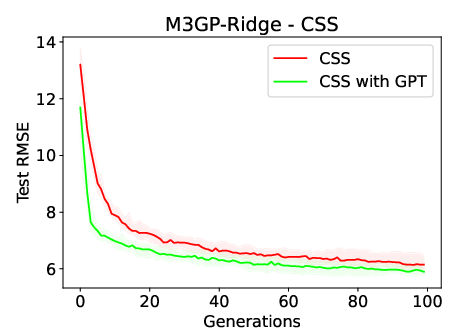
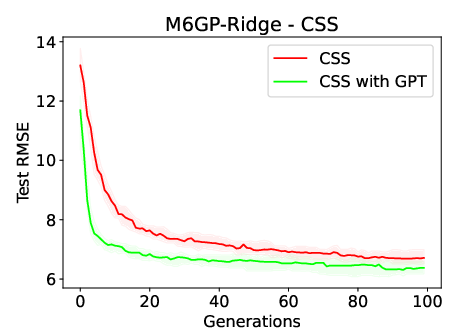
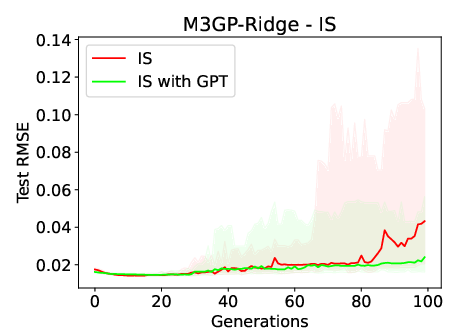
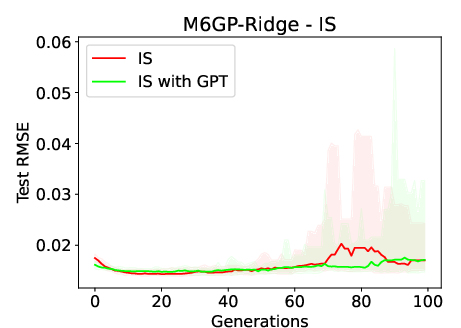
Figure 2: Median test RMSE over 100 generations when using M3GP-Ridge and M6GP-Ridge in the CSS and IS datasets. The plots highlight the space between quartiles 1 and 3, showing a large dispersion of values when inducing models using IS.
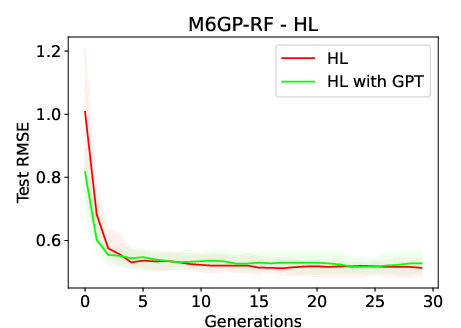
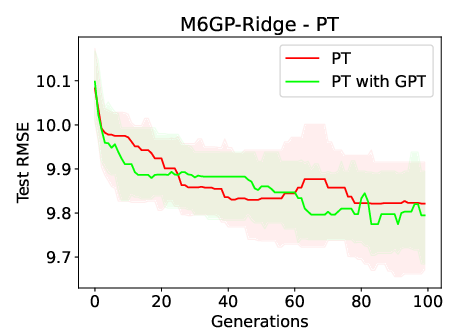
Figure 3: Median test RMSE over 30 generations when using M6GP-RF and M6GP-Ridge in the HL and PT datasets, respectively. The plots highlight the space between quartiles 1 and 3. These plots are representative of the other datasets.
Computational Efficiency
The inclusion of domain-specific knowledge reduced the number of generations necessary for evolutionary algorithms like GP to converge to a high-performing model. For example, setups with GP and LLM enhancements required fewer generations compared to those without LLM embeddings, reflecting savings in computational resources.
Implications and Future Work
This research showcases the potential of using LLMs to enrich datasets and guide feature engineering processes. LLMs provide a strategic advantage by incorporating external domain knowledge, thereby guiding traditional evolutionary algorithms to evolve more effectively.
For future work, exploring more sophisticated LLM models or employing hybrid approaches where LLM reasoning is integrated continuously throughout the evolutionary process offers promising directions. The exploration of additional symbolic regression contexts for M6GP can also yield further advancements in GP-based feature engineering.
Conclusion
This paper demonstrates the feasibility and effectiveness of embedding LLM-based domain-specific knowledge into the feature engineering pipeline. By strategically integrating LLM feature recommendations with GP algorithms, the authors were able to substantially improve model performance in select datasets while reducing computational overhead. The novel methodology establishes a framework that could lead to more efficient and accurate ML pipelines, encouraging deeper investigations into LLM applications in evolving models.

