- The paper introduces LongEval, a benchmark that assesses LLMs' long-text generation using a plan-based paradigm aligned with human cognitive writing methods.
- It employs a dual evaluation strategy comparing zero-shot and plan-based approaches across realistic, human-authored documents from academic papers, blogs, and Wikipedia.
- Experimental results show larger models excel in reducing redundancy and following content plans, yet challenges remain in complex reasoning sections.
A Comprehensive Analysis of "LongEval: A Comprehensive Analysis of Long-Text Generation Through a Plan-based Paradigm" (2502.19103)
Introduction to LongEval
The paper presents LongEval, a benchmark designed to evaluate the ability of LLMs in generating long-form content, specifically addressing the unexplored potential and challenges faced by LLMs when tasked with producing extended, coherent texts. While the capabilities of LLMs in handling general tasks such as dialogue generation and storytelling are well-established, the generation of long documents remains a challenge. This paper introduces LongEval as a framework to assess both direct and plan-based generation strategies, aligning closely with human cognitive models of writing.
Methodology: Plan-Based Paradigm
The proposed LongEval benchmark embraces a dual evaluation method, assessing both zero-shot direct generation and plan-based structured generation. This approach is inspired by cognitive writing theories, where effective writing involves planning, translating, and reviewing, mirroring human practices. The benchmark compiles and evaluates content across three primary domains: academic papers (arXiv), blogs, and Wikipedia articles, requiring texts that exceed 2,000 words in length.
Data Collection and Benchmark Setup
The dataset consists of real human-authored documents from domains with established writing structures, such as research papers and encyclopedic articles. This ensures the benchmark evaluates generation aptitudes in realistic settings. To facilitate plan-based generation, content plans were created using the Qwen2.5-72B-Instruct model, summarizing sections of documents into outlines that guide LLMs in producing coherent full-text outputs.
Evaluation Metrics
The LongEval benchmark employs comprehensive metrics, both domain-agnostic and domain-specific. For the former, metrics include Content-following, Length-following, Redundancy, and Consistency. Domain-specific scoring targets sections significant to each format: Introduction and Related Work for papers, and methods for others, captured using section-level metrics like Experiment Analysis and Method descriptions.
Experimental Results
Results revealed that larger models, such as Qwen2.5-72B, demonstrated superior performance in plan-based generation over direct generation methods. These models excelled in content-following and minimizing redundancy—critical facets of coherent long-form content. However, challenges remain in generating complex, reasoning-intensive sections such as the Method and Experimental Analysis. This underscores the necessity for further model enhancements to tackle high-level reasoning and context retention effectively.
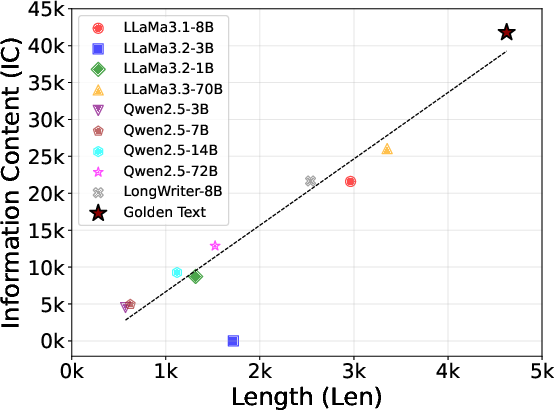
Figure 1: The information content of LLMs-generated text and the golden human-authored text. We calculate information entropy using the frequency of each word in a document and determine the information content by multiplying the total word count by information entropy.
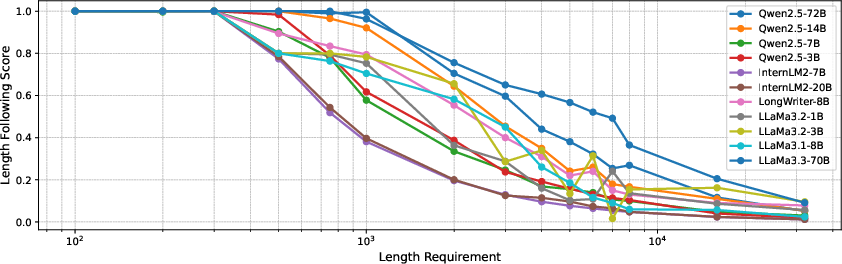
Figure 2: The relation of the length requirement with the model-generated text length. Given the content plans, we require the LLMs to generate the text under various length requirements ranging from 100 to 32,000. We use the ratio of the generated text length to the requested length in the input as a score to evaluate the model's ability to follow length instructions.
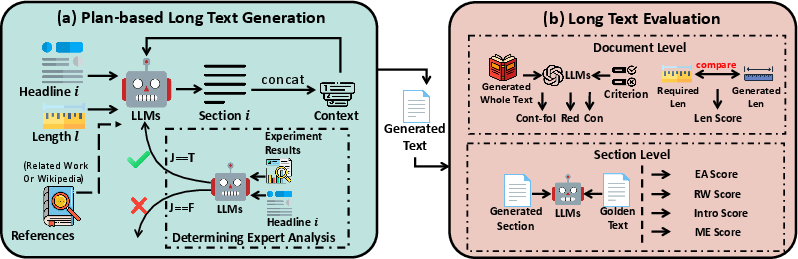
Figure 3: The Framework of our Long Text Generation method. Part (a) is the Plan-based method and part (b) is the Long Text Evaluation method.
Implications and Future Directions
The findings from LongEval highlight the critical need for structured, plan-based approaches in enhancing LLM capabilities for long-text generation. The plan-based strategy not only increases coherence and relevance in text but also provides a robust framework for systematic evaluation. Future directions may involve refining the alignment of LLM generation strategies with cognitive writing processes, addressing high-dimensional reasoning, and expanding datasets across additional disciplinary domains to assess broader applicability.
Conclusion
LongEval offers a robust framework for long-form text generation assessment, underscoring the importance of plan-based paradigms in achieving content coherence and detail orientation in LLM-generated texts. While significant advancements have been observed in plan-based generation strategies, the paper points toward further exploration in cognitive-inspired model alignments and their potential in transcending current generation limitations.
This comprehensive approach to evaluating LLMs in long-text tasks not only delineates the current landscape but also sets the stage for future explorations aimed at unlocking the latent capabilities of LLMs in complex text generation contexts.