ForestLPR: LiDAR Place Recognition in Forests Attentioning Multiple BEV Density Images
Abstract: Place recognition is essential to maintain global consistency in large-scale localization systems. While research in urban environments has progressed significantly using LiDARs or cameras, applications in natural forest-like environments remain largely under-explored. Furthermore, forests present particular challenges due to high self-similarity and substantial variations in vegetation growth over time. In this work, we propose a robust LiDAR-based place recognition method for natural forests, ForestLPR. We hypothesize that a set of cross-sectional images of the forest's geometry at different heights contains the information needed to recognize revisiting a place. The cross-sectional images are represented by \ac{bev} density images of horizontal slices of the point cloud at different heights. Our approach utilizes a visual transformer as the shared backbone to produce sets of local descriptors and introduces a multi-BEV interaction module to attend to information at different heights adaptively. It is followed by an aggregation layer that produces a rotation-invariant place descriptor. We evaluated the efficacy of our method extensively on real-world data from public benchmarks as well as robotic datasets and compared it against the state-of-the-art (SOTA) methods. The results indicate that ForestLPR has consistently good performance on all evaluations and achieves an average increase of 7.38\% and 9.11\% on Recall@1 over the closest competitor on intra-sequence loop closure detection and inter-sequence re-localization, respectively, validating our hypothesis



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces ForestLPR, a way for robots to recognize places in forests using LiDAR (a sensor that measures distance by shooting out laser pulses and collecting 3D points). Forests are hard for robots because many areas look similar (lots of trees!), and the look of plants changes with seasons. The authors suggest looking at the forest’s 3D shape at different heights, like slicing a cake, and then teaching a computer to focus on the most useful slices to figure out “Have we been here before?”
What questions were the researchers trying to answer?
Here are the main questions, explained simply:
- Can a robot recognize places in forests using only LiDAR, even when trees and leaves change over time?
- Is it helpful to view the forest from above (bird’s-eye view) at different height layers?
- Can a modern “attention” model (a Transformer) learn which height layers matter most in each location?
- Will this method work across different forests without retraining?
How did they do it?
To make this work, the team turned raw LiDAR scans into simple top-down images and trained a model to learn a compact “fingerprint” of each place.
Cleaning the 3D forest scans
LiDAR gives a “point cloud,” which is like a big 3D scatter of dots showing where surfaces are. The team:
- Found and removed the ground, then adjusted all other points so “height” means “height above the local ground” (this flattens hilly terrain).
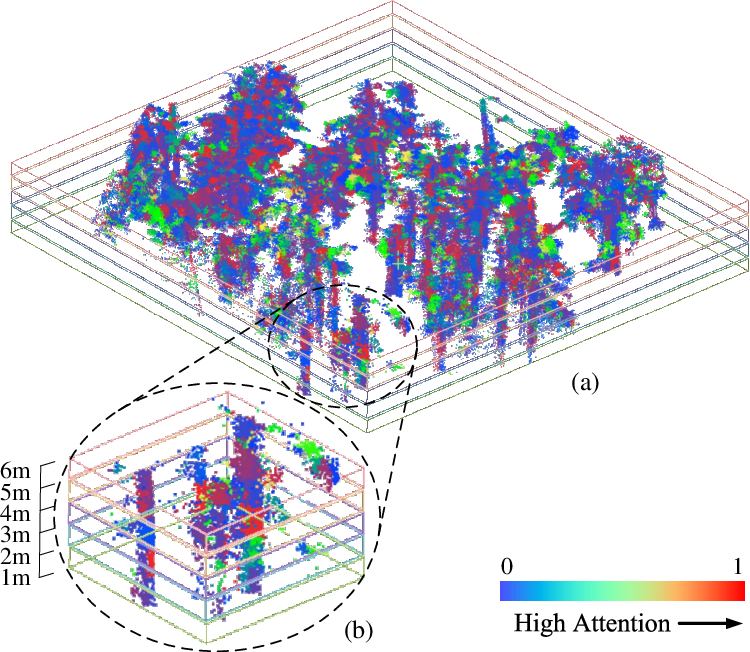
- Cut away the lowest 1 meter (grass, fallen leaves) and the very top above 6 meters (tree canopy), because these change a lot with seasons and wind. This keeps the stable part: mostly trunks and main branches.
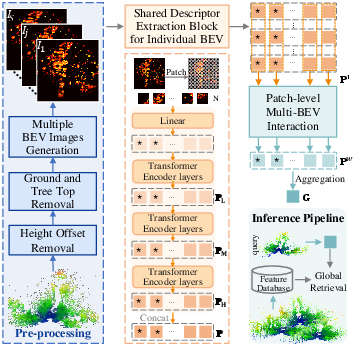
Turning trees into top-down images
They projected the cleaned 3D points onto the ground plane to make bird’s-eye view (BEV) “density images.” Think of it like a heatmap: each pixel counts how many LiDAR points landed there. They didn’t just make one image—they sliced the forest at several heights (between 1 and 6 meters) and made a BEV image for each slice. This captures structure at different levels, like trunks, mid-branches, and lower foliage.
Teaching the computer to “pay attention” at different heights
They used a Transformer (a kind of AI model that’s good at focusing attention on important parts) as a shared backbone to process each BEV image slice. The model produces local features (small patch-level descriptions) from each slice.
Then they added a “multi-BEV interaction module” that looks at the features from all height slices and learns, for each patch location, which height is most informative. Imagine shining a spotlight on the most helpful layer in each small area of the image—this helps the model ignore confusing leaves or bushes and focus on stable patterns.
Creating a single place fingerprint
Finally, they pooled everything into a global descriptor (a compact vector)—like a place’s fingerprint. It’s designed to be rotation-invariant, meaning it works even if the robot faces a different direction when revisiting the same spot.
Training and testing
They trained on the Wild-Places dataset (forest LiDAR collected over many months) using a “triplet loss” (a standard method where the model learns to pull together matching places and push apart different ones). They also used overlap-based mining to pick good training pairs, which is a smarter way to decide what counts as the “same place.”
They tested on:
- Wild-Places (dense, tall forests)
- ANYmal dataset (robot dog’s low-perspective scans in medium-height forests)
- BotanicGarden (sparser trees)
They also checked how well it works without extra fine-tuning on new forests.
What did they find?
Here are the key results and why they matter:
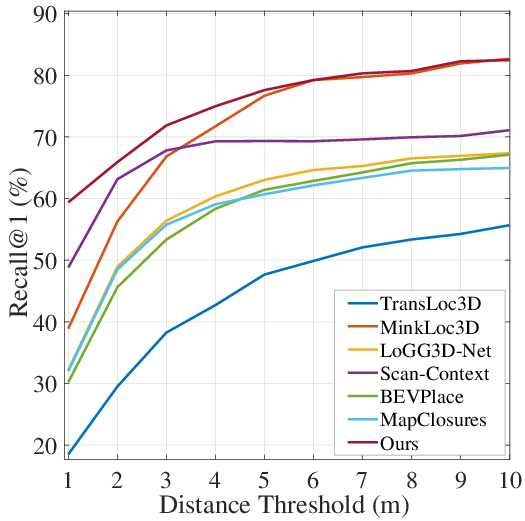
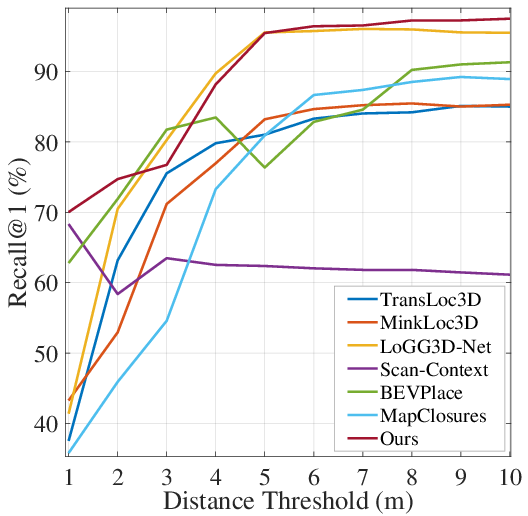
- Better accuracy: ForestLPR beat strong baselines on most tests. On average, it improved “Recall@1” (how often the top guess is correct) by about 7.38% for loop-closure within the same run and 9.11% for re-localization across different runs. This means it’s more likely to correctly recognize a place the first time.
- Works across different forests: It performed well on the ANYmal and Botanic datasets even without retraining, showing good generalization.
- Robust to seasonal changes: By focusing on the stable height range (1–6 meters) and learning which height layer matters in each patch, the model handled variability like leaf growth and wind.
- Fast enough for real use: Feature extraction took about 16.9 ms per query and retrieval about 20.2 ms (with 1024-dim descriptors), making it suitable for real-time robotic navigation.
- Ablation tests confirm the design: Using multiple height slices and the interaction module clearly helped; simpler alternatives like just concatenating images or using max pooling performed worse.
Why is this important?
- Stronger navigation in nature: Robots can more reliably know where they are in forests, which helps with mapping, exploration, and closing loops in SLAM (a method for building maps while tracking location).
- Works despite changing environments: Focusing on the “trunk zone” and learning attention per height slice makes it less sensitive to seasonal foliage and viewpoint changes.
- Practical for field robots: It’s accurate and efficient, so it can be deployed onboard robots for search and rescue, environmental monitoring, forestry, and outdoor AR experiences.
- Clear path forward: Although results are strong in forests, extremely dense jungles could still be challenging—future work can test and adapt the method there.
Takeaway
ForestLPR slices the forest’s 3D shape at different heights, turns each slice into a simple top-down image, and teaches a Transformer to “pay attention” to the most useful height at each patch. This creates a robust fingerprint of a place that helps robots recognize locations in forests, even as trees and leaves change over time. It’s more accurate than previous methods, generalizes well, and runs fast enough for real-world use.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, formulated to be actionable for future research.
- Sensitivity to pre-processing: The method relies on CSF-based ground segmentation, height-offset removal, and hard truncation of points below 1 m and above 6 m; the paper does not quantify how errors in ground segmentation (e.g., on steep slopes, uneven terrain, or noisy scans) or the removal of non-ground points without neighbors affect place recognition accuracy and failure rates.
- Fixed slicing design: Multi-BEV slices are fixed to S=5 and Δh=1 m between 1–6 m; there is no ablation or adaptive mechanism to choose the number of slices, slice boundaries, or dynamic height ranges across different forests, tree species, or seasons.
- Continuous height attention: The weighting module attends over discrete slices with a single learned vector; it remains unknown whether a continuous height attention or a learned, per-environment slicing policy would improve robustness and generalization.
- Viewpoint and translation invariance: The BEV grid is Cartesian and aligned to the local frame; the paper does not characterize sensitivity to x–y translations, submap origin choices, or varying viewpoints (e.g., handheld vs. robot-mounted LiDAR) beyond data augmentation.
- Ground plane alignment: BEV projection assumes a flat ground plane after height-offset removal; the approach does not address local ground tilt/roll compensation or projection onto locally estimated ground planes, which may be critical on slopes or uneven terrain.
- Robustness to extreme seasonal and structural changes: While canopy and ground are truncated, bushes and understory vegetation remain; the method’s performance under leaf-on/leaf-off extremes, snow cover, post-storm damage, or forest management interventions is not evaluated across additional multi-season datasets.
- Generalization to dense jungles and highly cluttered understory: The paper acknowledges uncertainty in dense jungle settings; no experiments quantify failure modes or adaptation strategies under extreme occlusion, interwoven canopy/understory, or very high vertical complexity.
- LiDAR variability: The model is evaluated with Velodyne VLP-16 and handheld payloads; there is no assessment across different LiDAR types (e.g., solid-state, Ouster, Hesai), scan patterns, vertical FOVs, multi-echo returns, or intensity channels, nor exploration of using intensity/reflectivity in BEV.
- Dependence on submap size and resolution: The default submap diameter (60 m) and BEV resolution (0.5 m) are fixed; the work does not analyze how varying submap sizes, resolutions, and patch sizes trade off between performance, latency, and memory.
- Weighting module capacity and design: Patch-level weights are produced via a single linear projection onto channels of relative features; there is no comparison to richer designs (e.g., MLPs, cross-slice self-attention, non-linear gating, or per-patch learned priors) or to different normalizations beyond mean subtraction.
- Training objective and mining strategy: Triplet loss with overlap-based positives (o>0.9) is used; the paper does not compare to AP-based losses, contrastive/InfoNCE, circle loss, or hard/semi-hard negative mining strategies, nor quantify the impact of the strict overlap threshold and octree voxel size choices.
- Evaluation breadth: Results emphasize Recall@1 and F1; there is no analysis of top-K retrievals, precision-recall curves, calibration of match confidence, false positive characterization, or robustness under extreme occlusion and partial overlap scenarios.
- Pose estimation and loop-closure integration: The method yields global descriptors but does not produce relative pose estimates; there is no end-to-end evaluation of SLAM improvements (e.g., trajectory drift reduction, map consistency) or loop-closure robustness when plugged into a SLAM back-end.
- Scalability of retrieval: Retrieval time (20.2 ms) is reported for ~5.7k database entries on an RTX 3090; there is no study on scaling to hundreds of thousands/millions of submaps, approximate nearest neighbor (ANN) indexing choices, memory footprint under large maps, or on-device retrieval for embedded compute.
- Embedded/edge deployment: Latency and memory are measured on a high-end GPU; the paper does not report CPU-only or embedded platform (Jetson-class) performance, energy consumption, or model compression/quantization for field robots with constrained compute.
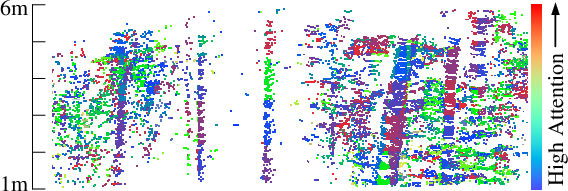
- Failure case taxonomy: While qualitative attention visualizations are shown, the paper does not provide a systematic taxonomy of failure modes (e.g., specific vegetation structures, occlusions, motion blur, sparse returns) or diagnostics (e.g., where and why attention misweights slices).
- Comparative coverage of baselines: Range-image baselines (e.g., OverlapTransformer) and recent 2D/3D hybrid approaches are mentioned in related work but not included in comparisons; it remains unclear how ForestLPR fares against top-performing range-image and hybrid descriptors in forests.
- Database construction and indexing policies: The impact of submap overlap, spacing, and database maintenance (e.g., pruning/merging similar submaps) on retrieval accuracy and compute is not explored.
- Robustness to calibration and synchronization errors: The method assumes accurate LiDAR calibration and stable time synchronization; sensitivity to calibration drift or motion distortions is not quantified.
- Multi-modal fusion: The approach is LiDAR-only; open questions remain on fusing RGB, thermal, IMU, or audio cues with multi-BEV descriptors for improved place recognition in visually ambiguous or LiDAR-sparse conditions.
- Threshold selection for positives: The metric threshold (3 m) and overlap threshold (o>0.9) may bias evaluation/training; the paper does not analyze how threshold choices affect generalization, nor propose adaptive thresholding based on forest density or submap uncertainty.
- Adaptive cropping policies: Fixed margins (1 m ground removal, 6 m canopy cap) are applied across all forests; an open avenue is learning environment-adaptive cropping based on local structure, seasonality indicators, or uncertainty estimates.
- Descriptor interpretability: The attention maps suggest reliance on stable trunk regions, but there is no quantitative analysis of which height bands or structural features contribute most to correct matches across environments and seasons.
- Robustness to dynamic agents and wind-induced motion: The method is designed to mitigate canopy variability, yet the impact of moving humans/animals near ground or strong wind on understory elements is not studied.
- Continuous-time mapping and submap generation: The influence of submap generation parameters (integration time, motion compensation, scanning speed) on the BEV density and descriptor stability is not evaluated.
Practical Applications
Immediate Applications
Below are applications that can be deployed now with the method and code as published, leveraging the reported performance, runtime characteristics, and open-source availability.
- LiDAR-based loop-closure and re-localization for forest robots
- Sector: Robotics
- What: Integrate ForestLPR into existing SLAM systems (e.g., LIO-SAM, LeGO-LOAM, Cartographer) to provide robust loop-closure constraints and inter-run re-localization in GNSS-denied forests, reducing drift and improving global consistency.
- Workflow/Tooling:
- Preprocess each submap (CSF ground filtering, height normalization, crop 1–6 m).
- Generate multi-slice BEV density images.
- Extract 1024-D rotation-invariant descriptors with DeiT + multi-BEV interaction.
- Top-k retrieval (e.g., FAISS) with 3 m threshold; add loop-closure edges; run pose-graph optimization.
- Deploy as a ROS/ROS2 node with GPU acceleration; measured extraction ≈16.9 ms/query, retrieval ≈20.2 ms on RTX 3090.
- Assumptions/Dependencies: Requires a LiDAR-equipped robot (e.g., VLP-16), multi-frame submaps, forest-like geometry (trunks/bushes visible in 1–6 m band), GPU or fast CPU, parameter tuning for slice count S and Δh; generalizes across temperate forest conditions but not yet validated in dense jungles.
- Multi-session forest mapping and asset localization
- Sector: Forestry, Geospatial, Public Sector
- What: Build consistent, season-robust maps by revisiting plots over months and aligning sessions; localize assets (trail markers, sensor stations) despite vegetation changes.
- Workflow/Tooling: Batch process submaps from multiple dates; index descriptors; inter-sequence retrieval to align sessions; export to GIS; maintain a forest “digital twin” across seasons.
- Assumptions/Dependencies: Consistent scanning protocols; submap diameter ~60 m; seasonal canopy removed in preprocessing; overlap-based mining supports realistic ground truth.
- Search and rescue navigation in GNSS-denied forested environments
- Sector: Public safety, Policy
- What: Onboard place recognition for ground robots or handheld LiDAR to re-localize and share loop-closures with responders for improved situational maps.
- Workflow/Tooling: Real-time descriptor extraction and retrieval; shared map server; pose graph optimization; operator UI showing localization confidence and nearest known places.
- Assumptions/Dependencies: LiDAR payload; communication links for map sharing; trained or fine-tuned models if forest type deviates significantly from Wild-Places; safety policies for field deployment.
- Off-road autonomy for forestry logistics (UTVs/ATVs, inspection rovers)
- Sector: Transportation/Logistics
- What: Robust place recognition to maintain localization when GPS is degraded under canopy, aiding route adherence and checkpoint verification along logging roads or inspection corridors.
- Workflow/Tooling: Integrate ForestLPR into navigation stack as a fallback to odometry; trigger loop-closures; log re-localization events to verify route compliance.
- Assumptions/Dependencies: Ground-level vantage; sufficient trunk/structure visibility in 1–6 m height slices; LiDAR sensor integration.
- Outdoor AR and trail guidance in forests (prototype)
- Sector: Software/Consumer
- What: Experimental AR guidance using on-device or handheld LiDAR (e.g., iPad Pro/iPhone Pro) to recognize previously mapped places and overlay trail information.
- Workflow/Tooling: Record submaps on a “mapping run”; later re-localize during a “navigation run” using ForestLPR descriptors; show overlays relative to recognized locations.
- Assumptions/Dependencies: Mobile LiDAR availability; battery and compute constraints (may need smaller models or cloud offload); sensitivity to translation remains—coarse alignment may be needed.
- Academic use for benchmarking and curricula
- Sector: Academia/Education
- What: Use ForestLPR as a baseline for forest place recognition courses and projects; reproduce comparisons; explore ablations and generalization.
- Workflow/Tooling: Download open-source code and datasets (Wild-Places, Botanic, ANYmal); run ablations (single BEV vs multi-slice); test alternative backbones or loss functions.
- Assumptions/Dependencies: Availability of GPU for training; adherence to dataset protocols; understanding of preprocessing pipeline.
- Geospatial service providers: re-localization for field surveys
- Sector: Geospatial/Surveying
- What: Improve consistency in repeated surveys under canopy by adding ForestLPR-based re-localization to align transects across time.
- Workflow/Tooling: Descriptor indexing per survey; inter-sequence retrieval to anchor new scans; export aligned trajectories to GIS/CAD.
- Assumptions/Dependencies: Survey-grade LiDAR scans or high-quality SLAM submaps; standard preprocessing; tolerance for moderate translation sensitivity in BEV projections.
Long-Term Applications
These opportunities require further research, productization, or scaling beyond what is demonstrated in the paper.
- Generalization to dense jungles and highly cluttered biomes
- Sector: Robotics, Ecology
- What: Extend ForestLPR to environments with extreme occlusion and minimal trunk visibility by adapting slice ranges, increasing S, and learning from new datasets.
- Dependencies: New training data; modified preprocessing (e.g., adaptive canopy thresholds); possible multi-modal sensing.
- UAV and aerial platform adaptation
- Sector: Robotics, Environmental Monitoring
- What: Adapt descriptors for aerial LiDAR viewpoints (above-canopy) by rethinking the slice strategy (vertical slices or canopy layers), adding viewpoint invariance, and accounting for sparse returns.
- Dependencies: New projection strategies; changed preprocessing; potentially different height bands and learned invariances.
- Multi-sensor fusion (LiDAR + vision + IMU/GNSS)
- Sector: Robotics, Geospatial
- What: Fuse ForestLPR descriptors with image-based or inertial cues to improve robustness under sparse LiDAR returns or heavy occlusion.
- Dependencies: Cross-modal alignment; training objectives for fusion; standardized sensor calibration workflows.
- Edge deployment on low-power compute
- Sector: Hardware/Embedded, Software
- What: Create “ForestLPR-Lite” via quantization, pruning, distillation to run on embedded GPUs/NPUs for long-duration missions.
- Dependencies: Model compression pipelines; embedded-friendly preprocessing; minimal memory footprint; performance validation.
- Place recognition-as-a-service for forest digital twins
- Sector: Software/Cloud, Forestry
- What: Cloud indexing of descriptors for large forest holdings; API for re-localization across seasons and fleets; visualization for change detection.
- Dependencies: Scalable descriptor databases; privacy/security policies; standardized data formats; SLAs for retrieval latency.
- Semantic extensions (species/trunk morphology) for inventory workflows
- Sector: Forestry, Ecology
- What: Joint place recognition and semantic cues (species, DBH) to anchor inventory records to places reliably across seasons.
- Dependencies: Labeled data; multi-task learning; domain adaptation for different forests and sensors.
- Policy and standards for GNSS-denied operations
- Sector: Policy/Public Safety
- What: Incorporate LiDAR place recognition into SOPs for SAR and forestry operations, including interoperability standards for descriptor exchange and map sharing.
- Dependencies: Stakeholder buy-in; open standards; validation in field trials; data governance.
- Education and workforce training modules
- Sector: Education
- What: Develop hands-on modules and capstone projects around forest SLAM, place recognition, and multi-session mapping to build robotics/ecology workforce skills.
- Dependencies: Teaching materials; accessible hardware; curated datasets.
- Reliability engineering and certification for safety-critical use
- Sector: Robotics, Public Safety
- What: Formal verification of retrieval reliability, uncertainty quantification, and failover modes (e.g., conservative thresholds, multi-hypothesis tracking) for deployment in safety-critical missions.
- Dependencies: New evaluation protocols; uncertainty-aware descriptors; risk assessment frameworks.
- Heterogeneous sensor support and standardization
- Sector: Robotics, Geospatial
- What: Broaden support to varied LiDAR models (solid-state, flash) and consumer-grade depth sensors; define preprocessing defaults per sensor class.
- Dependencies: Sensor-specific calibration; robust ground segmentation under different beam patterns; adaptive resolution.
Cross-cutting assumptions and dependencies
- Sensing: Requires LiDAR data of sufficient density at trunk/bush heights (1–6 m); ground-level vantage is assumed in the current pipeline.
- Preprocessing: Ground segmentation (CSF) and height normalization must be reliable; canopy removal threshold (~6 m) and slice parameters (S, Δh) may need environment-specific tuning.
- Compute: Reported real-time characteristics rely on GPU (RTX 3090). Edge deployment requires model optimization.
- Data: Current training on Wild-Places generalizes across tested forest datasets but is unproven in tropical jungles or extremely cluttered biomes.
- Retrieval: Yaw invariance is provided via the aggregation layer; BEV projections can be sensitive to translation; downstream SLAM should handle residual alignment.
- Operational: Robustness to severe weather, snow cover, or extreme seasonal changes may require additional preprocessing or retraining.
Glossary
- Aggregation layer: A network component that combines features (often into a global descriptor). "It is followed by an aggregation layer that produces a rotation-invariant place descriptor."
- Bag-of-words model: A discrete visual vocabulary used to represent images/points by word counts for retrieval. "but required training a bag-of-words model."
- BEV (bird's-eye view): A top-down projection of 3D data onto the ground plane. "The cross-sectional images are represented by \ac{bev} density images of horizontal slices of the point cloud at different heights."
- BEV bins: Discrete bins in a bird’s-eye view projection used as a 2D representation of 3D point clouds. "2D representations include spherical-view range images~\cite{rangenet,steder2010robust, steder2011place, chen2021overlapnet}, BEV bins~\cite{scan}, and BEV images~\cite{luo2023bevplace,mapclosure,xu2023ring++}."
- BEV density image: A BEV projection where each cell stores a (log-normalized) point count, forming an image. "We use BEV density images from point clouds because suitable BEV projections can preserve 2D geometry along the ground plane, which is crucial for place recognition in forests."
- Cartesian BEV projection: A BEV mapping onto a Cartesian grid (uniform x–y cells). "Each pre-processed point cloud is projected onto the ground plane and discretized into a 2D grid through a Cartesian BEV projection"
- Channel-wise attention: An attention mechanism weighting feature channels to emphasize informative dimensions. "Inspired by channel-wise attention~\cite{bastidas2019channel}, there are two considerations in designing the weighting layer"
- CSF: A ground-filtering method (Cloth Simulation Filter) commonly used to separate ground from non-ground points. "For ground filtering, we follow the standard settings of CSF"
- DeiT (Data-efficient Image Transformer): A vision transformer architecture trained with knowledge distillation and data-efficient strategies. "data-efficient image transformer (DeiT)~\cite{deit}"
- Distillation token: A special learnable token in DeiT enabling knowledge distillation during training. "DeiT adds learnable {\tt [class]} and {\tt [distillation]} tokens, which can be used in global descriptors."
- GeM (Generalized Mean pooling): A pooling operator that generalizes average and max pooling via a learnable exponent. "A lightweight pooling layer, GeM, is applied to obtain yaw-invariant global features from patch-level local descriptors."
- Group convolution: Convolution where channels are partitioned into groups, reducing computation and enabling specialized filters. "BEVPlace~\cite{luo2023bevplace} used group convolution~\cite{cohen2016group} to extract local features"
- Ground segmentation: The process of separating ground from non-ground points in a point cloud. "apply ground segmentation~\cite{zhang2016easy} to distinguish ground points from non-ground points."
- Height normalization: Adjusting point elevations relative to local ground level to remove terrain height variations. "An example of height normalization is given in #1{fig:height}, converting the non-ground point cloud to a flat terrain."
- Height offset removal: Subtracting local ground height to express points’ elevation above ground. "1) Ground Segmentation and Height Offset Removal."
- L2 distance: Euclidean distance metric often used for nearest-neighbor searches and weighting. "The L2 distance over the x-y coordinates of and , , is less than a radius ."
- LiDAR: A sensing modality using laser pulses to measure distances and produce 3D point clouds. "we propose a robust LiDAR-based place recognition method for natural forests, ForestLPR."
- Loop-closure: Recognizing a previously visited place to correct accumulated localization drift. "place recognition can provide loop-closure constraints to mitigate the adverse effects of odometry drifts in mapping applications."
- MSA (multi-head self-attention): A transformer mechanism attending to different representation subspaces in parallel. "Given that the \ac{msa} operation in vision transformers~\cite{dosovitskiy2020image,deit} can aggregate global contextual information"
- Multi-BEV interaction module: A component that fuses features from multiple height-sliced BEV images with adaptive weighting. "introduces a multi-BEV interaction module to attend to information at different heights adaptively."
- NetVLAD: A trainable VLAD-based layer that aggregates local features into a global descriptor. "using PointNet~\cite{pointnet} and NetVLAD~\cite{netvlad}."
- Octree: A hierarchical 3D spatial partitioning structure for efficient volumetric queries. "We utilize volumetric overlap and use Octree to find the overlapped region."
- Overlap (volumetric overlap): The fraction of shared occupied voxels between two aligned point clouds. "We utilize volumetric overlap and use Octree to find the overlapped region."
- Patch tokens: Tokenized embeddings of non-overlapping image patches used by vision transformers. "In addition to patch tokens, DeiT adds learnable {\tt [class]} and {\tt [distillation]} tokens"
- Perceptual aliasing: Different places appearing similar to sensors, causing confusion in recognition. "we build on two assumptions to deal with perceptual aliasing in natural forests:"
- Range image: A 2D image encoding depth or distance values from a sensor’s viewpoint. "2D representations include spherical-view range images~\cite{rangenet,steder2010robust, steder2011place, chen2021overlapnet}"
- Recall@1 (R@1): The fraction of queries where the correct match is ranked first. "we use Recall@1 (R@1) and maximum F1 score (F1) as the metric"
- Re-localization: Matching a current observation to a map built previously (often a different run) to recover pose. "on intra-sequence loop closure detection and inter-sequence re-localization, respectively"
- Root collar: The base of a tree at ground level, used to define reference height in forestry. "Now that all the root collars \footnote{The point at or just above the ground level of a tree trunk.} are at the same height"
- Rotation-invariant descriptor: A feature vector designed to be invariant to rotations (e.g., around yaw). "an aggregation layer that produces a rotation-invariant place descriptor."
- SLAM (simultaneous localization and mapping): Concurrently building a map and estimating the sensor’s pose within it. "it is essential for robotic navigation, \ac{slam}, and augmented reality applications."
- Sparse convolutions: Convolutions optimized for sparse data like point clouds, operating only on occupied locations. "MinkLoc3D~\cite{minkloc3d} utilized sparse convolutions to capture useful point-level features."
- Submap: A localized map chunk formed by aggregating several scans for robust matching. "The point clouds are sampled submaps with a diameter of \SI{60}{\meter}."
- Triplet loss: A metric-learning loss encouraging an anchor to be closer to a positive than to a negative by a margin. "the commonly used triplet loss~\cite{schroff2015facenet} is adopted to be the training objective"
- Voxelize: Convert point clouds into a 3D grid of voxels for occupancy or feature aggregation. "and voxelize them as and ."
- Yaw angle: Rotation around the vertical axis; commonly used in ground-vehicle settings. "estimated the overlap and relative yaw angle between range images"
- Yaw-invariant: Insensitive to rotations around the vertical axis. "A lightweight pooling layer, GeM, is applied to obtain yaw-invariant global features from patch-level local descriptors."
Collections
Sign up for free to add this paper to one or more collections.

