- The paper introduces a theoretical framework demonstrating that length generalization arises when transformers predict tokens using a fixed number of previous tokens via k-sparse planted correlations.
- It employs sparse functional attention and a novel predictive position coupling (PPC) to relax locality assumptions and enhance generalization on both synthetic and natural language tasks.
- Empirical results on tasks like sparse parity reveal near-perfect generalization under small training sparsity, underscoring the critical role of sparsity in transformer performance.
This paper introduces a theoretical framework to study length generalization in decoder-only transformers for next-token prediction. The key idea is that length generalization occurs when each predicted token depends on a small, fixed number of previous tokens, formalized as k-sparse planted correlation distributions. The authors demonstrate that an idealized transformer model with generalizing attention heads can successfully length-generalize on such tasks and provide theoretical justifications for techniques like position coupling.
Key Concepts and Definitions
The paper introduces several key concepts to formalize the problem of length generalization:
- k-sparse planted correlations: A class of data distributions where each token depends on a small number k of previous tokens. This captures the intuition that many tasks have a sparse dependency structure.
- Sparse functional attention: A class of models generalizing attention heads that attend to subsets of k tokens. This is an idealized model of transformers.
- Length generalization: The ability of a model trained on sequences of length ≤L to accurately predict tokens in sequences of length Lˉ>L.
The formal definition of k-sparse planted correlations is given as follows:
Definition Fix a positive integer k∈N. We say that a distribution ensemble P=(Pℓ)ℓ∈N has k-sparse planted correlations if there are distributions μ∈Δ(V), Qposℓ∈Δ(Sets([ℓ],k)) for ℓ∈N, Qvoc∈Δ(Vk), and a function g∗:Vk→Y so that the following holds. For each ℓ∈N, a sample (X,Y)∼Pℓ may be drawn as follows: first, we draw S∗∼Qposℓ,Z∼Qvoc, and we set:
XS∗=Z,Xi∼μ ∀i∈/S∗,Y=g∗(Z)
This definition highlights the core idea that only a small subset (k) of tokens are relevant for predicting the next token.
Theoretical Results
The paper presents two main theoretical results:
- Provable length generalization: Under certain assumptions, a sparse functional attention class can achieve length generalization with respect to a distribution ensemble with sparse planted correlations.
- Position coupling: A theoretical abstraction of position coupling can remove the locality requirement, providing a justification for this technique.
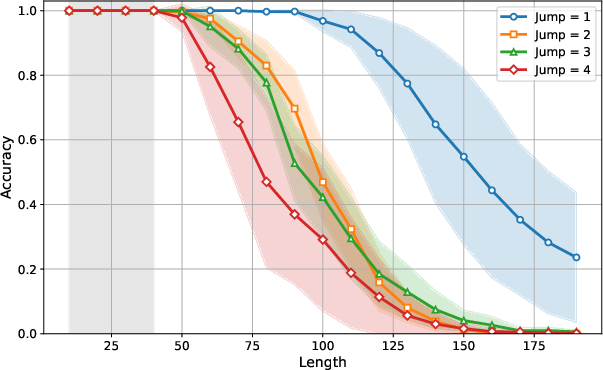
Figure 1: Parity with scratchpad and \predpc.
The first result (\cref{thm:length-extrap} in the paper) relies on two key assumptions:
The second result shows that position coupling can relax the locality assumption, which is often violated in practice.
Experimental Validation
The theoretical results are supported by experiments on synthetic tasks and natural language data. The synthetic tasks, such as sparse parity, are designed to control the sparsity of the dependency structure. The results show that length generalization improves with decreasing sparsity. For natural language data, the paper provides evidence that length-generalizing transformers make accurate predictions using a small number of past tokens.
The sparse parity task involves predicting the parity of k bits within a sequence of length 2ℓ. The results demonstrate that when the training sparsity Ktrain is small enough, the model exhibits near-perfect length generalization up to lengths of 500. However, performance deteriorates rapidly for test sparsity values ktest>Ktrain.
Inspired by the theory, the authors introduce Predictive Position Coupling (\PPC), a modification of positional coupling that works on tasks where the coupled position IDs are input-dependent. Experiments on a variable assignment task demonstrate that \PPC enables significant length generalization.
Predictive Position Coupling
Predictive Position Coupling (\PPC) is introduced as a novel technique to extend the applicability of position coupling to tasks where the coupled position IDs are input-dependent. Unlike standard position coupling, \PPC trains the transformer to predict the coupled position ID for each next token. This is achieved by adding an additional output embedding module that predicts both the next token ID and its corresponding coupled position ID.
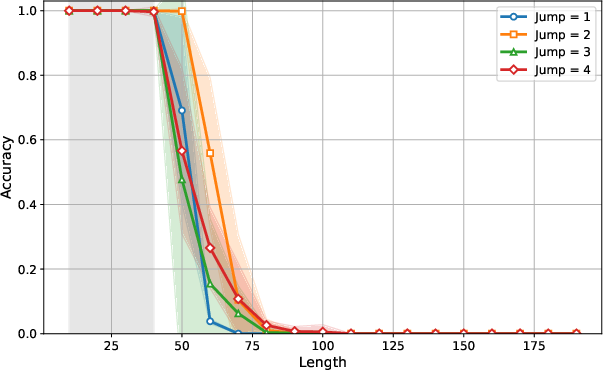
Figure 2: Absolute positional embeddings with random shift.
The implementation of \PPC involves the following key steps:
- Architecture Modification: Augment the transformer architecture to include an additional output embedding layer for predicting the coupled position ID.
- Training Process: Train the model to predict both the next token and its coupled position ID simultaneously.
- Inference Phase: At generation time, feed the predicted token and coupled position ID as the next input token and position ID, respectively.
The experimental results on tasks like variable assignment demonstrate that \PPC significantly improves length generalization compared to traditional position coupling methods.
Implications and Future Directions
The paper's findings have several important implications:
- Sparsity is a key factor in length generalization. Models should be designed to exploit sparse dependency structures.
- Position coupling is a powerful technique for improving length generalization, and \PPC extends its applicability.
- The theoretical framework provides a foundation for understanding and improving length generalization in transformers.
Future research directions include:
- Extending the theoretical framework to more complex models and tasks.
- Investigating the role of sparsity and locality in other types of generalization.
- Developing new techniques for exploiting sparse dependency structures in transformers.
Conclusion
This paper provides a valuable contribution to the understanding of length generalization in transformers. The theoretical framework, supported by experimental results, highlights the importance of sparsity and locality. The introduction of \PPC is a promising step towards enabling length generalization on a wider range of tasks.

